Kafka作为大数据时代下一代消息队列系统的新宠,其性能测试报告,可以参看相关的文献。虽然有很多不足,但是Kafka在提高效率等方面做了很多努力,比如,怎样解决线性读写对磁盘性能问题的影响、怎样使消息快速传递等。本节先对这些性能问题进行详细分析,之后从不同角度对Kafka的优化进行详细描述。前面分析Kafka的存储与缓存设计思想时表明,Kafka使用线性读写磁盘,可以提高Kafka的吞吐量和读写效率。但是这又展现另外两个问题:太多琐碎的I/O操作和频繁的字节复制。其中的I/O问题既可以发生在客户端和服务端之间,也可以发生在服务器内部的持久化操作中。
为了解决上面的问题,Kafka使用了“消息集(message set)”的概念,将消息聚集到一起,以消息集为单位处理消息,比单个的消息处理提升不少性能。Producer把消息聚集到一块发送给服务端;服务端把消息集一次性地追加到日志文件中,这样减少了琐碎的I/O操作,Consumer也可以一次性地请求一个消息集。那么怎样解决频繁的字节复制问题呢?在低负载时,这不会产生什么问题,但是在高负载的情况下,它对系统性能的影响还是很大的。为了避免这个问题,Kafka使用了标准的二进制消息格式,这种格式可以在Producer、Broker和Consumer之间共享,而无须做任何改动。
Producer、Broker和Consumer之间有了统一共享的数据格式,怎样将消息快速发送到网络上去,也是一个性能优化的地方,Kafka就利用sendfile的零复制方法来优化了这个性能问题,大大提高了数据传输的效率。比如,在一个多Consumers的场景里,数据仅仅被复制到页面缓存一次,而不是每次消费消息的时候都重复进行复制,这样在磁盘层面几乎看不到任何读操作,这样消息会以近乎网络带宽的速率发送到网络上面去。
随着计算机的快速发展,在系统架构设计,特别是分布式系统架构设计中,网络带宽的限制已经远远超过了计算机本身的CPU或者硬盘的限制,因此在数据中心之间的数据传输中,网络带宽是性能提升的瓶颈。由于Kafka使用了“消息集(Message Set)”的概念,消息传输时,Kafka采用了端到端的压缩策略,客户端的消息可以一起被压缩后送到服务端,并以压缩后的格式写入日志文件,以压缩的格式发送到Consumer,消息从Producer发出到Consumer拿到的数据都是被压缩的,只有在Consumer使用的时候才被解压缩。
通过上面的系统分析,大家应该对磁盘读写、零复制、数据压缩等方面的性能优化问题有了一个全面的了解。除了这些性能优化策略,还可以从操作系统预读、TCP参数等方面进行系统级别的Kafka优化。下面从Kafka本身的架构进行应用级别的性能优化分析。如图13-6到图13-8展示了Kafka的Producer、Broker、Consumer的网络请求处理流程,对于Kafka的Producer端,Topic可以按照Partition分组批量发送消息到不同的Broker服务器上,在异步发送时,可以通过配置文件设置缓冲区的大小和Commit Batch的大小;然而对于Kaf⁃ka的Broker,可以利用Log Index机制,批量定量或者定时进行消息读取或者持久化操作,
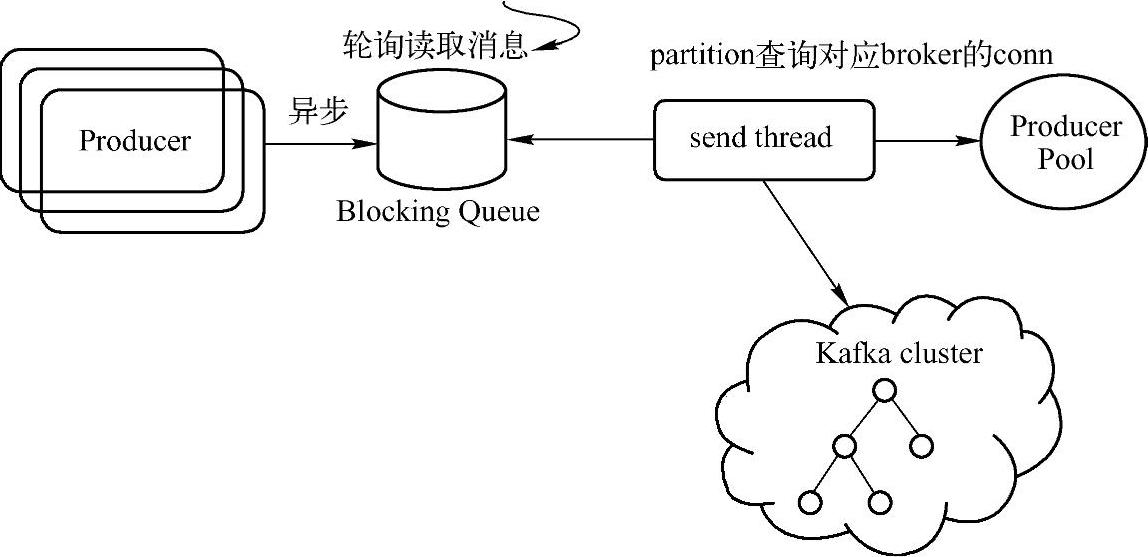
图13-6 Kafka Network请求处理流程(Producer)(https://www.daowen.com)
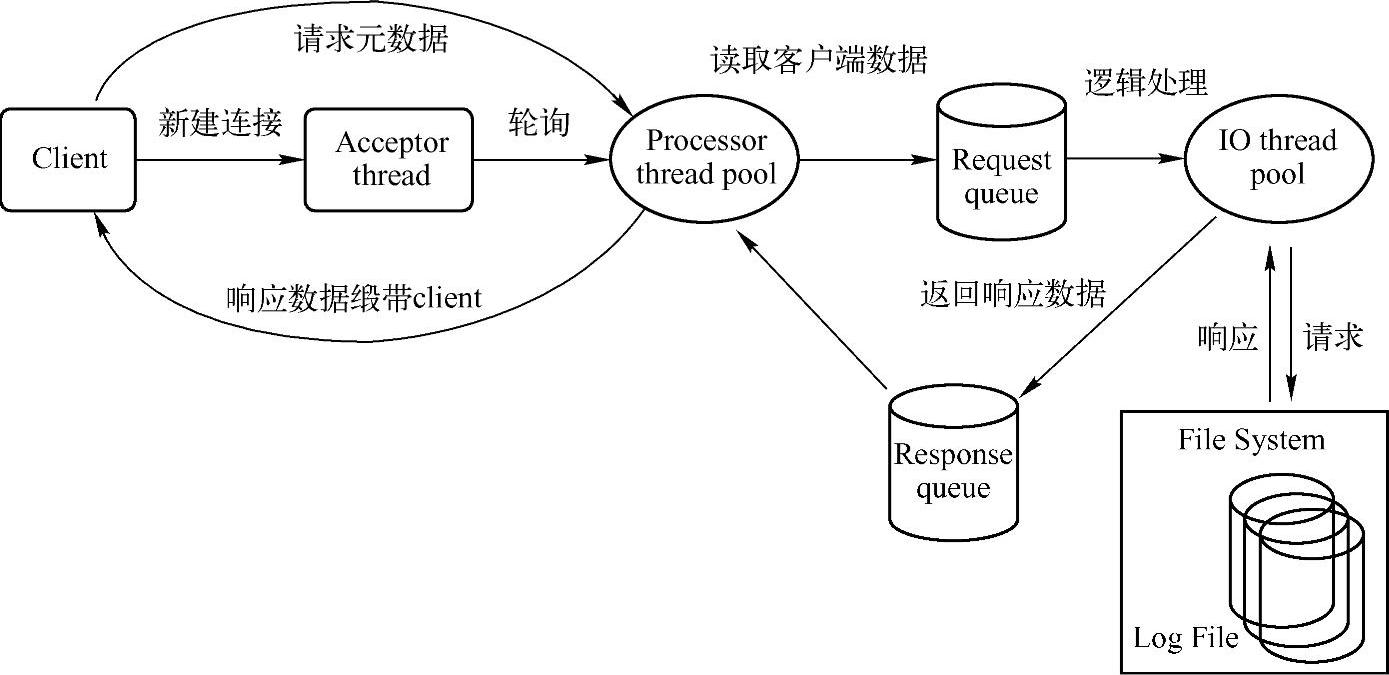
图13-7 Kafka Network请求处理流程(Broker)
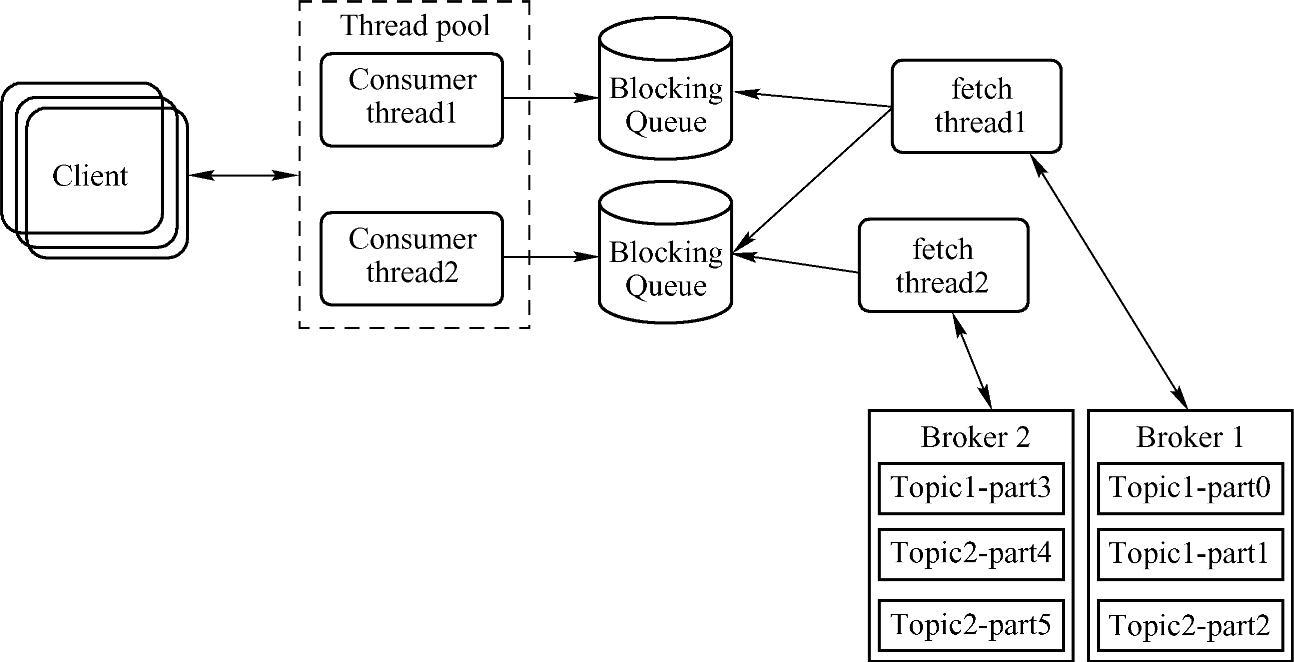
图13-8 Kafka Network请求处理流程(Consumer)
来提高Kafka的整体性能;对于Kafka的Consumer端,可以采用多线程消费消息、多线程拉取消息、多队列缓存消息来提高Consumer端的性能。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






