在Hadoop的基础上,进行Spark系统的安装,具体步骤如下:
(1)Spark的下载
进入Spark的下载页面,下载spark-1.6.0-bin-hadoop2.6.tgz版本(http://www.apache.org/dyn/closer.lua/spark/spark-1.6.0/spark-1.6.0-bin-hadoop2.6.tgz),保存到Windows本地目录。
(2)将文件传送至虚拟机
使用WinSCP文件传输工具将spark-1.6.0-bin-hadoop2.6.tgz从本地Windows系统传送到虚拟机系统上;打开WinSCP工具,连接Linux虚拟机,将该文件复制到/usr/local/set⁃up_tools目录下。
使用PieTTY远程连接工具,登录到Linux远程虚拟机,输入cd/usr/local/setup_tools命令进入setup_tools目录,输入ls命令,查看spark-1.6.0-bin-hadoop2.6.tgz文件是否已经成功上传到虚拟机文件系统上。

(3)解压并安装
输入#tar-zxvf spark-1.6.0-bin-hadoop2.6.tgz命令进行解压。
将spark-1.6.0-bin-hadoop2.6.tgz解压到spark-1.6.0-bin-hadoop2.6目录以后,使用ls命令查看spark-1.6.0-bin-hadoop2.6.tgz是否已经解压完成,使用#mv spark-1.6.0-bin-hadoop2.6/usr/local命令将spark-1.6.0-bin-hadoop2.6目录从/usr/local/set⁃up_tools目录移动到/usr/local目录中。

(4)配置Spark的全局环境变量
输入#vi/etc/profile命令,打开profile文件,输入I(i)可以进入文本输入模式,在pro⁃file文件中增加SPARK_HOME及修改PATH的环境变量,然后在vi中按Esc键,输入:wq!,保存并退出。

(5)环境变量配置生效
在命令行中输入source /etc/profile命令,使刚才修改的SPARK_HOME及PATH配置文件生效。

(6)spark-env.sh配置文件修改
输入#cd/usr/local/spark-1.6.0-bin-hadoop2.6/conf命令,修改Spark的配置目录。
输入#mv spark-env.sh.template spark-env.sh命令,将spark-env.sh.template模板文件更改为spark-env.sh。
输入名称#vi spark-env.sh,打开spark-env.sh文件,输入I(i)可以进入文本输入模式,在spark-env.sh文件中,配置相关参数,然后在vi中按Esc键,输入:wq!,保存并退出。

(7)查看slaves配置文件
输入#vi slaves命令,查看slaves文件中是否已经有localhost节点。

(8)启动Hadoop所有服务进程集群
因为Hadoop和Spark都有start-all.sh执行文件,因此先进入Hadoop的bin目录,启动Hadoop集群。(https://www.daowen.com)
1)输入#cd/usr/local/hadoop-2.6.0/sbin。
2)输入#start-all.sh。
3)输入#jps,此时可以看出Hadoop有5个进程。


(9)启动Spark集群
进入Spark集群的sbin目录。
1)输入#cd/usr/local/spark-1.6.0-bin-hadoop2.6/sbin。
2)输入#start-all.sh。
此时Spark集群已经启动,通过JPS查看进程,可以看到在Hadoop的5个进程的基础上,Spark运行worker和master两个进程,如下:

(10)启动spark-shell
输入#spark-shell命令,启动spark shell这里显示Spark版本为version 1.6.0,如图1-22所示。
从图中可以看到,在spark shell环境中出现了熟悉的Scala提示符,因为Spark原生开发语言是Scala,因此Spark与Scala可以完美集成。在Scala交互式命令行中,输入一个计算表达式,Scala准确地计算出了1+2及res0∗0.5的结果。

图1-22 启动spark-shell

在Scala提示符中输入exit命令,即可退出spark shell环境。
(11)以Web方式查看Spark
VMware Workstation的Linux虚拟机的Spark启动起来以后,在Windows本地计算机上(192.168.2.1)上打开Web浏览器,在浏览器中输入Spark的URL:http://192.168.2.100:8080/,就可以查看Spark系统的相关信息。
至此,Spark系统安装全部完成,Spark安装成功。如图1-23所示。
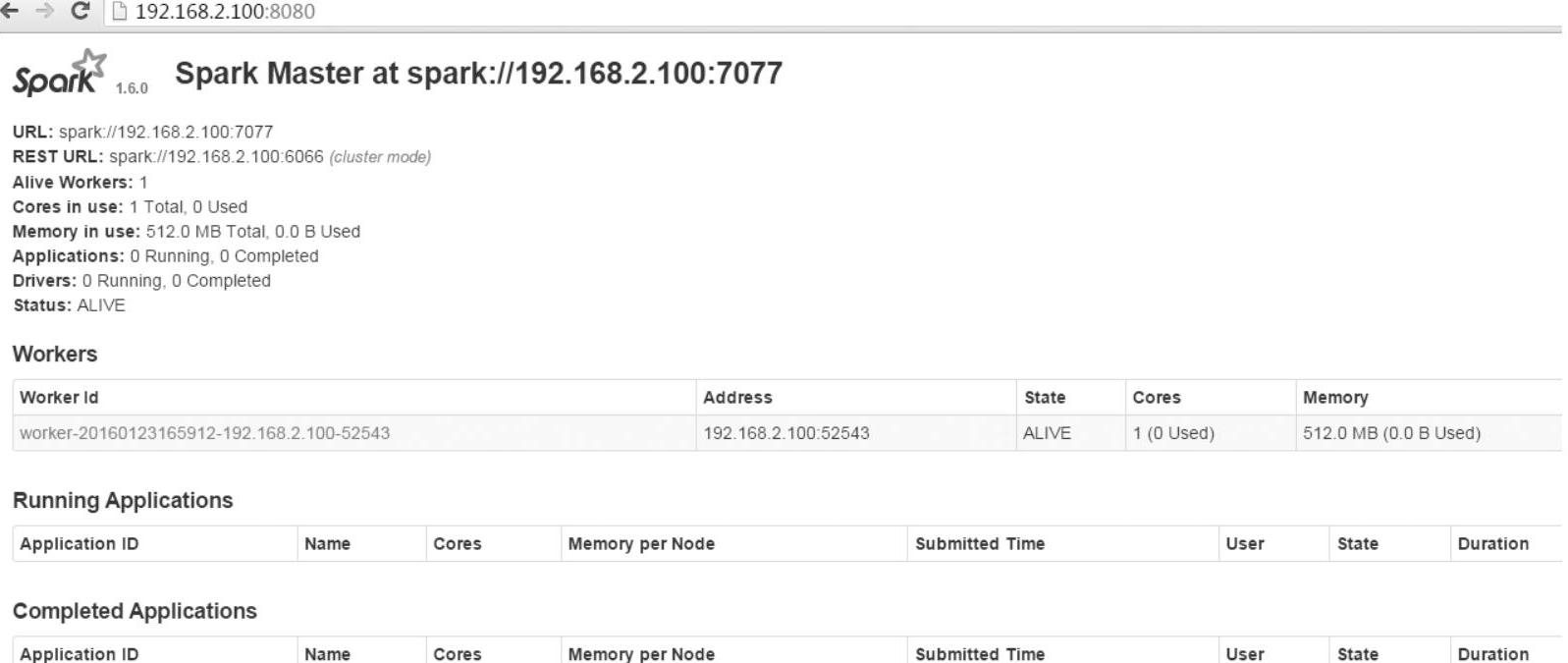
图1-23 Spark Web页面
(12)关闭Spark服务进程
进入Spark安装目录的bin目录。1)输入#cd/usr/local/spark-1.6.0-bin-hadoop2.6/sbin。2)输入#stop-all.sh。关闭Spark服务进程。

免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。




