Spark是UC Berkeley AMP lab所开源的类Hadoop MapReduce的通用并行计算框架,Spark拥有Hadoop MapReduce所具有的优点,但不同于MapReduce的是,Job的中间输出结果可以保存在内存中,从而不再需要读写HDFS,因此Spark能更好地适用于数据挖掘与机器学习等需要迭代的算法。
Spark在很多模块之间的通信选择是Akka,Spark之所以选择Akka,是因为Akka有以下5个特性:
1)易于构建并行和分布式应用(Simple Concurrency&Distribution):Akka在设计时采用了异步通信和分布式架构,并对上层进行抽象,如Actors、Futures、STM等。
2)可靠性(Resilient by Design):系统具备自愈能力,在本地/远程都有监护。
3)高性能(High Performance):在单机中每秒可发送50000000个消息。内存占用小,1 GB内存中可保存270万个Actors。
4)弹性,无中心(Elastic—Decentralized):自适应的负责均衡、路由、分区、配置。
5)可扩展(Extensible):可以使用Akka扩展包进行扩展。
在Spark中各个模块之间通过Akka来相互通信,可以说Spark的整个通信体系都是构建在Akka之上的,因此了解和学习Akka对于深入学习Spark架构、研究Spark的内核是有巨大帮助的。下面将列举Akka在Spark中的应用,使用的Spark版本是1.4.1。
Spark中Client、Master、Worker之间的通信是用Akka框架来完成的。如图12-3所示是Spark集群通信架构图,从图中可以看到,客户端编写的程序在Driver端运行,Driver端的DAGScheduler划分出不同的Stage,并将Stage划分成一个TaskSet交给TaskScheduler,Task⁃Scheduler将划分好的Task通过集群提交到不同的Worker节点进行计算,计算完成之后Worker将运行状态和结果通过集群返回Master。
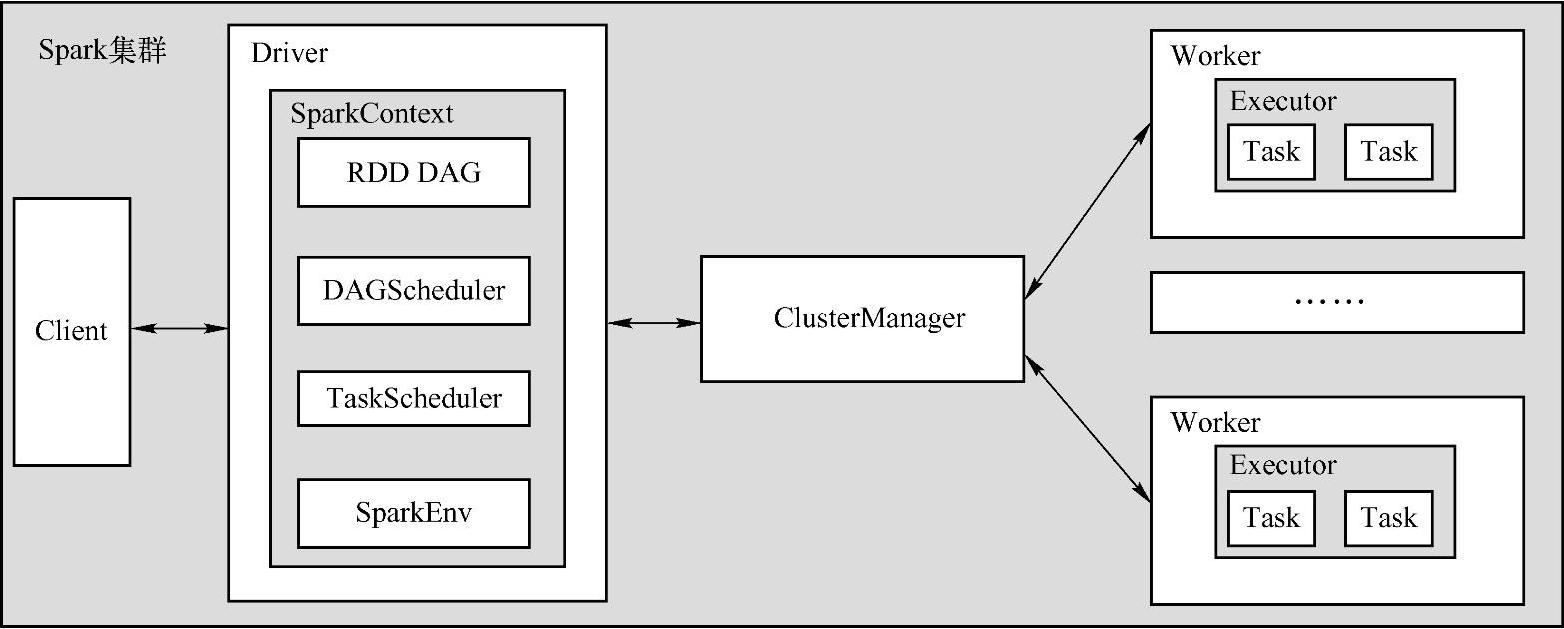
图12-3 Spark通信构架
●Client:负责提交作业到Master。
●Master:接收Client提交的作业,管理Worker,并命令Worker启动Driver和Executor。
●Worker:负责管理本节点的资源,定期向Master汇报心跳,接收Master的命令,例如
启动Driver和Executor。(https://www.daowen.com)
下面将通过源代码,了解Akka在Spark中的应用。
1.Client与Master的通信
Client代码:位于org.apache.spark.deploy.Client。在Client中,会构建ClientActor,Cli⁃entActor在preStart方法中会向MasterActor发送RequestSubmitDriver消息,请求提交Driver程序。以下是Client的源代码:

代码中,使用AkkaUtils.createActorSystem()创建了一个名为“driverClient”的Akka Sys⁃tem,actorSystem.actorOf(Props(classOf[ClientActor],dirverArgs,conf))这句代码的作用是创建ClientActor。在preStart方法中向MasterActor发起RequestSubmitDriver提交请求,MasterActor在收到该请求后,完成Driver程序的注册,并返回SubmitDriverResponse消息,ClientActor将在receiveWithLogging函数中匹配并处理该消息。ClientActor的receiveWithLogging代码如下所示:

上面列出了ClientActor的receiveWithLoging方法的部分代码,在代码中,通过case匹配返回给ClientActor的SubmitDriverResponse消息,并进行合适的处理。
2.Master与Client的通信 Master收到ClientActor发送的注册请求,在调度完成之后将会向ClientActor发送Submit⁃DriverResponse消息。先来看一下Master中是怎样创建ActorSystem的,Master的部分关键代码如下所示:

在上面的代码中,可以看到调用了startSystemAndActor方法,该方法用于启动ActorSys⁃tem。startSystemAndActor方法代码如下所示:

源代码中调用了AkkaUtils.createActorSystem,该方法建立了sparkMaster这个ActorSys⁃tem,然后调用actorSystem.actorOf创建MasterActor。在Master的receiveWithLogging方法中,接收到RequestSubmitDriver请求并完成调度之后,会向ClientActor发送SubmitDriverResponse消息,以完成Master和Client之间的通信。Master中receiveWithLogging部分源代码如下所示:

3.Master和Worker之间的通信 在Worker源代码中同样有一个startSystemAndActor方法,在该方法中,依然调用AkkaUtil.createActorSystem创建名为sparkWorker的ActorSystem,并通过ActorSystem的ac⁃torOf方法创建WorkerActor,通过WorkerActor向Master发送RegisterWorker消息,以完成注册。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






