对DMU的效率进行衡量,首先要根据观测到的数据构造一个生产可能性前沿(也叫技术前沿),然后根据DMU的观测值与对应的生产可能性前沿上的值进行比较。本书第2章介绍了估算生产可能性前沿和效率值的数据包络分析法(DEA),DEA采用线性规划的方法,计算简单,而且无需知道生产函数的具体形式。本章中则介绍常用的效率评价的另一种方法——随机前沿分析法(SFA),与DEA不同,在对生产可能性前沿进行估计的时候,SFA需假定投入与产出之间的关系具有某个给定的函数形式,然后运用计量经济学的相关方法对待估参数进行估计从而确定生产可能性前沿,进而进行效率衡量。由于SFA确定的生产可能性前沿是生产函数的性质,因此适用于单一产出(或加总的产出)的情况,且在此基础上得到的技术效率是产出导向的。本章将对随机前沿分析方法及其在效率评估方面的运用进行系统的介绍。
对随机前沿生产函数模型的了解需要从通常的生产函数入手。按照萨缪尔森的定义,生产函数描述生产过程中一定的投入要素组合与其最大产出量之间的关系。但在实践中,由于一般无法得到最大产出量的样本观测值,只能用实际产出量作为样本观测值来估计生产函数模型。为将这种用实际产出作为样本观测值估计出来的生产函数与理论上的生产函数区别开,我们通常称前者为平均生产函数或均值生产函数,理论上所期望的描述一定投入要素组合与最大产出量之间关系的生产函数为前沿生产函数。
平均生产函数与边界生产函数的区别主要在于:对于平均生产函数,实际产出量可以在它的函数曲线上方,也可以在它的下方;而对于前沿生产函数,实际产出量不可能在它的上方,只能在它的下方。前沿生产函数实际上是平均生产函数向上的平移。正因为如此,前沿生产函数在比较不同样本点的技术效率方面具有重要的实用价值。在实践中,前沿生产函数常用于测算技术效率,即技术利用的程度。在技术水平不变的条件下,生产前沿上的最大产出是确定的,这时人们关心的往往是实际产出与生产前沿相差有多远,即技术效率。实际产出落在生产前沿上时,生产系统的技术效率为1;当实际产出落在生产前沿下面时,生产技术存在效率损失,技术效率小于1。
前沿生产函数法最早由Aigner和Chu两位学者于1968年提出。此后,前沿生产函数在几十年的发展过程中经历了两个阶段,即早期的确定性前沿生产函数和现在的随机前沿生产函数。
确定性前沿生产函数可以写成如下形式:
其中,x为投入向量,y为产出量的实际观测值,F(x)为确定性生产前沿。确定性生产前沿反映了特定技术和特定投入量下所能达到的最高产量水平,因此所有观测点都位于确定性生产前沿的下方或位于确定性生产前沿上。当观测点位于确定性生产前沿上时,表明该观测点的技术效率值为1,而一旦观测点位于确定性生产前沿的下方,则是由于技术非效率所致。
由技术效率的含义可知:
由于u≥0,0≤e-u≤1,因而e-u反映了生产的技术效率水平。由确定性前沿生产函数的模型设置可知,确定性前沿生产函数的一个重要特点是把影响产出量的不可控因素如观测误差、方程设定误差等和可控因素如生产非有效等因素不加区别,统统归入一个单侧的误差项中,作为对非效率的反映。
确定性前沿生产函数存在明显的缺陷:首先是对观测数据的误差比较敏感,稳定性较差;同时由于模型将影响经济单位的外生扰动因素也计入内生的技术无效当中,从而导致所测定的技术效率与真实的效率水平之间有很大偏差。
由于确定性前沿生产函数无法对随机因素和技术非效率进行区分,经济学家对此进行了进一步的探索,Aigner,Lovell和Schmidt(1977)提出了随机前沿生产函数,在确定性前沿生产函数的基础上又加入了反映对生产前沿随机影响的因素,随机前沿的函数形式如下式所示。
式中,F(x)×ev为随机生产前沿,其中ev为随机误差项,反映了模型设置误差、观测误差、随机冲击等因素对技术前沿的影响。而e-u表示技术效率,如下式所示:
因为此时模型中包含了影响技术前沿的随机因素,所以实际观测到的产出值y并不一定位于确定性生产前沿F(x)的下方,也有可能位于确定性生产前沿的上方,如图4.1所示。
图4.1 随机前沿
资料来源:黄镜如,付祖坛,黄美瑛.绩效评估——效率与生产力之理论与应用.新陆书局股份有限公司,1997:205
当vi>0时,表示该随机因素有利于生产,此时evi>1;当vi<0时,则表示该随机因素不利于生产,此时evi<1。在图4.1中,DMU(B)因为同时存在着一个较大的有利的随机因素vi和一个较小的无效率ui,所以vi-ui>0,从而随机因素和无效率因素对产出量的总的影响效果evi-ui>1,此时DMU(B)的产量位于确定性生产前沿F(x)的上方。随机因素并不总是有利于生产的,也有不利于生产的情况(如自然灾害等),此时![]() 则此时的产出量必定在确定性生产前沿的下方。还存在另外一种情况,随机因素对生产是有利的,但非效率的因素太大,以至于二者对生产的影响的总效应是不利的,即
则此时的产出量必定在确定性生产前沿的下方。还存在另外一种情况,随机因素对生产是有利的,但非效率的因素太大,以至于二者对生产的影响的总效应是不利的,即![]() 此时产量也会位于确定性生产前沿的下方。总之,实际产量与确定性生产前沿的相对位置取决于随机因素与非效率因素对生产的总影响效应。
此时产量也会位于确定性生产前沿的下方。总之,实际产量与确定性生产前沿的相对位置取决于随机因素与非效率因素对生产的总影响效应。
将式(4.2)左右两边取对数,可得到如下式子:
其中,ε≡vi-ui是组合误差,是随机因素与非效率因素的组合。vi是双边分布的随机误差项,即-∞≤vi≤+∞;而μi则为单边分布的随机误差项,即ui≥0。组合误差εi可能是正值也可能是负值,但在多数情况下是负值。
前面提到,SFA需要对生产函数的具体形式进行假设,生产函数有多种类型,在实际运用过程中,应根据所研究问题的具体情况选择最为合适的生产函数形式,常用的生产函数如表4.1所示。
表4.1 常用生产函数形式
资料来源:Coelli,T.,D.S.Prasada Rao and G.E.Battese.An Introduction to Efficiency and Productivity Analysis.Boston:Kluwer Academic Publishers,1998(2):211
表中所列的生产函数大多数关于参数都是线性的,其中柯布—道格拉斯生产函数和超越对数函数通过两边取对数的变换后也可以转化成关于参数的线性形式。
计量经济学中对于关于参数是线性关系的模型的估计方法主要有最小二乘估计法和最大似然估计法。而各种估计方法的使用都是建立在对随机性分布特征假设的基础之上。
与通常情况下的计量经济学模型不同,随机前沿生产函数的模型中包含两个随机误差项——双边分布的误差项vi和单边分布的误差项ui。对于这两个误差项的分布,通常假定vi与ui互相独立,并且两个误差项都与解释变量不相关。此外,一般假设vi和ui满足下列基本假设条件:
E(vivj)=0 对任意![]() =常数
=常数
E(uiuj)=0 对任意i≠j
在对参数进行估计的时候,需要在上面这些基本假设的基础上进行进一步的假设,对随机变量的不同的假定方式在对vi的分布假定上是一致的,一般假定![]() 而对于ui的分布的假定则有所区别,通常对ui的分布假设有以下几种:
而对于ui的分布的假定则有所区别,通常对ui的分布假设有以下几种:![]() (半正态分布)
(半正态分布)![]() (截断正态分布)
(截断正态分布)
ui~iidG(λ,0)(均值为λ的指数分布)
ui~iidG(λ,m)(均值为λ,自由度为m的gamma分布)
对随机变量设定什么样的假设,一方面取决于所研究问题的具体情况,另一方面依计算的便捷程度而定,本章将以半正态分布假定为例进行讨论。
在半正态分布的假定下,我们可以通过随机误差项vi和非效率误差项ui的分布特性来得到组合误差项εi的分布特性。
由于![]() 所以
所以![]()
由于![]() 我们可以得到:
我们可以得到:
而组合误差项εi≡vi-ui由于是正态分布和半正态分布的两个随机变量的代数和,因此在概率分布上具有偏态性,其各项统计指标分别为:
动差估计法(Moments Methods Estimation,MME)假设样本的动差与实际动差相等,进而得出随机变量实际方差的估计值。所谓动差,是对样本一些数据统计特性的统称,其中1级动差指平均数,2级动差指方差,3级动差指偏态性。动差估计法与OLS方法相结合则可以对具有两个随机变量的SFA模型的参数进行估计。为了对式(4.4)的参数进行估计,我们利用估计的残差值来仿效式(4.6)~式(4.8)所描述的组合误差项εi的动差特性,即平均数、方差和偏态性。
在这里,我们以柯布—道格拉斯生产函数形式的随机前沿生产函数为例进行说明。对随机前沿上生产函数两边取对数可得到如下式子:
![]() 所以在参数估计时直接使用OLS方法是不合适的。但是如果将组合误差项εi进行适当的调整,OLS方法还是可行的,调整过程如下:
所以在参数估计时直接使用OLS方法是不合适的。但是如果将组合误差项εi进行适当的调整,OLS方法还是可行的,调整过程如下:
调整之后,式(4.10)的随机误差项εi-E(εi)的三级动差分别为:
我们可以看到,式(4.10)的随机误差项的方差与偏态性均与调整之前的组合误差项的方差和偏态性相同,但均值为0。这样就可以运用OLS估计法,得到:
其中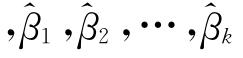 分别是
分别是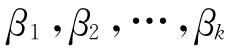 的无偏估计值,而^β0则是
的无偏估计值,而^β0则是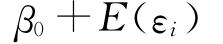 的估计值。若要得到β0的估计值,则需要在
的估计值。若要得到β0的估计值,则需要在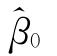 的基础上减去E
的基础上减去E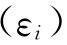 ),而E
),而E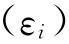 )的大小与
)的大小与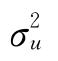 有关。接下来则可以用动差估计法来得到
有关。接下来则可以用动差估计法来得到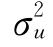 的估计值。由于ei是调整后的误差项εi-E(εi)的估计值,因此按照动差估计法的原则,我们认为ei的二、三级动差分别与εi-E(εi)的二、三级动差相等。
的估计值。由于ei是调整后的误差项εi-E(εi)的估计值,因此按照动差估计法的原则,我们认为ei的二、三级动差分别与εi-E(εi)的二、三级动差相等。
ei的方差(为写作方便,我们记作M2)![]()
ei的偏态性(我们记作M3)![]()
令M2和M3分别与式(4.12)和式(4.13)相等:
由式(4.17)和式(4.18)可得到![]() 及
及![]() 的估计值:
的估计值:
进而我们可以得到β0的估计值:
这种OLS与动差估计法相结合的估算方法易于使用,但是在运用上也存在一定的限制,当M3>0时,动差法可能无法求解出式(4.19)中的![]() 因为组合误差项必须具有负向偏态的特性,如式(4.8)所示。另外,若
因为组合误差项必须具有负向偏态的特性,如式(4.8)所示。另外,若![]() 则无法求出式(4.20)中的
则无法求出式(4.20)中的![]() 因为方差
因为方差![]() 必须为正。
必须为正。
最大似然估计法在参数估计方面具有一些优势,最大似然估计法不用考虑生产函数的具体形式,并且在样本足够大的情况下,得到的参数估计值具有一致性。最大似然估计法在计量经济学中应用广泛,也可以有效地避免动差估计法在SFA模型中的局限性。因此,我们将对最大似然估计法及其在SFA模型中的应用进行介绍。(www.daowen.com)
(1)最大似然估计法的介绍
最大似然(ML)估计法的概念是以下述思想为基础的,即一个特殊的观测值样本最有可能来自于某些分布,而不是来自于其他分布。例如,如果观测样本的均值是y=10.2,那么在其他情况相同的条件下,该样本最有可能是来自均值为10的分布,而不是来自均值为30的分布。因此,未知参数的最大似然估计值是能使得随机抽取的特殊样本观测值的概率最大化的参数值。
为了对最大似然估计法的原理进行说明,我们首先以普通的计量经济学模型为例进行分析,如下式所示:
其中,随机误差项vi是独立同分布的正态随机变量,即![]() 其均值为零,方差为
其均值为零,方差为![]() 由正态分布的性质可知:
由正态分布的性质可知:
得知了yi的分布类型,我们可以进一步将观测值向量y的联合密度函数写成如下形式:
这个联合密度函数称为似然函数(Likehood Function)。它将样本观测值的概率写成了关于未知参数β和σv2的函数。使用最大似然估计法估计待估参数就是通过求解β和σv2使得似然函数取最大值,因此可以用似然函数分别对β 和σv2求导并令导数为零:
求解式(4.25)和式(4.26)可得到待估参数β和σv2的估计值。等价地,还可以通过对似然函数的对数求解最大化来得到待估参数的估计值,对数似然函数如下式所示:
最大似然估计法在实际的研究工作中应用非常广泛,因为最大似然估计不用考虑所估计模型的类型,如果支持模型的假设是有效的,那么最大似然估计量具有大样本性质。可以证明,最大似然估计量具有一致性且渐进正态分布,并且其方差并不大于任何其他CAN估计量的方差。
(2)最大似然估计法用于随机前沿生产函数的估计
Aigner,Lovell和Schmidt(1977)在半正态分布的假定下用最大似然估计法对随机前沿生产函数进行了参数估计。为了使模型简化,Aigner,Lovell和Schmidt定义了两个参数σ2和λ2:
参数λ表示了非效率误差项u在组合误差项ε中的重要程度。若λ=0,则意味着![]() 且u=0,或者是
且u=0,或者是![]() 此时ε=v,不存在非效率,技术效率值为1。若λ→∞,则意味着
此时ε=v,不存在非效率,技术效率值为1。若λ→∞,则意味着![]() 且v→0,或者
且v→0,或者![]() 此时ε=u,则此时的随机前沿生产函数等同于确定前沿生产函数。
此时ε=u,则此时的随机前沿生产函数等同于确定前沿生产函数。
由于![]() 我们进而可以得到组合误差项ε的概率密度函数:
我们进而可以得到组合误差项ε的概率密度函数:
其中![]() 为在
为在![]() 点评估的标准正态分布函数。进而我们可以得到随机前沿生产函数的对数似然函数:
点评估的标准正态分布函数。进而我们可以得到随机前沿生产函数的对数似然函数:
为使对数似然函数值达到最大值,我们分别对β、σ2和λ求导并令导数为零:
求解式(4.31)~式(4.33)可得到参数β、σ2和λ的估计值。
前面介绍了随机前沿生产函数的概念以及对前沿生产函数参数的估计,求得了随机前沿生产函数,接下来就需要对技术效率的数值进行估计,对技术效率值的估计分为对单个DMU技术效率值的估计和对产业技术效率值的估计,而产业技术效率值可以定义为整个行业内所有单个DMU技术效率值的均值。本节将对技术效率预测的具体方法进行介绍,并对随机前沿生产函数的假设检验进行介绍。
对技术效率值的预测可以分为对特定BMU技术效率的预测和对产业技术效率的预测,所谓产业技术效率反映的是整个行业中所有DMU的综合技术效率表现,在实际操作中,用样本厂商技术效率值的平均值来表示。我们接下来将分别对两种技术效率值的预测进行介绍。
(1)特定DMU的效率
前面已经提到,第i个DMU的技术效率定义为![]() 本节将在半正态分布模型的基础上探讨技术效率的预测的问题。很显然,要预测第i个DMU的技术效率值,我们需要知道ui的取值。而通过前面介绍的参数估计方法,我们只能得到εi的估计值,因此对技术效率的估计需要进一步从εi中区分出ui。在得知了εi的信息的情况下,ui的分布可以表示为截断正态分布的概率密度函数形式:
本节将在半正态分布模型的基础上探讨技术效率的预测的问题。很显然,要预测第i个DMU的技术效率值,我们需要知道ui的取值。而通过前面介绍的参数估计方法,我们只能得到εi的估计值,因此对技术效率的估计需要进一步从εi中区分出ui。在得知了εi的信息的情况下,ui的分布可以表示为截断正态分布的概率密度函数形式:
其中![]() 得知了的概率密度函数,Jondrow(1982)在此基础上进一步求得了ui的期望以作为ui的估计值:
得知了的概率密度函数,Jondrow(1982)在此基础上进一步求得了ui的期望以作为ui的估计值:
其中φ(x)表示标准正态随机变量的概率密度函数在x处的值。Horrance和Schmidt(1995,1996)证明了在给定显著水平α下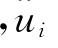 的置信区间为(Li,Ui)。
的置信区间为(Li,Ui)。
其中,
得知了ui的估计值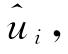 ,则第i个DMU的技术效率就显而易见了,即
,则第i个DMU的技术效率就显而易见了,即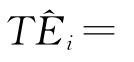
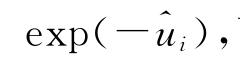 而在给定显著水平α下,技术效率估计值的置信区间为
而在给定显著水平α下,技术效率估计值的置信区间为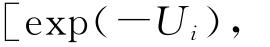
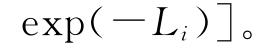
上述对特定DMU技术效率值进行预测的方法分为两个步骤,首先由ui的概率密度函数得到的ui估计值,然后再根据ui估计值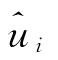 来计算技术效率的预测值。另外,Battese和Coelli(1988)也在ui的概率密度函数的基础上提出了特定厂商技术效率的估计方法,这种方法只有一个步骤,如下所示:
来计算技术效率的预测值。另外,Battese和Coelli(1988)也在ui的概率密度函数的基础上提出了特定厂商技术效率的估计方法,这种方法只有一个步骤,如下所示:
在给定显著水平α下,这种方法得到的技术效率估计值的置信区间仍然是(exp(-Ui),exp(-Li))。这里的Li与Ui的值分别由式(4.36)和式(4.37)求出。
(2)产业效率
产业效率指的是一个产业当中所有DMU的技术效率值的平均值。因此,在求得了个体DMU技术效率值的基础上,产业效率可以通过对样本中DMU的技术效率值求平均进而得到产业效率的估计值,如下式所示:
另外,产业效率也可以通过另外一种途径求得。在半正态分布的假设下,即ui~iidN+(0,σ2u)的条件下,我们可以得到ui的半正态分布概率密度函数:
得知了ui的概率密度函数,我们则可以通过求解ui的期望值来得到产业效率的估计值,如下所示:
在给定的显著水平α下,产业技术效率的预测区间为[exp(-U),exp(-L)],其中L=z0.5+α/4σu,U=z1-α/4σu。
在实践中,式(4.39)描述的方法应用得更为普遍,一方面操作较为简单,另一方面该方法更多地反映了样本数据所包含的信息。
对于随机误差项服从正态分布的计量模型,对待估参数β的假设检验有多种方法可以选择。常用的有t检验、F检验、似然比检验、Wald和拉格朗日橙子统计量检验。除了t检验和F检验,上述几种检验方式都是渐进合理的,只有当样本量很大的情况下,这几种检验才是可靠的。而在随机前沿模型中,由于组合误差项并不服从正态分布,因此,t检验和F检验也只是渐进合理,在小样本情况下,t检验和F检验的结果也是不可靠的。
在随机前沿模型的情况下,除了对待估参数β进行假设检验以外,还需要对非效率效应是否存在进行检验。当所有厂商都是有效率的,即效率值exp(-ui)时,非效率效应不存在,对应地,ui=0。因此在对非效率效应是否存在进行假设检验时,我们可以设定原假设为![]() 或者
或者![]() 如果接受原假设,则不存在非效率效应,如果拒绝原假设,则存在非效率效应。
如果接受原假设,则不存在非效率效应,如果拒绝原假设,则存在非效率效应。
(1)渐进正态分布检验
这里我们使用Aigner,Lovell和Schmidt(1977)提出的参数λ的原假设和备择假设:
检验统计量为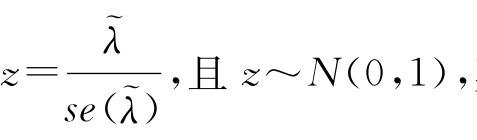 其中~λ表示ML估计,而se(~λ)则表示对λ的标准差的估计。
其中~λ表示ML估计,而se(~λ)则表示对λ的标准差的估计。
在给定显著水平α条件下,若z>z1-α,则拒绝原假设,非效率效应存在;若z<z1-α,则接受原假设,非效率效应不存在。
Coelli(1995)在研究中发现,上述z检验在小样本情况下具有欠佳的容量特征,即会过度倾向于拒绝原假设。另外,似然函数的数值最大化会使协方差矩阵的估计不可靠,一个直接的结果就是标准差的估计不可靠。在这一方面,概似比检验具有更为优良的特性,因而也得到了更为广泛的应用。
(2)概似比检验
我们仍然以统计量为例,原假设和备择假设仍然为:
H0:λ=0;H1:λ>0
概似比定义为![]() 其中分母L(λ=~λ)表示存在非效率效应情况下随机前沿生产函数的估计值,而分子L(λ=0)则表示不存在非效率效应情况下随机前沿生产函数的估计值。在这个概似比的基础上,我们可以建立如下检验统计量:
其中分母L(λ=~λ)表示存在非效率效应情况下随机前沿生产函数的估计值,而分子L(λ=0)则表示不存在非效率效应情况下随机前沿生产函数的估计值。在这个概似比的基础上,我们可以建立如下检验统计量:
该统计量服从自由度为1的混合χ2分布,该分布在显著水平α下的临界值为![]() 则拒绝原假设,存在非效率效应;若
则拒绝原假设,存在非效率效应;若![]() 则接受原假设,不存在非效率效应。
则接受原假设,不存在非效率效应。
[1]本章参考黄镜如,付祖坛,黄美瑛.绩效评估——效率与生产力之理论与应用.新陆书局股份有限公司,1997和Coelli,T.,D.S.Prasada Rao and G.E.Battese.An Introduction to Efficiency and Productivity Analysis.Boston:Kluwer Academic Publishers,1998(2)
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






