监管描述的是Actor之间的关系:监管者将任务委托给下属并对下属的失败状况进行响应。当一个下属出现了失败(如:抛出一个异常)时,它会将自己和自己所有的下属挂起,然后向自己的监管者发送一个提示失败的消息。取决于所监管的工作性质和失败的性质,监管者可以有4种基本选择:
1)让下属继续执行,保持下属当前的内部状态。
2)重启下属,清除下属的内部状态。
3)永久地终止下属。
4)将失败沿监管树向上传递。
在Actor的监管体系中,始终把每一个Actor视为整个监管树形体系中的一部分,这解释了第4种选择存在的意义(因为一个监管者同时也是其上方监管者的下属),并且隐含在前3种选择中,让Actor继续执行的同时也会继续执行它的下属,重启一个Actor也必须重启它的下属,相似地,终止一个Actor,会终止它所有的下属。需要强调的是一个Actor的默认行为是在重启前终止它的所有下属,但这种行为可以用Actor类的preRestart回调函数来重写,对所有子Actor的递归重启操作在这个回调函数之后执行。
每个监管者都配置了一个函数,它将所有可能的失败原因(如:Exception)翻译成以上4种选择之一。但值得注意的是,这个函数并不将失败Actor本身作为输入。或许你很快会发现在有些结构中这种方式看起来不够灵活,因为试图在某一个层次做太多事情,这个层次会变得复杂难以理解,这时推荐的方法是增加一个监管层次。因此应对不同的下属采取不同的策略。在这个问题上要理解的一点是,监管是为了组建一个递归的失败处理结构。
Akka实现的是一种类似于“父监管”的策略。Actor只能由其他的Actor创建,而顶部的Actor是由库来提供的,每一个创建出来的Actor都由它的“父亲”所监管。这种限制使得Actor的树形层次拥有明确的形式。这也同时保证了Actor不会成为孤儿或者拥有在系统外界的监管者(被外界意外捕获)。还有,这样就产生了一种对Actor应用(或其中子树)自然又干净的管理过程。
在Actor System启动的时候至少会启动3个Actor,如图11-5所示。
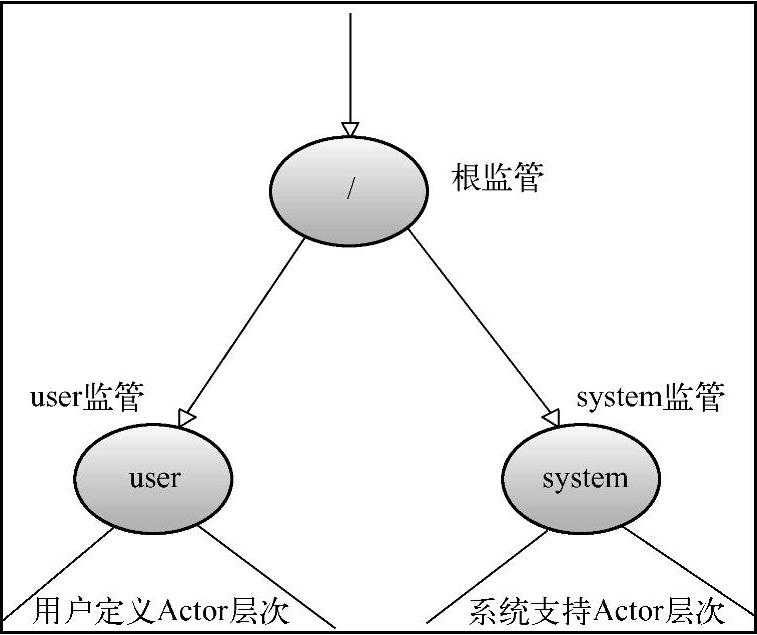
图11-5 Actor System的启动
在路径树的最顶部是根监管者,所有的Actor都可以通过它来找到。在第二个层上是以下这些:
●"/user"是所有由用户创建的顶级Actor的监管者,用ActorSystem.actorOf创建的Ac⁃
tor在其下一个层次。
●"/system"是所有由系统创建的顶级Actor(如日志监听器或由配置指定在Actor系统启动时自动部署的Actor)的监管者。
●"/deadLetters"是死信Actor,所有发往已经终止或不存在的Actor的消息会被送到这里。
●"/temp"是所有系统创建的短时Actor(例如那些用在ActorRef.ask的实现中的Actor)的监管者。
●"/remote"是一个人造的路径,用来存放所有其监管者是远程Actor引用的Actor。
在Akka中,使用了“Let It Crash”模型,那么使用这种模型,怎样管理众多的Actor呢?其实在Akka中,使用了监管策略。有两种监管策略,分别是:One-For-One和All-For-One。
当一个Actor崩溃或者抛出异常的时候,谁去监管处理异常呢?一种方式是,确保每一个Actor都知道去处理失败,并且在编写程序的时候要预防可能出现的异常,因此每一个Actor中必须增加异常处理代码,以便对各种各样的异常进行处理,随着异常的增加,代码将变得越来越庞大,维护起来也越来越困难。(https://www.daowen.com)
为了让Actor适合大规模的编程,必须让Actor之间相互协作,将任务分步处理,但是问题随之而来,如果一个Actor发生了异常导致处理失败,该怎么做?另外的Actor如何感知到其中一个Actor发生了异常?所有协作的Actor如何保证数据的一致性?
为了使Actor计算单元保持最小并且仍然提供一种机制处理失败,Akka将Actor模型优化成一种树状的层次模型。Actor是一个纯粹的计算单元,Actor模型的目的就是将大的任务划分成小的任务,直到该任务可以在一个Actor中被处理。为了管理这些特殊的Actor,必须使用监控———Supervision。Actor的监控树形层次如图11-6所示。
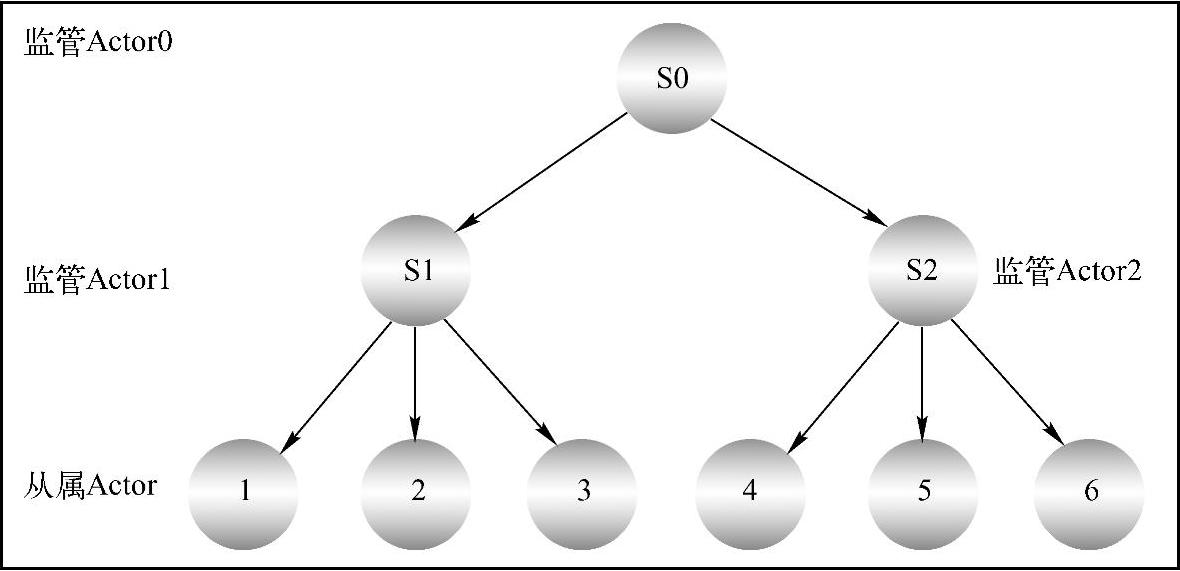
图11-6 Supervisor监控层次
在树形层次的Actor系统结构中,每一个Actor都知道自己要处理哪种类型的数据,知道重新运行失败的数据。当Actor不知道怎么去处理一个特殊的消息或者遇到非正常的运行状态时,它将会向Supervisor发送消息寻求帮助,这种递归的层次结构允许问题以冒泡的方式向上传送,直到问题可以被解决为止。需要注意的是,每一个Actor有且只有一个Supervisor。
Akka的容错机制正是建立在这种树形的层次结构和Supervisor之上的。Akka提供了一个默认的Supervisor———“user”,它是所有用户创建Actor的根Supervisor。
Supervisor提供了不同Actor之间的依赖关系,Supervisor的使命是分配任务给监控的Ac⁃tors,这些Actors称为Subordinates,并且要管理下属的生命周期。当管理的下属发生异常时,Supervisor将会收到通知,并且处理失败。当Supervisor收到下属失败通知的时候,可能会采取以下操作:
●Restart下属Actor:杀死当前的Actor实例,并且重新实例化一个Actor。
●Resume下属Actor:当前的Actor将会保持当前的状态,就跟什么都没有发生过一样。
●Terminate下属Actor:永久地终止下属Actor。
●Escalate:将失败继续上抛至自己的Supervisor。
如图11-7所示。
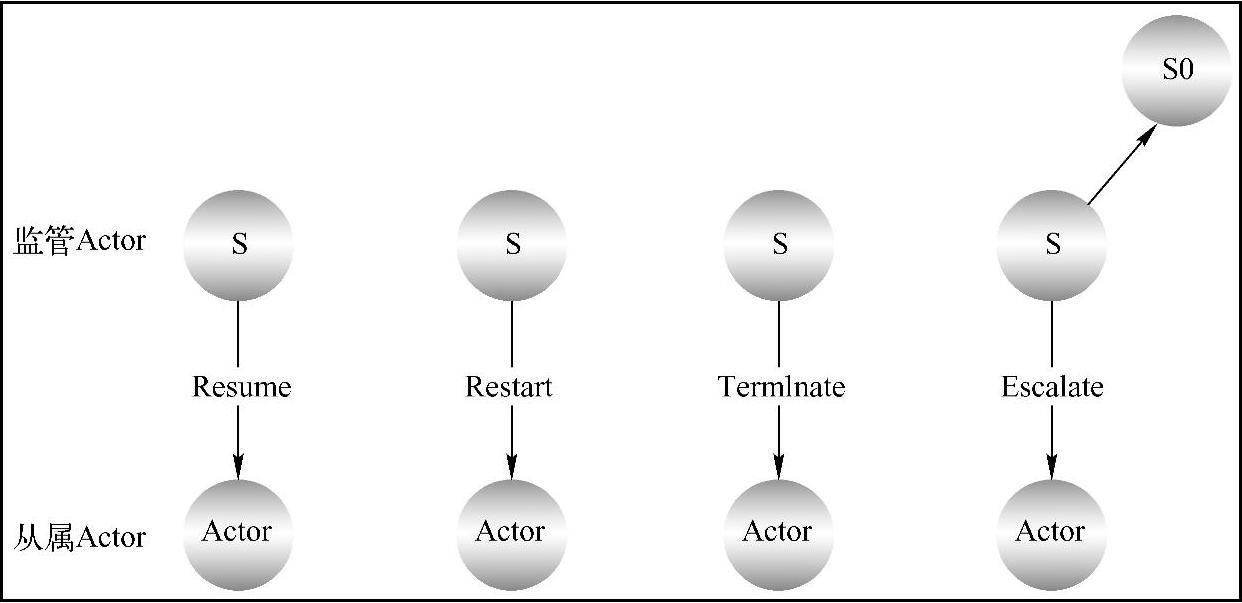
图11-7 Supervisor的几种处理
当Subordinate发生异常的时候,Supervisor有4种不同的处理方式。Akka提供了两种监管策略。分别是:One-For-One-Strategy和All-For-One-Strategy。
监管策略提供了当子Actor处理失败或者发生异常的时候怎样去处理的实现。One-For-One-Strategy意味着监管策略只作用在失败的子Actor上,All-For-One-Strategy意味着监管策略作用在所有的子Actor上。
All-For-One-Strategy监管策略适用于紧密相互依存的Subordinate中。例如,你正在操作库存信息,这些操作分为几步,当其中一步发生异常时,必将导致其他Actor状态的异常,在这种情况下,重启所有的Actor才能够保证状态的一致性。当你的Actor层次结构中使用这种监管策略的时候,一个Actor发生异常导致失败后,Supervisor将会发送命令停止并重启Actor,但这并不意味着所有兄弟姐妹Actor都将重启,这由Supervisor所管理和决定。 
生命周期监控是向监控Actor发送Terminated消息。如果没有处理,默认抛出一个DeathpactException。Monitoring对于监控器要结束子Actor但是又不能够简单地重启Actor这种场景特别有用。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。







