Topic在逻辑上可以被认为是一个queue,每条消费都必须指定它的Topic,可以简单地理解为必须指明这条消息要放进哪个queue里。为了使得Kafka的吞吐率可以线性提高,物理上把Topic分成一个或多个Partition,每个Partition在物理上对应一个文件夹,该文件夹下存储这个Partition的所有消息和索引文件,配置参数可以在config/server.properties文件中指定,其中的设置属性为log.dir={Kafka安装目录}/kafkaLogs。比如现在有Topic1和Top⁃ic2两个Topic,其中Topic1被分成15个Partition,Topic2被分成18个Partition,那么整个集群上面会相应地生成33个文件夹。
Topic中每个Partition对应一个逻辑日志。物理上,一个逻辑日志为相同大小的一组Segment文件。每次生产者发布消息到一个Partition,代理就将消息追加到最后一个Segment文件中。当消息数量达到设定值或者经过一定的时间后,Segment文件才真正写入磁盘中。写入完成后,消息才能被消费者订阅。Segment文件达到一定的大小后将不会再往该Seg⁃ment文件中写数据,Broker会创建新的Segment。
每个逻辑日志文件都是一个log entries序列,每个log entry包含一个4字节整型数值(值为N+5),1字节的"magic value",4字节的CRC校验码,其中checksum采用CRC32算法计算,其后跟N个字节的消息体。每条消息都有一个当前Partition下唯一的64字节的offset,它指明了这条消息的起始位置。磁盘上存储的消息格式如下:

这个log entries并非由一个文件构成,而是分成多个Segment文件,每个Segment文件以该Segment第一条消息的offset加“.kafka”后缀命名。而Active Segment List则是一个索引列表文件,它标明了每个Segment下包含的log entry的offset范围,如图14-2所示。
因为每条消息都被append到该Partition中,属于顺序写磁盘,因此效率非常高,经验证,顺序写磁盘效率比随机写内存还要高,这是Kafka高吞吐率的一个很重要的保证。
对于传统的message queue而言,一般会删除已经被消费的消息。而Kafka集群会保留所有的消息,无论其被消费与否。当然,因为磁盘限制,不可能永久保留所有数据。然而Kafka提供两种策略删除旧数据,一种是基于时间策略,另一种是基于Partition文件大小策略。用户在使用这个功能时,只要对Kafka配置文件$KAFKA HOME/config/serv⁃er.properties进行修改即可,比如实际应用需求要Kafka删除一周前的数据,并每隔300000ms检查一次log segments,删除满足条件的数据。相关配置项如下:(www.daowen.com)

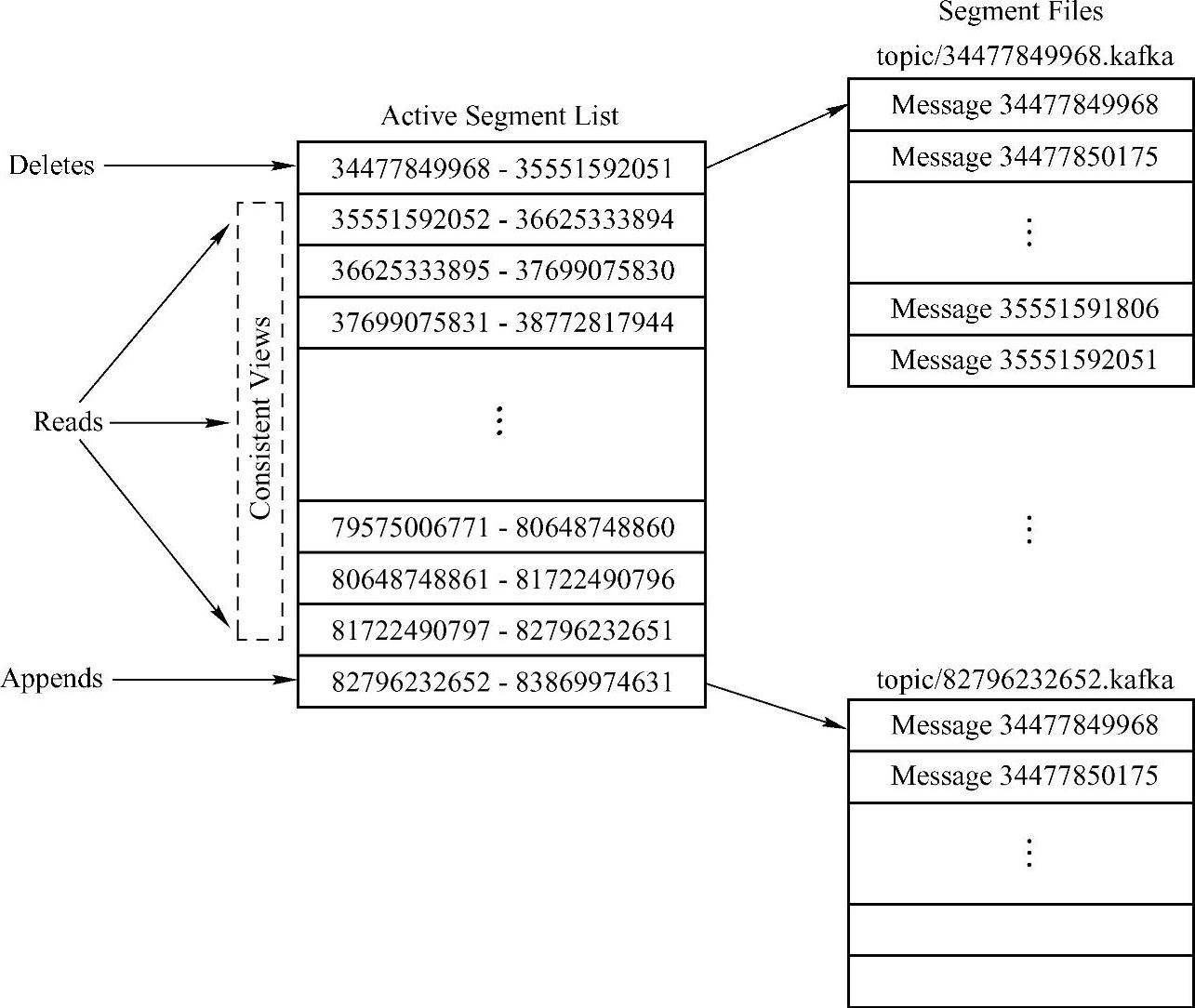
图14-2 Kafka Log实现机制原理图
这里要注意,因为Kafka读取特定消息的时间复杂度为O(1),即与文件大小无关,所以这里删除过期文件与提高Kafka性能无关。选择怎样的删除策略只与磁盘及具体的需求有关。另外,Kafka会为每一个Consumer Group保留一些metadata信息,即当前消费的消息的Position,也即offset,这个offset由Consumer控制。正常情况下,Consumer会在消费完一条消息后递增该offset。当然,Consumer也可将offset设置成一个较小的值,重新消费一些消息。因为offet由Consumer控制,所以Kafka Broker是无状态的,它不需要标记哪些消息被哪些消费过,也不需要通过Broker去保证同一个Consumer Group只有一个Consumer能消费某一条消息,因此也就不需要锁机制,这也为Kafka的高吞吐率提供了有力保障。
与传统的消息系统不同,Kafka系统中存储的消息没有明确的消息ID。消息通过日志中的逻辑偏移量(offset)来查找信息。这样就避免了维护配套密集寻址,用于映射消息ID到实际消息地址的随机存取索引结构的开销。消息ID是增量的,但不连续。要计算下一消息的ID,可以在其逻辑偏移的基础上加上当前消息的长度。
消费者始终从特定分区顺序地获取消息,如果消费者知道特定消息的偏移量,也就说明消费者已经消费了之前的所有消息。消费者向代理发出异步请求,准备字节缓冲区用于消费。每个异步请求都包含要消费的消息偏移量。Kafka利用sendfile API高效地从代理的日志Segment文件中分发字节给消费者。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。




