在某些应用场景,客户程序只是希望从Kafka读取数据,不太关心消息offset的处理。同时也希望提供一些语义,例如同一条消息只被某一个Consumer消费(单播)或被所有Consumer消费(广播)。因此,Kafka High Level Consumer提供了一个从Kafka消费数据的高层抽象,从而屏蔽掉其中的细节并提供丰富的语义。High Level Consumer就是基于这种情景产生的。在High Level Consumer机制中,消息消费是以Consumer Group为单位的,每个Consumer Group中可以有多个Consumer,每个Consumer是一个线程,同一Topic的一条消息只能被同一个Consumer Group内的一个Consumer消费,但多个Consumer Group可同时消费这一消息,Consumer Group对应的每个Partition都有一个最新的offset的值,存储在Zookeeper上,因而不会出现重复消费的情况,由于Consumer的offerset并不是实时地传送到Zookeeper(Kafka从0.8.2版本开始支持将offset存放在Zookeeper中,而以前offset存放在专用的Kafka Topic中)的,而是通过配置来设置更新周期的,所以Consumer如果突然Crash,有可能会读取重复的信息。
上面提及在High Level Consumer机制中,消息消费是以Consumer Group为单位,那么Consumer Group是如何定义的呢?通过上面的分析知道,High Level Consumer将从某个Parti⁃tion读取的最后一条消息的offset存于ZooKeeper中,这个offset基于客户程序提供给Kafka的名字来保存,这个名字被称为Consumer Group。Consumer Group是整个Kafka集群全局的,而非某个Topic的。每一个High Level Consumer实例都属于一个Consumer Group,若不指定则属于默认的Group。这是Kafka用来实现一个Topic消息的广播(发给所有的Consumer)和单播(发给某一个Consumer)的手段。一个Topic可以对应多个Consumer Group。如果需要实现广播,只要每个Consumer有一个独立的Group就可以了。要实现单播,只要所有的Consumer在同一个Group里。用Consumer Group还可以将Consumer进行自由分组,而不需要多次发送消息到不同的Topic。
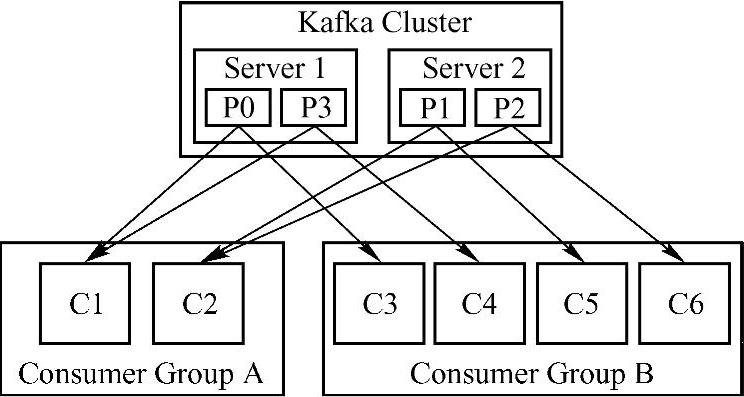
很多传统的Message Queue都会在消息被消费完后将消息删除,一方面避免重复消费,另一方面可以保证Queue的长度,提高效率。Kafka并不删除已消费的消息,为了实现传统的Message Queue消息只被消费一次的语义,Kafka保证每条消息在同一个Consumer Group里只会被某一个Consumer消费。与传统Message Queue不同的是,Kafka还允许不同Consumer Group同时消费同一条消息,这一特性可以为消息的多元化处理提供支持。如图14-1所示的集群,该集群由两个机器组成,拥有4个分区(P0~P3)两个consumer组,A组有两个consumer组,B组有4个。
 (https://www.daowen.com)
(https://www.daowen.com)
图14-1 Kafka Consumer Group特性
实际上,Kafka的设计理念之一就是同时提供离线处理和实时处理。根据这一特性,可以使用Storm这种实时流式处理系统对消息进行实时在线处理,同时使用Hadoop这种批处理系统进行离线处理,还可以同时将数据实时备份到另一个数据中心,只需要保证这3个操作所使用的Consumer在不同的Consumer Group即可。
为了更清楚地理解Kafka Consumer Group的特性,这里用一个简单的实例来进行说明,比如在Kafka集群中,在Broker中只有一个TopicA,该TopicA有3个Partition,在Customer中,有一个属于group1的Consumer实例,有3个属于group2的Consumer实例,通过Pro⁃ducer向TopicA发送key分别为1、2、3的消息,结果会发现属于group1的Consumer收到了所有的这3条消息,同时group2中的3个Consumer分别收到了key为1、2、3的消息。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。



