Kafka提供Partition级别的Replication是从0.8.∗开始的,Replication的数量参数可在$KAFKA_HOME/config/server.properties中进行配置]。由于Replication参数配置是Topic级别的配置项,进行配置时,需要在指定文件中添加,如添加default.replication.factor=3信息(默认值为1)。
Replication与Leader Election配合提供了自动的failover机制。Replication对Kafka的吞吐率是有一定影响的,但极大地增强了可用性。每个Partition都有一个唯一的Leader,Pro⁃ducer先通过Push方式将消费发送到Broker中的Leader Partition上,之后再通过异步的方式将消息Replication到Follower上。一般情况下,Partition的数量大于等于Broker的数量,并且所有Partition的Leader均匀分布在Broker上。因此Follower上的日志和其leader上的完全一样,Kafka Replication机制整体机构图如图14-3所示。
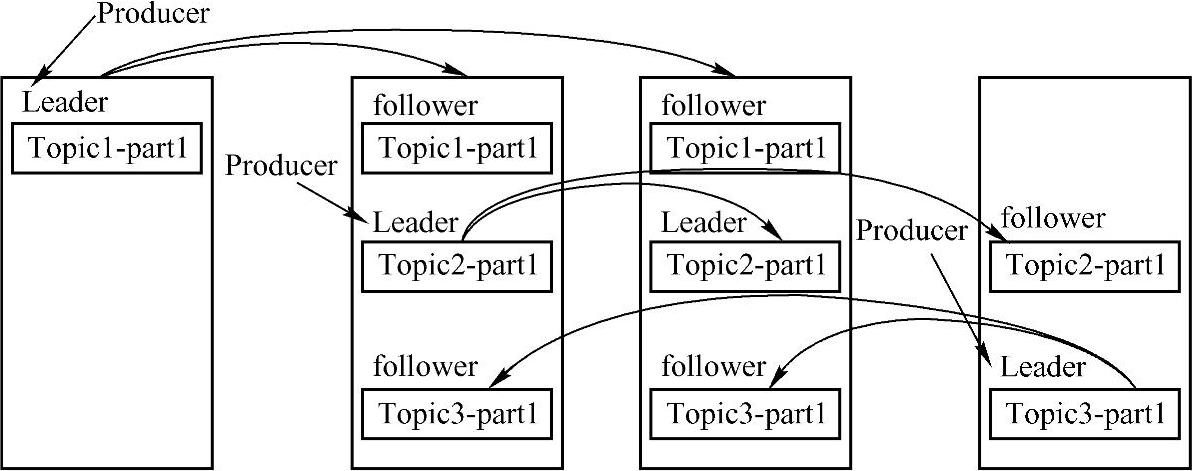
图14-3 Kafka Replication机制整体机构图
现在已经知道Kafka的Replication的大致情况,那么Broker中Partition中的Leader和Follower数据是怎样保持一致的呢?如果一个Broker宕机,怎样从其他的Follower中选取Leader呢?下面来分析这个问题。
和其他分布式消息系统一样,Kafka也有一套机制来判断Broker的存活情况,目前主要通过以下两种情况来判断,第一,Broker是否保证与Zookeeper通信(通过Zookeeper的heartbeat机制来实现);第二,Follower必须及时将Leader的writing复制过来,不能“落后太多”。这样,大家可以从这两个方面入手,来分析理解上面的问题。
在Broker机制中,Leader会追踪“in sync”的节点列表。如果一个Follower宕机,或者落后太多,Leader将把它从“in sync”列表中移除。这里所描述的“落后太多”指Follower复制的消息落后于Leader的条数超过阈值,该值可通过replica.lag.max.messages和replica.lag.time.max.ms参数来配置,只需在配置文件$KAFKA_HOME/config/serv⁃er.properties添加配置参数即可,如下所示:

需要注意的是,Kafka只解决“fail/recover”,不处理“Byzantine”问题。一条消息只有被“in sync”列表里的所有Follower都从Leader复制过去才会被认为已提交。这样就避免了部分数据被写进了Leader,还没来得及被任何Follower复制就宕机了,从而造成数据丢失,导致Consumer无法消费这些丢失的数据。对于Producer而言,它可以选择是否等待消息Commit,这可以通过request.required.acks来设置。这种机制确保了只要“in sync”列表有一个或以上的Follower,一条被commit的消息就不会丢失。
Kafka的Replication复制机制采用“in sync”备份列表的方式,这种方式与人们常说的同步复制和异步复制有些区别。事实上,同步复制要求“活着的”Follower都复制完,这条消息才会被认为成功复制完成,同步复制方式对吞吐率性能方面产生了极大的影响。而在异步复制方式中,Follower从Leader复制数据是通过异步进行的,数据只要被Leader写入Log就被认为已经成功复制完成,这种异步方式进行数据同步的缺点是,如果Follwer由于网络等原因都落后Leader,而Leader这时突然宕机,就会引起数据的丢失。而Kafka采用的“in sync”列表的方式就很好地、均衡地解决了同步复制方式和异步复制方式遇到的缺点,使得Follower可以批量从Leader中复制数据,并确保了数据不丢失,而且还具备较高的吞吐率。这极大地提高了Replication复制机制的复制性能。(https://www.daowen.com)
理解Kafka的Replication复制机制后,另外一个很重要的问题是当Leader宕机后,怎样在Follower中选举出新的Leader。一个基本原则就是,如果当前的Leader丢失了,新的Leader必须拥有原来的Leader Commit的所有消息。例如,如果Leader在标明一条消息被Commit前等待更多的Follower确认,这时突然Leader宕机,之后就有更多的Follower可以作为新的Leader,但这会造成吞吐率的下降。Kafka是怎样解决这个问题的呢?
常用的选举Leader的方式是少数服从多数(Majority Vote),但Majority votes算法劣势如下:比如,为了保证Leader Election的正常进行,它所能容忍的Follower丢失个数比较少。如果要容忍丢失1个Follower,必须要有3个以上的备份,如果要容忍丢失两个Follower,必须要有5个以上的备份。少数服从多数(Majority Vote)选择算法的优势主要体现在,系统的延迟只取决于延迟最少的几台服务器,也就是说,要延迟就取决于延迟最少的那个Follo⁃wer,而非最长的那个Follower。例如这里有2f+1个备份(其中含Leader和Follower),那么在Commit之前必须保证有f+1个备份复制完消息,为了保证正确选出新的Leader,失败的备份数不能超过f个,因为在剩下的任意f+1个备份里,至少有一个备份包含有最新的所有消息。换句话说,在生产环境中,为了确保较高的容错程度,需要大量的备份,但是大量的备份又会在大数据量下导致性能的显著下降,因此该算法更多地用在Zookeeper这种共享集群配置的系统中,而很少在需要存储大量数据的系统中使用。
实际上,基于Leader的选举算法非常多,比如HDFS的HA Feature是基于多数投票分类机制,但是它的数据存储并没有使用这种少数服从多数的方式。Zookeper的Zab、Raft和Viewstamped Replication。而Kafka所使用的Leader Election算法更像微软的PacificA算法。
Kafka的Leader选举机制是,在Zookeeper中动态维护了一个ISR(in-sync replicas)集合,这个集合里的所有备份都带上了Leader信息,只有ISR里的成员才能被选为Leader。在这种模式下,对于f+1个备份,一个Kafka Topic能在保证不丢失已经Commit的消息的前提下,容忍f个备份的失败。在大多数使用场景中,这种模式是非常有利的。事实上,为了容忍f个备份的失败,少数服从多数Leader选举机制和ISR在需要等待备份的数量Commit前是一样的,但是ISR需要的总的备份的数量几乎是Majority Vote的一半。
通过上面的分析,在一个Follower中,如果ISR至少有一个备份,那么Kafka就可以确保已经Commit的数据不丢失,但如果某一个Partition的所有备份都丢失了,那么就无法保证数据不丢失了。解决这个问题有两种可行的方案:
1)等待ISR集合中的任一个备份“活”过来,并且选它作为Leader。
2)选择第一个“活”过来的备份(不一定在ISR集合中)作为Leader。
下面分析这两种可行的解决方案,对于第一种方案,等待ISR集合中的任何一个备份“活”过来,不可用的时间将会比较长。当然,如果这个ISR集合中的所有备份都已经丢了,这个partition将永远不可用;对于第二种方案,选择一个“活”过来的备份作为Leader,即使这个备份不在ISR集合中,也不保证已经包含了所有已Commit的消息,即出现数据一致性问题,这就需要在可用性和一致性中进行折衷,目前Kafka0.8.∗使用了第二种方式。
Kafka集群需要管理成百上千个Partition,Kafka通过round-robin轮间调度算法来平衡Partition,从而避免大量Partition集中在少数几个节点上。同时Kafka也需要平衡Leader的分布,尽可能地让所有Partition的leader均匀分布在不同的Broker上。另一方面,优化Leadership Election的过程也是很重要的。实际上,Kafka选举一个Broker作为Controller,这个Controller通过Watch Zookeeper检测所有的Broker failure,并负责为所有受影响的Parition选举Leader,再将相应的Leader调整命令发送至受影响的Broker。这样做的好处是,可以批量地通知Leadership的变化,从而使得选举过程成本更低,尤其是对大量的Partition而言。如果Controller失败了,那么幸存的所有Broker都会尝试在Zookeeper中创建/controller->{this broker id},如果创建成功,则该Broker会成为Controller,若不成功,则该broker会等待新Controller的命令。这种机制在未来将要发布的0.9.∗版本中实现,如果想深入了解,可以阅读Kafka wiki中的文档Consumer Rewrite Design。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





