Kafka集群包括3个部分:Producer、Broker、Consumer,Kafka通过Producer将消息传输到Broker,之后Consumer从Broker获取数据,进行消费。因此可以这样理解,Kafka集群即Broker集群,通过Kafka的Producer API与Consumer API向外提供获取消息与消费消息的接口。这就是为什么Kafka被很多公司用来作为不同类型数据管道和消息系统的原因。
Kafka的工作流程如图13-5所示,被分为A、B、C、D四个部分。其中A部分是消息的收集部分,该部分可以是不同应用数据和日志,如果要收集这些数据,用户只要实现Kaf⁃ka提供的Producer API,Producer基于Push机制,就可以将消息传输到B部分;B部分是Broker集群,即Kafka集群,从Producer传输来的消息,就存储在这里;C部分是Consum⁃er,Consumer通过Pull机制从Broker中消费数据(消息),Consumer去向也是多种多样的,比如从Broker传输过来的数据(消息),可以存储到各种数据库中,可以存储到Hadoop集群上,还可以用这些数据(消息)进行实时分析和计算等,用户仅仅实现Kafka提供的Consumer API即可;D部分是元数据存储与控制部分,该部分通过Zookeeper集群来实现,换句话说,数据(信息)从Broker传输到Consumer时,一些状态信息及元数据信息就是通过Zookeeper监控及存储的,因此Zookeeper集群要直接跟Broker和Consumer进行通信。为了便于理解,下面详细地记录了Producer、Broker、Consumer处理消息工作流程。
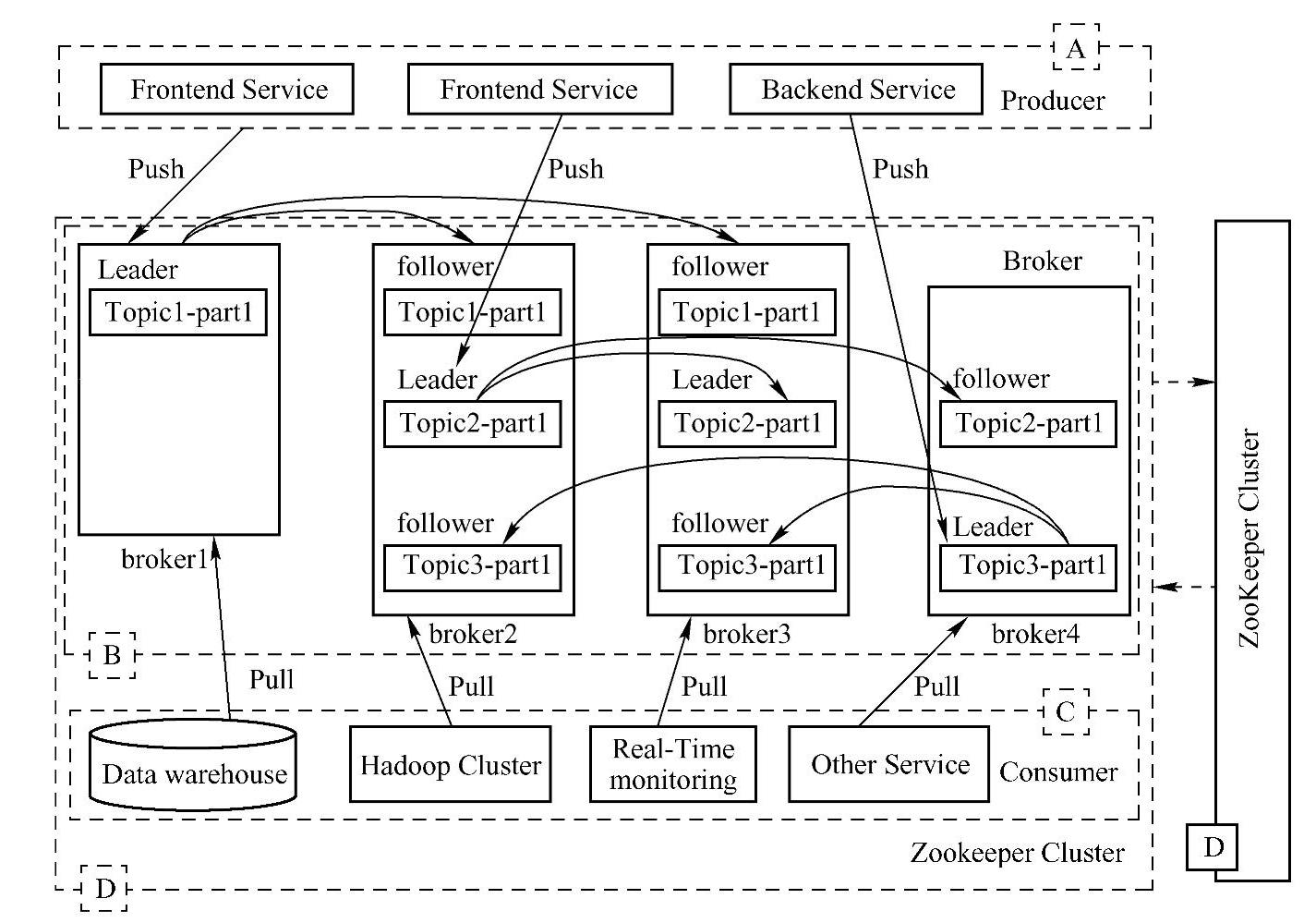
图13-5 Kafka的工作流程图
1)每个Broker都可以配置一个Topic,一个Topic可以有多个分区,但是在Producer看来,一个Topic在所有Broker上的所有分区组成一个分区列表来使用。
2)在创建Producer的时候,Producer会从Zookeeper上获取Publish的Topic对应的Bro⁃ker和分区列表。Producer在通过Zookeeper获取分区列表之后,会按照BrokerId和Partition的顺序排列组织成一个有序的分区列表,消息发送的时候按照从头到尾循环往复的方式选择一个分区来发送。(https://www.daowen.com)
3)如果想实现自己的负载均衡策略,可以实现相应的负载均衡策略接口。
4)消息Producer发送消息后返回处理结果,结果分为成功、失败和超时。
5)Broker在接收消息后,依次进行校验和检查,写入磁盘,向Producer返回处理结果。
6)Consumer在每次消费消息时,首先把offset加1,然后根据该偏移量,找到相应的消息,然后开始消费。只有在成功消费一条消息后,才会接着消费下一条。在消费某条消息失败(如异常)时,则会尝试重试消费这条消息,超过最大次数后仍然无法消费,则将消息存储在消费者的本地磁盘,由后台线程继续进行重试。而主线程继续往后走,消费后续的消息。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





