1.准备工作
(1)关闭防火墙
在Linux环境下Hadoop的安装配置中,为减少网络访问中出现的错误,在测试环境中尽可能关闭对网络的限制,使Hadoop的安装能顺利进行。在生产环境中,要规划防火墙的配置,保障业务的运行。
登录VMware Workstation的Linux虚拟机,输入用户名、密码进入Linux系统,在Linux的Applications菜单的System Tools中选择Terminal工具,如图1-16所示,打开Terminal终端。
图1-16 Terminal工具
在Terminal终端中输入setup命令,输入系统管理员的密码,如图1-17所示。
打开Linux的内置管理工具,可以管理防火墙、IP地址、各类服务等信息的设置。如图1-18所示。
选择Firewall configuration,然后按Enter键,如图1-19所示。
如果中间的方括号中有“∗”,表示被选中,说明防火墙是被启用的。关闭防火墙,只需要按一下空格键,符号“∗”就会消失。然后使用Tab键选中OK按钮,按Enter键确定退出。
图1-17 setup命令
图1-18 Linux的内置管理工具
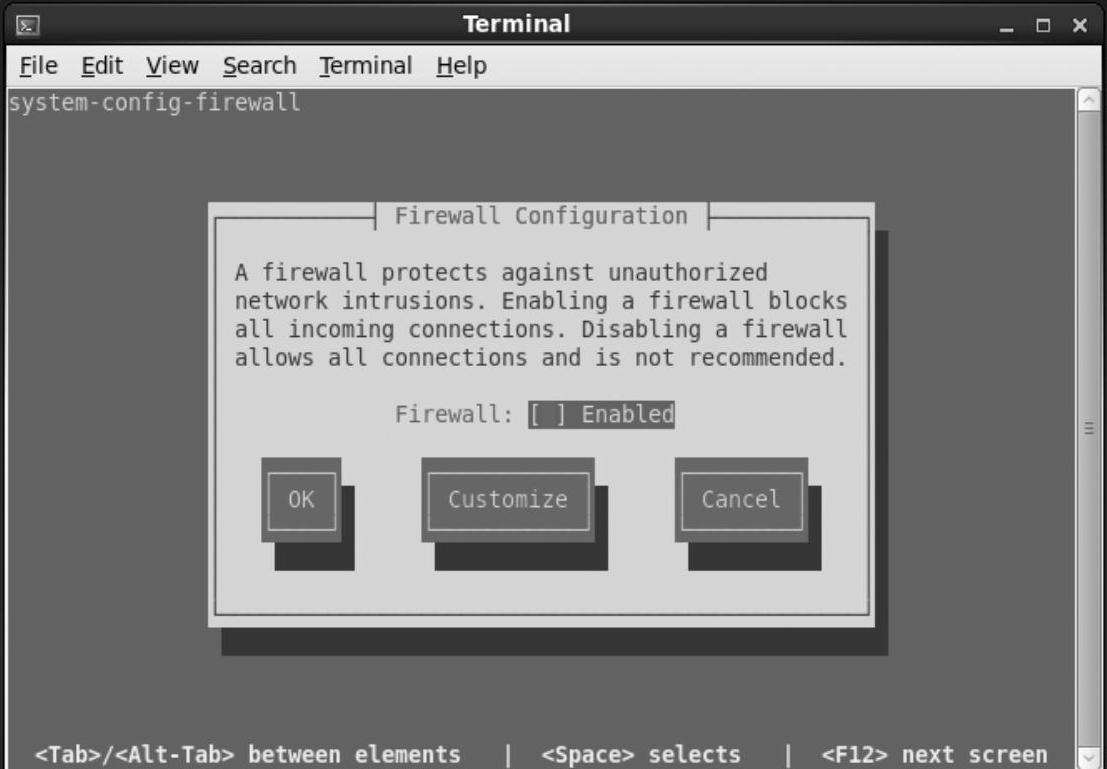
图1-19 Firewall配置
关闭Linux的防火墙以后,要验证一下:在shell提示符下输入service iptables status,若提示iptables:Firewall is not running.说明防火墙已经关闭。

(2)配置DNS地址解析
在Hadoop中,主机之间通过域名进行访问,需配置DNS(Domain Name System)域名系统hosts的域名解析。
1)使用PieTTY远程连接工具,登录到Linux远程虚拟机。
2)输入#vi/etc/hosts,打开hosts文件。
3)Vi打开时,输入I(i)使vi进入文本输入模式,在vi文本输入模式中,在文件的最后增加192.168.2.100 Master,然后在vi中按Esc键,输入:wq!,保存并退出。
4)输入#cat/etc/hosts,查看已经修改的hosts文件。

(3)配置SSH免密码登录
Hadoop的进程之间通信使用SSH方式,SSH方式每次都需要输入密码。为了减少Ha⁃doop安装时的密码输入操作,这里先配置SSH实现免密码登录。
1)输入#ssh-keygen-t rsa命令生成密钥,命令中的rsa表示使用RSA加密方式生成密钥,如果之前已经配置过ssh rsa,输入y并确认覆盖原文件即可;如果之前没有配置过ssh rsa,则根据提示一直按Enter键确认即可。

2)输入#cd/root/.ssh命令,使用#ls-l查看生成的密钥文件。

3)输入#cp id_rsa.pub authorized_keys命令生成认证文件,如果之前已经配置过ssh rsa,已经有了authorized_keys文件,输入y并确认覆盖原文件;如果之前没有生成author⁃ized_keys文件,直接复制即可。

4)测试验证一下,输入#ssh Master,可以直接登录Linux系统,说明ssh免密码登录已经配置完成。

2.Hadoop安装 在Linux中完成了防火墙的关闭、DNS域名的解析、SSH的免密码登录的准备工作,接下来就开始Hadoop的安装。
Hadoop有3种安装方式,分别是本地模式、伪分布模式、集群模式。本地模式是Ha⁃doop在本地计算机上运行;伪分布模式是Hadoop在一台计算机上模拟分布式部署,学习和测试Hadoop很方便;集群模式是在多台计算机上配置Hadoop。因为在VMware Workstation 虚拟机上只有一台Linux虚拟机,所以这里使用伪分布方式安装Hadoop。
(1)Hadoop的下载
进入Hadoop的镜像下载页面,下载hadoop-2.6.0.tar.gz版本(http://mirrors.cnnic. cn/apache/hadoop/common/hadoop-2.6.0/),在网页上单击hadoop-2.6.0.tar.gz进行下载,如图1-20所示,将其保存到Windows本地目录。
图1-20 Hadoop下载页面
(2)将文件传送至虚拟机
下载hadoop-2.6.0.tar.gz安装包到Windows本地目录,使用WinSCP文件传输工具将hadoop-2.6.0.tar.gz从本地Windows传送到远程虚拟机系统;打开WinSCP工具,连接Linux虚拟机,复制到/usr/local/setup_tools目录。
使用PieTTY远程连接工具,登录到Linux远程虚拟机,输入cd/usr/local/setup_tools命令进入setup_tools目录,输入ls命令,查看hadoop-2.6.0.tar.gz文件是否已经传到了远程虚拟机上。

(3)解压安装
输入#tar-zxvf hadoop-2.6.0.tar.gz命令,对hadoop-2.6.0.tar.gz进行解压缩。
将hadoop-2.6.0.tar.gz解压到hadoop-2.6.0目录以后,使用ls命令查看当前目录下hadoop-2.6.0.tar.gz是否已经解压完成,使用#mv hadoop-2.6.0 /usr/local命令将ha⁃doop-2.6.0目录从当前目录/usr/local/setup_tools复制到/usr/local目录中。

(4)配置Hadoop的全局环境变量(www.daowen.com)
输入名称#vi/etc/profile,打开profile文件,输入I(i)可以进入文本输入模式,在profile文件的最后增加HADOOP_HOME及修改PATH的环境变量,然后在vi中按Esc键,输入:wq!,保存并退出。

(5)环境变量配置生效
在命令行中输入source /etc/profile,使刚才修改的HADOOP_HOME及PATH配置文件生效。

(6)hadoop-env.sh配置文件修改
在命令行输入#cd/usr/local/hadoop-2.6.0/etc/hadoop,进入Hadoop的配置文件目录,输入名称#vi hadoop-env.sh,打开hadoop-env.sh文件,输入I(i)可以进入文本输入模式,在hadoop-env.sh文件中,增加JAVA_HOME环境变量配置,然后在vi中按Esc键,输入:wq!,保存并退出。

(7)core-site.xml核心配置文件修改
在命令行输入#cd/usr/local/hadoop-2.6.0/etc/hadoop,进入Hadoop的配置文件目录,输入名称#vi core-site.xml,打开core-site.xml文件,输入I(i)可以进入文本输入模式,在core-site.xml文件中,配置相关参数,然后在vi中按Esc键,输入:wq!,保存并退出。


(8)hdfs-site.xml配置文件修改
在命令行输入#cd/usr/local/hadoop-2.6.0/etc/hadoop,进入Hadoop的配置文件目录,输入#vi hdfs-site.xml,打开hdfs-site.xml文件,即Hadoop分布式文件系统(Hadoop Dis⁃tributed File System,HDFS),输入I(i)可以进入文本输入模式,在hdfs-site.xml文件中,配置相关参数,然后在vi中按Esc键,输入:wq!,保存并退出。HDFS存储备份一般3个存储节点做一个集群,存储备份设置为3,这里测试使用1台虚拟机,因此设置dfs.replication的值为1。

(9)格式化HDFS文件系统
Hadoop的文件系统是HDFS,第一次使用之前需进行文件系统格式化。使用#cd/usr/local/hadoop-2.6.0/bin命令进入Hadoop的bin目录,然后输入#hdfs namenode-format命令,进行文件系统格式化。


(10)启动Hadoop系统
输入#start-all.sh命令,启动Hadoop的所有相关进程。

输入#jps命令,查看Hadoop相关的5个进程是否全部启动起来,若是则说明Hadoop启动成功。

(11)以Web方式查看Hadoop系统
启动Hadoop后,在Windows本地计算机上(192.168.2.1)上打开Web浏览器,在浏览器中输入Hadoop的URL:http://192.168.2.100:50070就可以查看Hadoop系统的相关信息。
至此,Hadoop伪分布式安装全部完成,如图1-21所示。
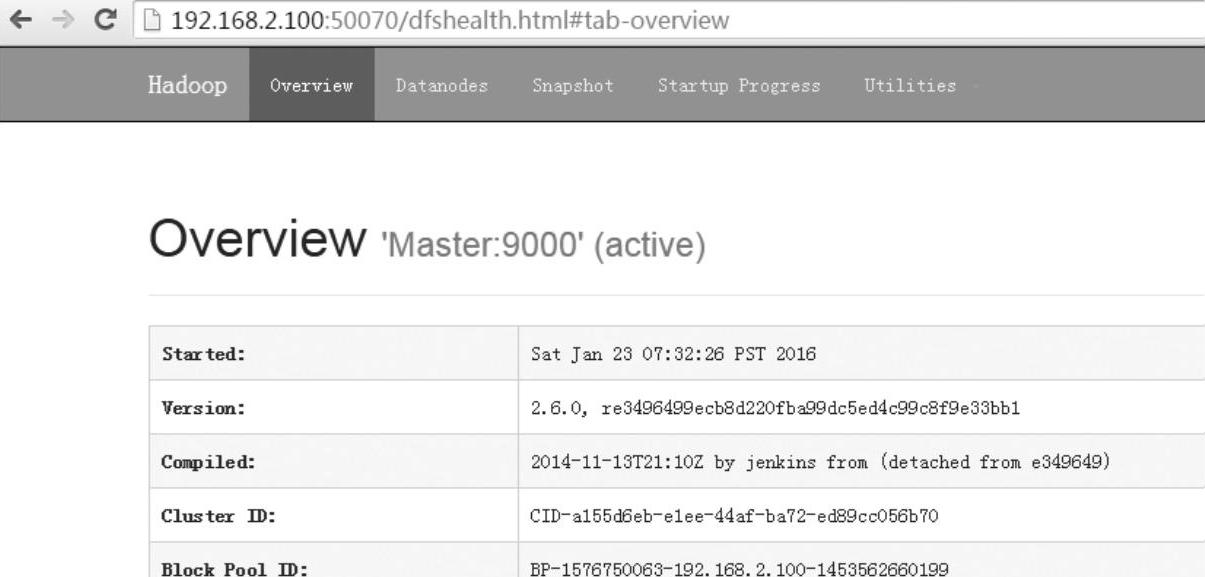
图1-21 以Web方式查看Hadoop
(12)关闭Hadoop系统
使用#stop-all.sh命令关闭Hadoop所有相关进程。

3.Hadoop MapReduce词频统计实例 在Hadoop系统中,使用Hadoop系统自带的MapReduce工具,对上传到Hadoop HDFS系统的文本文件进行词频统计,即统计每个单词出现了多少次。
(1)从Linux上传文件到HDFS文件系统
输入#cd/usr/local/hadoop-2.6.0命令,进入Hadoop目录,查看目录下是否有一个README.txt文本文件,将README.txt文件作为词频统计的样本。

输入#hadoop fs-put README.txt/命令,将虚拟机Linux上的README.txt文件通过hadoop fs–put命令传送到Hadoop HDFS文件系统的根目录下,然后使用hadoop fs-ls/命令查看是否上传成功。

(2)运行MapReduce词频统计
输入#cd/usr/local/hadoop-2.6.0/share/hadoop/mapreduce命令,进入Hadoop目录。
输入#hadoop jar hadoop-mapreduce-examples-2.6.0.jar wordcount/README.txt/word⁃countoutput命令。

运行Hadoop词频统计分析,结果如下:


(3)查看MapReduce统计输出的文件
输入#hadoop fs-ls/wordcountoutput命令,查看输出文件。

(4)查看MapReduce词频统计结果
输入#hadoop fs-cat /wordcountoutput/part-r-00000命令,至此,Hadoop的第一个运行程序已经完成。

免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






