1.端口是应用层与运输层之间的接口——服务访问点(SAP)。应用层运行着各种服务和应用程序如QQ、网页浏览器等,运输层通过端口号把来自网卡的数据送给不同的应用程序。常用服务和应用程序被分配一些固定的端口号,例如,HTTP服务端口号是80、FTP服务端口号是21、远程桌面连接的端口号是3389等。通常1~1024的端口号——熟知端口被分配为一些系统服务和常用的应用程序。因此用户在编写应用层的程序时,如果需要用到端口号,一般端口号应大于1024,以防止和别的应用程序和服务发生冲突。端口号在1024~49151之间的为注册端口。端口号在49152~65535之间的为动态端口,之所以称为动态端口是因为它只在系统进程或应用程序需要进行网络通信时才分配,且必须向系统申请,当进程关闭,就会释放所占用的端口号。
2.通常都使用域名访问网站,当不能访问时,一般用ping命令测试连通性,如果能ping通,就使用网站的IP地址来访问网站,能访问则肯定是域名服务器出现了问题。这次百度不能访问,不是百度网站本身被黑,而是其域名解析服务器被黑,而百度的域名服务器又远在美国,造成恢复困难。这说明了域名服务器是互联网的薄弱环节,尤其是控制了根域名服务器就控制了整个互联网,而整个亚洲只有一台辅根服务器放在日本,中国只有根服务器的镜像。
3.绝大多数情况下,DNS数据报使用UDP传输,UDP数据报的长度有限,如果出现DNS应答报文设置了被截断标志,就需要以TCP方式再次传输请求报文。例如,当报文内容大于512字节时就会出现这种情况。这也说明了为什么DNS既有UDP熟知端口53,也有TCP熟知端口53。
4.为了提高域名解析效率,域名服务系统提供了两方面的优化:复制和高速缓存。
复制是指在每个主机上保留一个本地域名服务器数据库的副本。由于不需要任何网络交互就能进行转换,复制使得本地主机上的域名转换非常快。同时,它也减轻了域名服务器的计算机负担,使服务器能为更多的用户提供域名解析服务。
高速缓存是比复制更重要的优化技术,它可使非本地域名解析的开销大大降低。网络中每个域名服务器都维护一个高速缓存器,由高速缓存器来存放用过的域名和从何处获得域名映射信息的记录。当客户机请求服务器转换一个域名时,服务器首先查找本地域名-IP地址映射数据库,若无匹配地址则检查高速缓存中是否有该域名最近被解析过的记录,如果有就返回给客户机,如果没有才应用某种解析方式或算法解析该域名。为保证解析的有效性和正确性,高速缓存中保存的域名信息记录设置有生存时间,这个时间由响应域名询问的服务器给出,超时的记录就将从缓存区中删除。
5.直观来说,当用户输入正确的域名但是并没有打开正确的网站而是别的页面,那么说明用户遭受了DNS欺骗攻击。从原理上来说,是欺骗者冒充本地域的DNS服务器返回给用户伪造的域名解析信息(即DNS响应数据包)。如果欺骗者要发送伪造的DNS响应数据包必须伪造正确DNS数据包标识字段,在局域网内,通过网络探测软件就可以检测到DNS查询数据包的标识字段。
6.DDNS(Dynamic(Update)Domain Name System)是将用户的动态IP地址映射到一个固定的域名解析服务上,用户每次连接网络的时候,客户端程序就会通过信息传递把该主机的动态IP地址传送给位于服务商主机上的服务器程序,服务器程序负责提供DNS服务并实现动态域名解析,DDNS的主要作用如下。
1)宽带运营商大多只提供动态的IP地址,DDNS可以捕获用户每次变化的IP地址,然后将其与域名相对应,这样其他上网用户就可以通过域名来与用户交流。
2)DDNS可以帮你在自己的公司或家里构建虚拟主机。
3)解决IP地址缺乏的问题,用名字来标识用户,用户更换IP,但是标识可以保持不变。
7.SMTP是6个回合:HELO命令、MAIL、RCPT、DATA命令、QUIT;ESMTP是7个回合:EHLO命令、AUTHLOGIN、MAIL、RCPT、DATA命令、QUIT;SMTP与ESMTP相比仅仅多了一个用户认证回合。
8.IMAP4可以选择下载邮件的主题或全部内容,而POP3默认是将邮件的全部内容下载到本地脱机进行操作,用户对邮件的处理不影响POP3服务器上用户的邮件。
9.VRFY是用来验证收件人的邮件地址是否正确,如果想看收件人的别名可以使用EX-PN。实际的邮件系统往往禁用VRFY和EXPN命令,因为VRFY和EXPN往往为垃圾邮件发送者提供了方便。另外,VRFY命令会返回250(地址存在)和557(地址不存在)的信息,这样就可以尝试收集E-mail地址,很容易导致暴力攻击。
10.用户代理主要用来交付、读取和处理邮件,其主要功能如下。
1)发件撰写。给用户提供人性化的撰写邮件的UI(用户界面)。
2)信件显示。对邮件内容进行解码,显示给用户。
3)信件处理。用户可以对信件进行各种处理,如删除、保存等。
4)交付和读取邮件。使用SMTP将邮件发送给它的邮件服务器,使用POP或者IMAP从用户所属的邮件服务器读取邮件。
11.首先分成6bit的形式:010010 001011 110000 110101,查表得到对应的Base64编码为:SLW1。
12.FEAT命令并不在RFC959中定义,而是在RFC2389中定义。用来请求FTP服务器列出它所有的扩展命令与扩展功能,属于主动模式命令,例如,使用FEAT命令的交互过程如下。

FEAT命令在安全方面存在隐患,因为通过这个命令就可以获得服务器可能提供的服务,在一定程度上来讲可能打开了更多的风险因素,所以防火墙和FTP服务器本身都会非常小心地处理这个命令。
13.NVT-ASCII(网络虚拟终端ASCII码),NVT是一种通用的字符终端,叫网络虚拟终端。客户和服务器用它来建立数据表示和解释的一致性。而NVTASCII码则是用来替代ASCII码在客户和服务器间传输的编码形式。NVTASCII码的构成:NVTASCII代表7位的ASCII字符集,网间协议族都使用NVTASCII。每个7位的字符都以8位格式发送,最高位为0。行结束符以两个字符CR(回车)和紧接着的LF(换行)这样的序列表示,以\r\n表示。单独的一个CR也是以两个字符序列来表示,它们是CR和紧接着的NUL(字节0),表示为\r\0。在TCP/IP协议中,NVTASCII码具有广泛的应用。文本文件通常转换成NVTASCII码形式在数据连接中传输,Telnet、FTP、SMTP、Finger和Whois协议都以NVT ASCII来描述客户命令和服务器的响应。
14.万维网使用统一资源定位符(URL)来标识万维网上的各种文档,并使每个文档在整个万维网上具有唯一的标识符,如万维网上链接http://www.w3.org/Protocols/Activity.html。
15.依次发生的事件如下。
1)浏览器分析链接指向页面的URL。
2)浏览器向DNS请求解析www.w3.org的IP地址。
3)DNS解析出服务器的IP地址为18.23.0.23。
4)浏览器与服务器建立TCP连接。
5)浏览器发出取文件命令:GET/Protocols/Activity.htmll。
6)www.w3.org服务器给出响应,将文件test.html.发送给浏览器。
7)释放TCP连接。
8)浏览器显示文件Activity.html中的所有文件。
16.在学习各种协议消息格式时,经常会遇到保留字段。保留字段一般是在协议改进时才用到。因为开发协议时考虑往往不够周全,待以后有新的想法时或新的需要时,可以通过启动保留字段来进行补充升级,避免重新编写协议。有趣的是,在协议的实际发展过程中,增加功能时,常常修改或借用其他字段,而保留字段常常一直保留到协议淘汰。
17.当前浏览器的内核主要有4个,分别是Trident、Gecko、WebKit和Presto。IE(也包括基于IE内核的浏览器,如遨游、世界之窗)的内核是Trident;Firefox的内核是Gecko;Safari和Chrome的内核是WebKit;Opera的内核是Presto。
18.RMON(Remote Network Monitoring)远端网络监控,最初的设计是用来解决从一个中心点管理各局域分网和远程站点的问题。RMON规范是由SNMPMIB扩展而来。RMON中,网络监视数据包含了一组统计数据和性能指标,它们在不同的监视器(或称探测器)和控制台系统之间相互交换。结果数据可用来监控网络利用率,以用于网络规划,性能优化和协助网络错误诊断。
RMON标准使SNMP更有效、更积极主动地监测远程设备,网络管理员可以更快地跟踪网络、网段或设备出现的故障。RMONMIB的实现可以记录某些网络事件,可以记录网络性能数据和故障历史,可以在任何时候访问故障历史数据以有利于进行有效地故障诊断。使用这种方法减少了管理工作站同代理(Agent)间的数据流量,使简单而有力地管理大型网络成为可能。
19.SNMP采用UDP协议而不采用TCP协议,是因为UDP效率较高,这样实现网络管理不容易增加网络负载,但是由于UDP是不可靠的,因此很容易造成SNMP报文的丢失,为此,SNMP实现的建议是对每个管理信息都要装配成单独的数据包独立发送,而且报文应该短些,最好不超过484字节。
20.抽象语法表示(Abstact Syntax Notation One.1,ASN.1)是一种形式语言,它有严格的巴科斯范式(Backus-Naur Form,BNF)定义。在电信和计算机领域,主要用于定义应用程序数据和表示协议数据单元的抽象语言,适于描述复杂的、变化的、可扩展的数据结构。SNMP管理信息库也是用ASN.1定义的。ASN.1本身只定义了信息的抽象表示方法,但是没有限定其编码规则,各种编码规则提供了由ASN.1定义的应用数据的传送方法,标准的ASN.1编码规则有基本编码规则(Basic Encoding Rules,BER)、规范编码规则(Canonical Encoding Rules,CER)等,而当前常用的是BER编码方法。
描述ASN.1记法的标准有ITU-TRec.X.680和ITU-TRec.X.681,描述BER编码规则的标准为ITU-TRec.X.690。
ASN.1中,一个数据类型就是值的一个集合。有些数据类型有有限个值,有些则有无限多个。一个给定的ASN.1类型的值是该类型集合里的一个元素。ASN.1定义了如下4种数据类型。
1)简单类型。由单一元素构成的原子类型。
2)构造类型。有组成部分。
3)标签类型。由已知类型定义的新类型。(www.daowen.com)
4)其他类型。包括CHOICE和ANY类型。
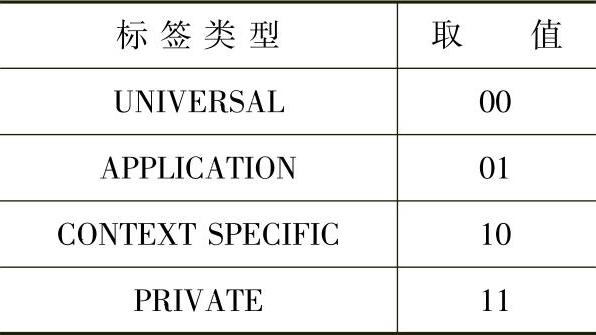
可以使用ASN.1的分配符(::=)给类型和值指定名字,这些名字可以用于定义其他类型或值。除了CHOICE和ANY类型以外,每种ASN.1类型都有一个标签,标签有类型和值。标签值用于唯一区分ASN.1类型。在ASN.1中定义了以下4类标签。
1)UNIVERSAL。这种数据类型是有标准(如X.802)定义的。
2)APPLICATION。该类型的含义由具体的应用决定,如X.500目录服务。
3)PRIVATE。该类型的含义根据给定的企业不同而不同。
4)Context-specific。该类型的含义根据给定的结构类型而不同。
附表7-1列出了一些数据类型以及所属的标签。
附表7-1 ASN.1定义的通用数据类型

ASN.1类型和值使用一种灵活的、类似编程语言的符号表示,这种规则叫做文本约定。
1)分层(换行)是无意义的,多个空格和多个空行相当于一个空格。
2)注释由一对连字符(——)开头,或者一对连字符和一个空行。
3)标识符(值或字段的名字)、类型索引(类型的名字)和模块名由大小写字母、数字、短线组成;标识符由小写字母开头,类型索引和模块名由大写字母开头。
4)关键字和ASN.1定义的内部类型全部用大写字母表示。
以下是表中数据类型的详细描述。
1)简单类型。简单类型没有组件,是“原子级”的类型,这些类型的共同特点是可以直接定义它们的值的集合,也可以把简单类型作为原子类型构造新的数据结构。在ASN.1中,简单类型分为两类:string类和non-string类,其中BIT STRING(0或者多个比特组成的序列)、IA5String(由IA5(ASCII)字符任意组成的字符流)、OCTET STRING,(任意的OCTER(8bit值)流)、PrintableString(任意的可打印字符流)和UTCTime(时间)是string类型。String类型可以指定大小限制,以限制值的长度。
2)构造类型。构造类型有组成部分,大体上分为序列和集合两种。ASN.1定义了4种:SEQUENCE、(一个或多个类型的有序集合)、SEQUENCE OF(0个或某个给定类型多次出现的有序集合)、SET(一个或多个类型的无序集合)、SET OF(0个或某给定类型多次出现的无序集合)
3)标签类型。虽然ASN.1的数据类型都带有标签,这里的标签指的是应用或用户加在某个类型上的标签,它可以是一个类型有多个类型名。标签类型可以是隐式(IMPLICIT)的和显式(EXPLICIT)的。隐式标签类型是在其他类型基础上通过改变其下层类型的标签生成的;显式标签是在其他类型基础上通过在其下层类型的标签之外添加一个外层标签生成的。从效果上看,显式标签类型是包含一个组件的结构类型,该组件即下层类型。
从编码的角度看,隐式标签类型可视为与下层类型相同,除非标签不同。显式标签类型可视为有一个组件的结构类型,该组件即为下层类型。隐式标签可以使编码较短,但是如果下层类型是不确定的,显式标签必须避免含糊不清(例如,下层类型是CHOICE或ANY)。
4)其他类型。ASN.1中的其他类型包括CHOICE和ANY类型。CHOICE类型表示一个联合体,它具有一个或多个备选项(Alternative);ANY类型表示任意类型的任意值,其中任意类型可能在使用对象识别符或整数值注册中定义。
21.基本编码规则(BER)把ASN.1表示的抽象类型值编码为字节串,这种字节串结构为类型-长度-值,英文简称为TLV(Type-Length-Value),一般类型和长度的字节数固定,而且编码值部分还可以递归地再编码为TLV结构。
一般的编码的规则如下:
1)编码的第一个字节用于表示类型,前两位用于区分4种标签,第三位用于区分简单类型和构造类型,剩余5位用于表示标签值。
2)编码的第二个字节一般表示编码的长度。
3)剩下的表示编码数据,可以递归地再编码为TLV结构。
4)默认情况下,编码的第一个字节的剩余五位表示标签值,总共可以表示0~31(注:28以后的保留未用),若标签值大于30时需要扩充,扩充方法如下:编码第一个字节的剩余5位全为1,作为转义符,实际的标签编码表示在后续字节,后续字节的左边第一位表示是否为最后一个扩充字节,只有最后一个扩充字节的左边第一位置为0,其余扩充字节的左边第一位置1,即每个扩充字节只用了7位表示标签值的编码,且扩充的比特位数非7的整数倍时,遵循右对齐的原则。
5)默认情况下,仅用1字节表示长度,长度小于127时仅用长度字节的右边7位表示,最左边一位置0。长度大于等于127时,用后续的若干字节表示,原来长度字节的第一位置1,其余7位用于指明后续用于表示长度的字节数。
附表7-2和附表7-3为BER编码第一个字节各部分取值表
附表7-2 前两位取值表
附表7-3 第三位取值表

【例1】布尔类型有两个值FALSE和TRUE,都用一个字节表示,FALSE是00,TRUE是FF,试写出TRUE和FALSE的BER编码结果?
在所有类型中,除了UNIVERSAL 16和UNIVERSAL 17外都是简单类型,所以布尔类型也是简单类型,因此传输编码的第三位取值为0,布尔类型的标签为UNIVERSAL 1,因此前两个比特取值为00,剩余五位取值为00001。所以FALSE的编码为0000 0001 0000 0001 0000 0000(01 01 00),TRUE编码为0101FF。
【例2】比特串10001在传输时要占用1字节(即长度为1个字节),5比特靠左存放,右边3位未用,因此编码时需要再用一字节说明未使用的比特数,那么对比特串10101的编码结果?
同例1中的分析,编码结果为0000 0011 0000 0010 0000 0011 1000 1000(03 02 03 88)。
22.SNMP使用ASN.1传送信息。若使用ASN.1编码,整数用7个比特放不下,因此它需要14个比特,表示成14bit的数字,200是00000011001000。以ASN.1传送每个值,无论是基本类型还是构造类型,都有可能由3个域组成:标识符(类型和标签)、数字字段按字节计算的长度、数据字段。由于这里发送的第一个字节是标签,然后是长度,接着是200的值,每个字节包含7bit,第一个字节的高序位置1,因此发送的4字节是:00000010 00000010 10000001 01001000。
23.对序列编码,BER需要采用递归编码方法,编码方法步骤如下。
1)传输第一个字节(类型):0011 0000。
2)传输第二个字节为长度,应该为后面的总长度,所以最好先计算后面的编码数据部分,计算结果为6,编码:00000110。
3)传输的第三部分,需要采用递归方法,对序列的组成部分采用TVL编码。
FALSE:0000 0001 0000 0001 0000 0000。
62:0000 0010 0000 0001 0011 1110。
最后编码组合结果:300601010002013E,特别需要注意的是递归部分的编码顺序,因为是序列,所以是有顺序的,反之,如果是集合,则无需注意顺序了。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





