网络传输数据包时,先把数据包变成字节流,再把字节流变成比特流。从字节变成比特流由硬件负责,每个字节一般先从最低位发送。编程要考虑的是各字段中的每个字节的顺序以及编程语言在处理字段内容时的字节顺序,如存放在内存时的字节顺序。因此编写程序时要考虑网络字节顺序与主机字节顺序的匹配问题,这些都是编写网络程序时需要注意的地方。
1.字节对齐与内存对齐
许多计算机系统对基本数据类型在内存中存放的位置都有明确的规定,它们会要求这些数据的首地址的值是某个数k的倍数,这就是所谓的内存对齐,而这个k则被称为该数据类型的对齐模数。
编写的程序在实际运行之前要先经过编译,在Win32平台下的微软C/C++编译器在默认情况下采用如下的对齐规则:任何基本数据类型的对齐模数就是这种数据类型所占的字节数。比如对于double类型(8字节),就要求该类型数据的地址总是8的倍数,而char类型数据(1字节)则可以从任何一个地址开始。
那么什么是字节对齐呢?这与网络程序有什么关系呢?网络程序是用来处理网络数据的,网络数据是一个一个的帧,每个字段都表示不同的含义,那么在程序中该如何表示这个数据帧呢?数据帧通常是使用结构来表示的,在C/C++语言中,结构是一种复合数据类型,其构成元素既可以是基本数据类型(如int、long、float等)的变量,也可以是一些复合数据类型(如数组、结构、联合等)的数据单元。因此,在结构中可以定义不同类型的变量,不同的变量存储不同的字段,那么结构这种复合数据类型在内存中是如何被编译器处理的呢?
字节对齐方式就是结构中的各个变量在内存中的摆放方式。在结构中,编译器为结构的每个成员按其对齐模数分配空间。各个成员按照它们被声明的顺序在内存中顺序存储,第一个成员的地址和整个结构的地址相同。
例如,自定义结构test中的各成员空间分配情况如下:

结构的第一个成员t1是字符型,其偏移地址(与整个结构地址之间的偏移量)为0,占据了第1字节;第二个成员t2为short类型,其起始地址必须2字节对齐(对齐模数为2),因此,编译器在t2和t1之间填充了一个空字节;结构的第三个成员t3和第四个成员t4恰好落在其自然对齐地址上,在它们前面不需要额外的填充字节。在test结构中,成员t3要求4字节对齐,是该结构所有成员中要求的最大对齐单元,因而test结构为4字节对齐,并且整个结构的长度(占据内存字节数)必须是对齐字节数的倍数,因此,编译器在成员t4后面填充了3个空字节,整个结构所占据空间为12字节。
知道了字节对齐方式,再来分析网络数据帧的问题,由前面的分析可知,同一个结构中的不同变量之间在存储时是有空隙的,然而实际的数据帧不同字段之间是连续的、没有间隔的,那么将数据帧直接存储在结构中就会发生不易察觉的错误,因为不同的字段并不能与结构中的某个变量完全对应,那么如何解决这个问题呢?
第一个办法是手动修改编译器的默认对齐规则,VC++6.0中的编译选项共有5种对齐方式:/Zp[1|2|4|8|16],/Zp1表示以1字节对齐,相应的,/Zpn表示以n字节对齐。要使用这个选项,可以在VC6中打开工程属性页(Project→Settings),C/C++页,选择Code Generation分类,在Struct member alignment中可以选择,默认为8字节对齐方式。
n字节对齐的意思是说,一个成员的地址必须安排在成员的尺寸(数据类型所占字节的个数)的整数倍地址上或者是n的整数倍地址上,取它们中的最小值,也就是min(sizeof(member),n)。如果n取1,那么就表示结构中的变量之间是没有空隙的。
需要特别注意的是:/Zpn选项是应用于整个工程的,影响所有的参与编译的结构,当然也包括工程中包含的头文件中定义的结构,因此,修改这个默认选项会导致一些不必要的麻烦,因为编程时并不想修改系统预定义的结构对齐方式,只想让自己定义的结构能够1字节对齐,因此,要专门针对某些结构定义使用对齐选项,较常用的是使用#pragma pack编译指令。#pragma pack的使用方法如下。(https://www.daowen.com)
1)#pragma pack(n)。该指令指定结构的紧凑程度,在其出现后的第一个结构说明处生效,该编译指示对定义无效。当使用#pragma pack(n)时,n为1、2、4、8或16。在该编译指令后定义的所有结构的成员都被存储在最小的成员类型或n字节界限内,n通常取1。直到遇到#pragma pack()编译指令。
2)#pragma pack()。该指令表示由#pragma pack(n)定义的结构字节对齐方式失效,以后的结构恢复为默认设置。通常这两个指令一起使用,分别放在自定义结构的开始和结束。
在网络协议编程中,经常会处理不同协议的数据报文。通常的做法是定义自己的协议结构,通过访问结构的成员来获取各种信息。这样做,不仅简化了编程,而且即使协议发生变化,也只需修改协议结构的定义即可,其他程序无需修改。下面以IP协议首部为例,说明如何定义协议结构。

2.字节顺序
在网络通信过程中,字节顺序是十分重要的概念,如果不了解这个问题,在实际编写程序过程中就会出现不易察觉的错误。什么是字节顺序呢?先看一个例子,假设现在有一个int类型的变量,它的值是0x7788,那么它的值在内存中可以有图10-3所示的两种不同的存放方式。
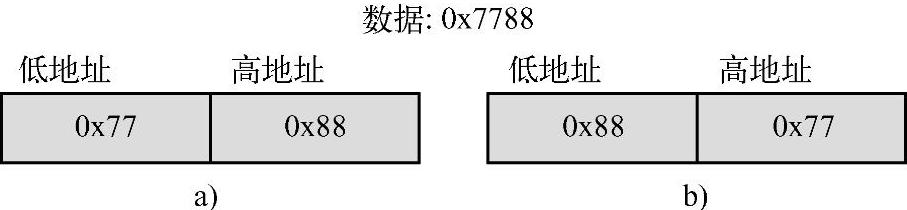
图10-3 字节顺序示例
a)网络字节顺序 b)生机字节顺序
对于不同的CPU、不同的操作系统,图10-3中的两种字节顺序都是有可能的。如果将16位整数的高字节存储在内存的低地址端,低字节存储在内存的高地址端,这种方式称为big-endian字节序,如图10-3a所示;如果将16位整数的高字节存储在内存的高地址端,低字节存储在内存的低地址端,这种方式称为little-endian字节序,如图10-3b所示。
目前一般的计算机(Intel、AMD等x86CPU)采用little-endian字节顺序,也称为主机顺序,而TCP/IP通信使用的是big-endian字节顺序,也称为网络顺序,因而存在一个不同字节顺序之间相互转化的问题,这在处理网络数据包时十分重要。一般的操作过程如下:发送端将本机的数据(占2字节或以上的数据类型)先转换成网络的字节顺序(调用API函数htons或htonl),然后再发送到网络;接收端接收网络数据后,先将数据转换成本机的字节顺序(调用API函数ntohs或ntohl),再进行其他操作。
上面提到的4个API函数ntohs、ntohl、htons、htonl,其中n代表网络(network);h代表主机(host);l代表长整型数(long);s代表短整型数(short)。举例说明,ntohs就是将16位的unsignedshort类型的数据从网络字节顺序转换成本机字节顺序,其他3个API函数含义类似。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。



