本节将介绍的是使用Akka框架实现单词统计(WordCount)的实例。Akka框架中使用的Actor跟Scala中的Actor异曲同工,并且Akka也是使用Scala语言编写的。因此本实例直接以Akka中的Actor来编写WordCount代码。使用Akka首先要引入Akka的依赖包,Akka依赖包可以到Akka官网或者到mvnrepository.com/tags/maven上搜索,下载对应版本的JAR包并导入项目中。
本例使用MapActor来对输入的语句进行切分计数,使用ReduceActor对MapActor切分后的单词个数进行化简统计,最后交由AggregateActor进行全局的统计。首先定义消息实体类。
1.定义消息实体类</ID=4>

定义传递的消息实体类,用于传递统计消息。WordInfo类中有两个属性:Word和该Word出现的次数count。GetResult样本类告诉AggregateActor返回统计结果,MapInfo用于记录MapActor中的数据,ReduceInfo用于记录ReduceActor中的记录。
程序中使用MapActor处理输入文本信息,并将文本按照空格切分,形成一个如MapInfo的对象,并将MapInfo传入ReduceInfo进行化简统计。
2.使用MapActor处理输入文本信息
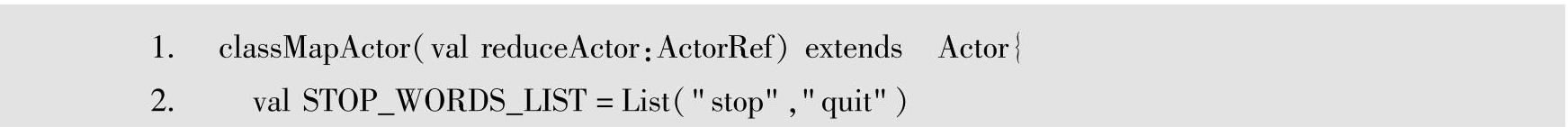

MapActor的receive方法中匹配收到的消息,如果消息是String类型,则执行calculation(message)方法,并将该方法的返回值发送给reduceActor。在calculation方法中,首先构造一个dataList数组,用于存放由message消息解析出的WordInfo对象。WordInfo对象用于记录解析出的单词及单词对应的个数,此处每一个单词对应一个WordInfo对象,因此单词个数为1,用defaultCount常量表示。方法中使用StringTokenizer工具解析每一个单词。对于解析出来的每一个单词,只要不是STOP_WORDS_LIST列表中的单词,都放入到dataList数组中。解析完成之后,使用解析出来的dataList构建一个MapInfo对象并返回。该MapInfo对象将通过“!”方法,发送给reduceActor,reduceActor将根据单词进行化简,求出相同单词的个数。对MapInfo中的元组数据化简的ReduceActor代码如下所示。
3.ReduceActor进行化简</ID=2>


ReduceActor的receive方法匹配到case message:MapInfo消息之后,将执行reduce(mes⁃sage.dataList)方法,并将reduce方法的返回结果发送给aggregateActor进行最后的汇总处理。
reduce方法中,首先定义一个HashMap,键是单词,值是单词出现的次数。在for循环中,对dataList中的单词按单词统计计数并放入到reduceMap中,统计计数完成之后,使用reduceMap构建一个ReduceInfo对象并返回。
reduce方法返回的ReduceInfo对象将会被发送给AggregateActor进行最后的汇总,代码如下所示。
4.AggregateActor汇总结果</ID=2>
 (https://www.daowen.com)
(https://www.daowen.com)

在AggregateActor中定义了一个finalReduceMap,用于存放最终的单词统计结果,键是单词,值是单词的出现次数。
AggregateActor的receive方法中,若匹配到case message:ReduceInfo消息,将调用doAg⁃gregate(message.reduceMap)方法,将reduce阶段的结果汇入最终的结果集finalReduceMap中。
doAggregate方法中,遍历reduceMap,对于reduceMap中的每一个单词,若finalRe⁃duceMap中存在该单词,则取出reduceMap中该单词对应的数目和finalReduceMap中该单词对应的数目相加,用相加的结果更新finalReduceMap中该单词对应的数据。若finalRe⁃duceMap中不存在该单词,则直接把该单词和单词对应的个数放入finalReduceMap中。
每一次doAggregate方法的调用,都将更新finalReduceMap中记录的单词及单词个数。若receive方法收到的消息为case message:GetResult,则调用println方法打印出finalRe⁃duceMap中的单词及单词对应的个数。
上面提到了MapActor,ReduceActor,AggregateActor,那么这些Actor是如何协同工作的呢?这其实就跟一个公司组织结构差不多,公司有很多员工,每个员工做自己的事情,员工与员工要得到其他部门的帮助需要一个部门经理来协调,这样就使每一个员工专注于处理自己的事情而不因协调琐碎杂事分心。该程序设计中,使用MasterActor来协调管理。一个好的部门经理应该非常的知晓自己带领员工的能力及特长,以便于合理的分配任务和调度资源。MasterActor在这里起协调、调度功能,因此它必须对自己的手下知根知底。其实Ma⁃pActor、ReduceActor、AggregateActor的初始化,都是在MasterActor内部通过context对象初始化的,代码如下所示。 5.MasterActor进行初始化</ID=2>


MasterActor是一个全局的管理者,要负责初始化MapActor、ReduceActor、AggregateAc⁃tor。因为MapActor中拆分出来的单词需要发送给ReduceActor处理,因此在创建MapActor的时候,要将ReduceActor传入,这样在MapActor中就可以通过传入的ReduceActor的引用向ReduceActor发送消息了。同样的ReduceActor中统计的单词信息需要发送给AggregateAc⁃tor进行最后的汇总,因此在创建ReduceActor时,要将AggregateActor传入,这样在Reduce⁃Actor中就能向AggregateActor发送消息了。
所有条件都已经具备,现在只需要在main函数中通过ActorSystem启动MasterActor,并向MasterActor发送消息即可驱动统计程序的运行。如下所示。
6.在客户端程序中启动ActorSystem,创建MasterActor,开始单词统计

在上面的Boot程序中,创建了一个名为sbt_akka的ActorSystem对象,通过该对象的ac⁃torOf方法创建MasterActor。有了MasterActor之后,就可以向其发送消息及指令进行单词的统计及显示了。程序中发送了三条语句,调用Thread.sleep方法让线程睡眠500毫秒,目的是等待统计工作完成。然后向master发送GetResult消息,master接收到该消息后将打印出单词的统计信息。最后调用ActorSystem的shutdown方法,关闭ActorSystem。
运行结果如图12-2所示。

图12-2 wordCount运行结果
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





