聚类分析(Cluster Analysis)是一组将研究对象分为相对同质的群组(Clus-ters)的统计分析技术。它将看似无序的对象进行分组、归类,以达到更好地理解研究对象的目的。下面结合实例,具体介绍用Origin进行聚类分析。试验数据3年期间美国城市的平均温度,存放在“US Mean Temperature.dat”数据文件中。试采用聚类分析对美国城市按纬度进行聚类分析。为找到最佳的聚类分析方法,先采用层次(Hierarchical)聚类分析对工作表中部分随机数据进行分析,而后采用K-means聚类分析对工作表所有数据进行聚类分析。
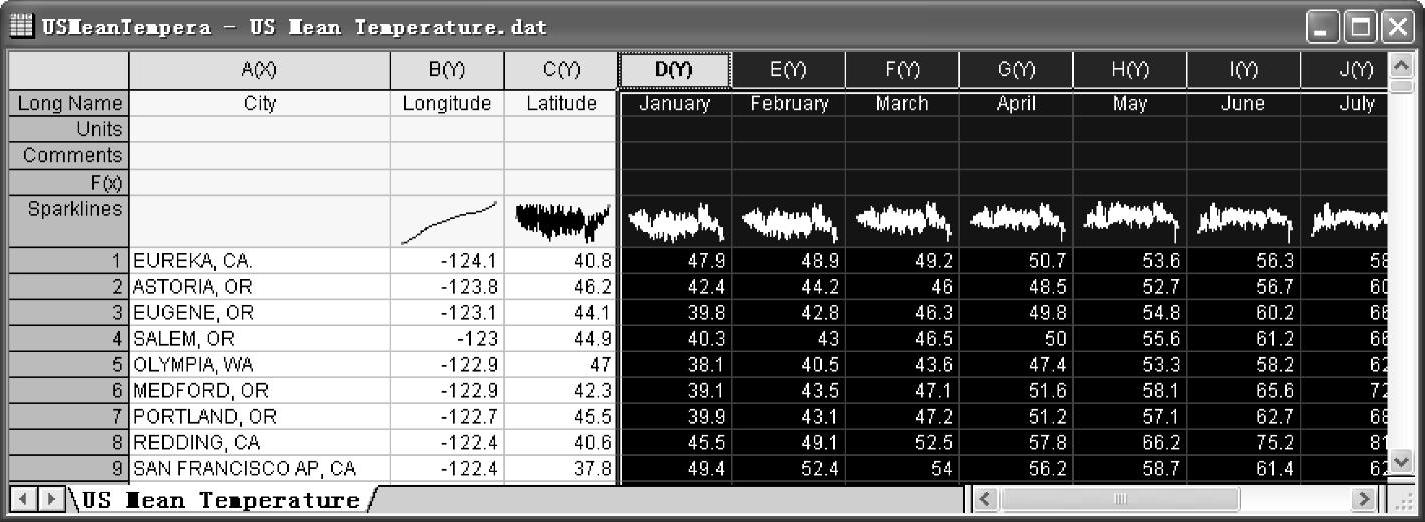
图12-88 “US Mean Temperature.dat”数据文件
1.层次(Hierarchical)聚类分析
(1)导入“Origin 9.1\Samples\Graphing\US Mean Temperature.dat”数据文件,如图12-88所示。工作表A(X)列为美国城市名称,B(Y)和C(Y)列分别为对应城市的经纬度,D(Y)~O(Y)列分别为对应城市的3年的月平均温度,P(Y)列为对应城市的3年的年平均温度。
(2)选中“US Mean Tem-perature.dat”工作表中D(Y)~O(Y)列,选择菜单命令【Statis-tics】→【Multivariate Analysis】→【Hierarchical Cluster Analysis】,打 开【Statistics/Multivariate A-nalysis:hcluster】对话框。
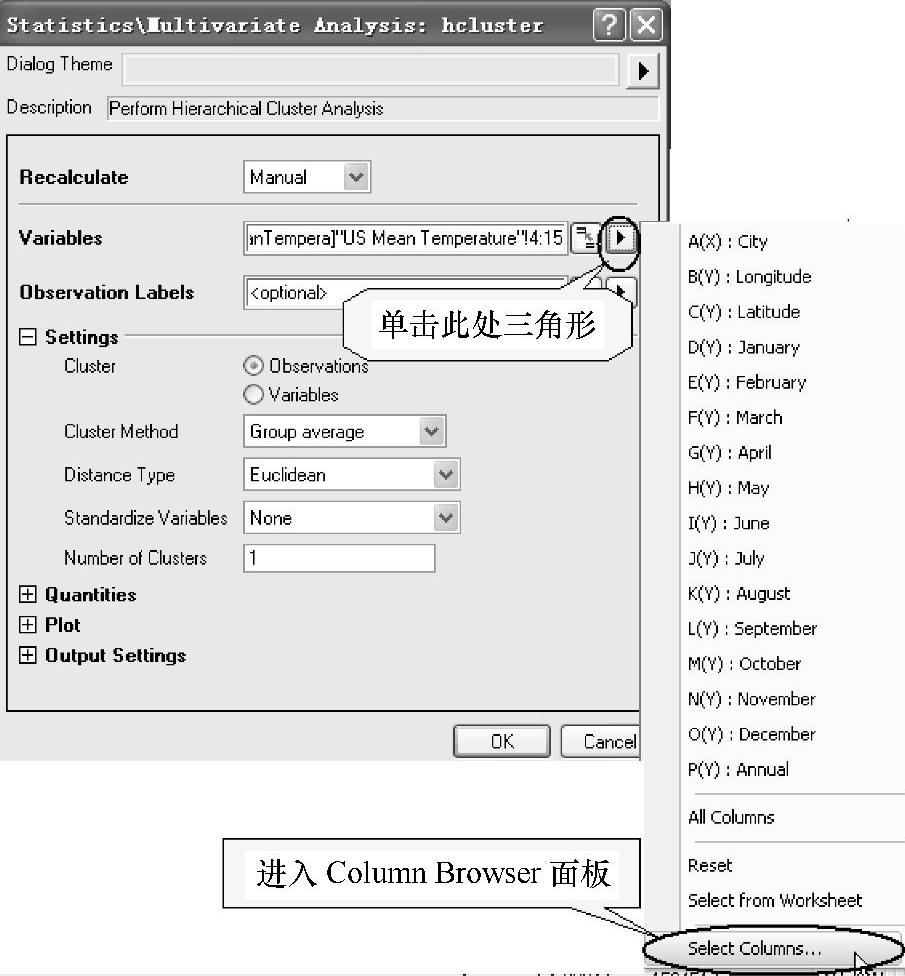
图12-89 【Statistics/Multivariate Analysis:hcluster】 对话框进入【Column Browser】面板
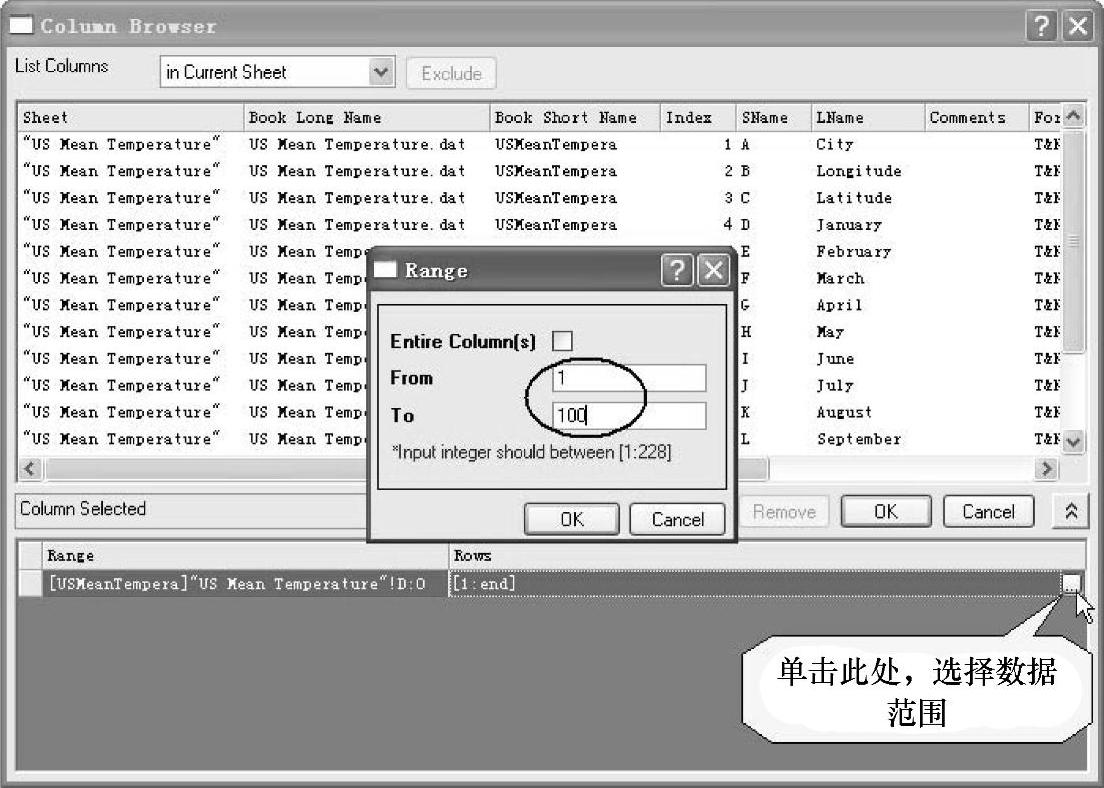
图12-90 【Column Browser】面板设置
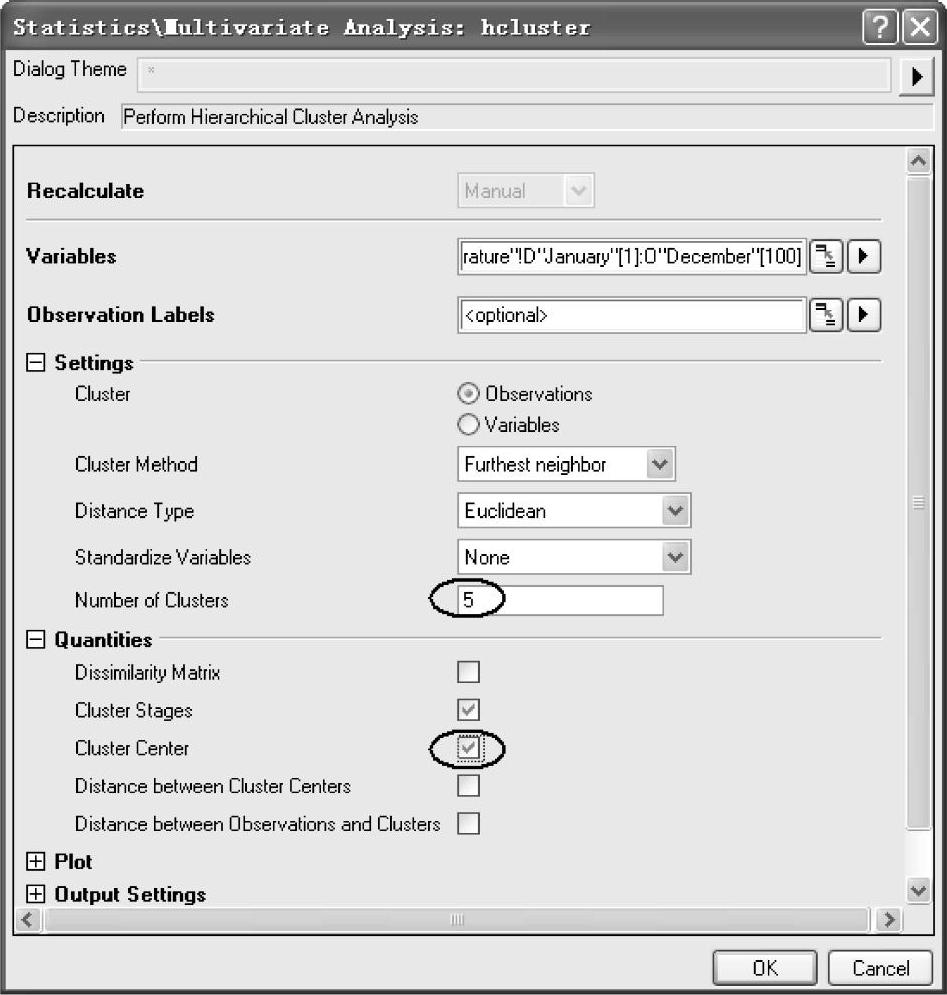
(3)单击【Statistics/Multi-variate Analysis:hcluster】对话框中“Variables”右边的三角形,选择“Select Columns”,如图12-89所示。打开【Column Browser】面板,单击【ColumnBrowser】下面板中右上角的 按钮,选择数据范围从“1”到“100”,如图12-90所示。单击“OK”按钮,回到【Statistics/Multivariate Analysis:hcluster】对话框。在“Settings”栏中的“Cluster”选中“Observations”复选框,“ClusterMethod”下拉列表框中选择“Furthest Neighbour”,在“Number of Clusters”中输入“1”。设置好的【Statistics/Multivariate Analysis:hcluster】对话框如图12-91所示。
按钮,选择数据范围从“1”到“100”,如图12-90所示。单击“OK”按钮,回到【Statistics/Multivariate Analysis:hcluster】对话框。在“Settings”栏中的“Cluster”选中“Observations”复选框,“ClusterMethod”下拉列表框中选择“Furthest Neighbour”,在“Number of Clusters”中输入“1”。设置好的【Statistics/Multivariate Analysis:hcluster】对话框如图12-91所示。
(4)单击“OK”按钮,进行层次聚类分析,得到聚类分析报告。双击该报告中的“Dendrogram”图例,得到图12-92所示图形。依据该图,认为合适的聚类数为“5”。
(5)因此按聚类数为“5”重新计算。单击图12-84中左上角的绿色锁 ,在打开的菜单中选择菜单命令“Change Parameters”,再次打开【Statistics/Multivariate Analy-sis:hcluster】对 话 框。在“Set-tings”栏下的“Number of Clusters”输入“5”,在“Quantities”中选中“Cluster Center”复选框。重新设置好的【Statistics/Multivariate Analy-sis:hcluster】对话框如图12-93所示。
,在打开的菜单中选择菜单命令“Change Parameters”,再次打开【Statistics/Multivariate Analy-sis:hcluster】对 话 框。在“Set-tings”栏下的“Number of Clusters”输入“5”,在“Quantities”中选中“Cluster Center”复选框。重新设置好的【Statistics/Multivariate Analy-sis:hcluster】对话框如图12-93所示。
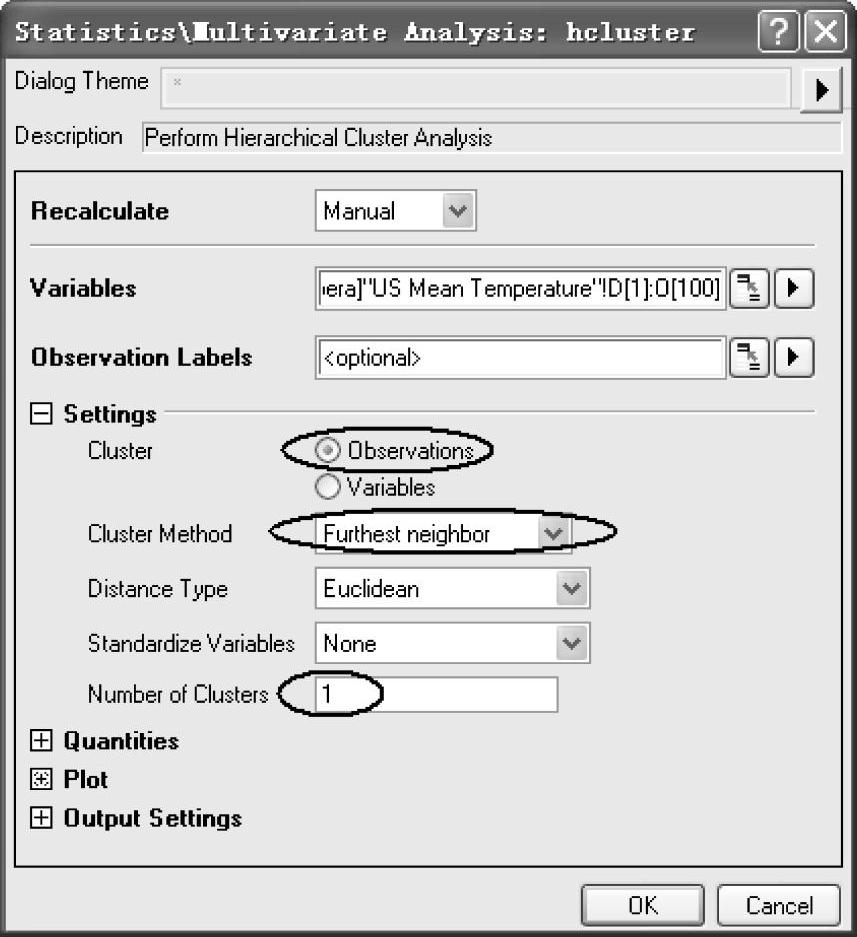
图12-91 设置好的【Statistics/Multivariate Analysis:hcluster】对话框
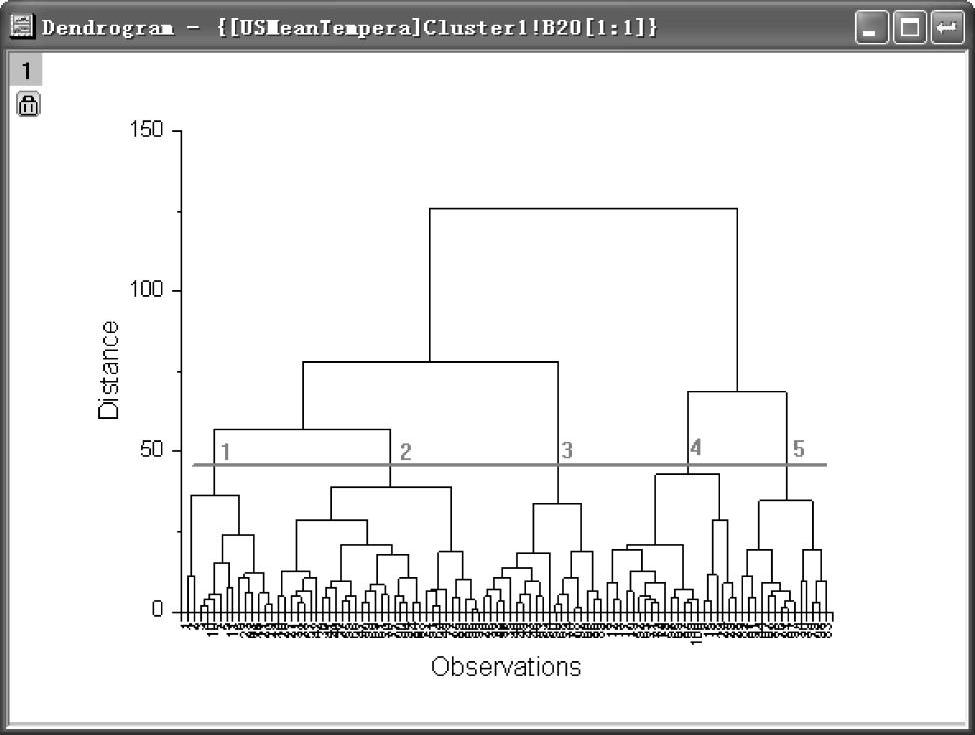
图12-92 “Dendrogram”图聚类数为“5”
(6)单击“OK”按钮,得到层次聚类分析报告。双击层次聚类分析报告中的“Dendrogram”图例,得到图12-94a所示图形。由于有大量观察数据,横坐标数据重叠,可选取放大工具 ,将图中感兴趣的地方放大,如图12-94b所示。
,将图中感兴趣的地方放大,如图12-94b所示。
 (https://www.daowen.com)
(https://www.daowen.com)
图12-93 重新设置好的【Statistics/Multivariate Analysis:hcluster】对话框
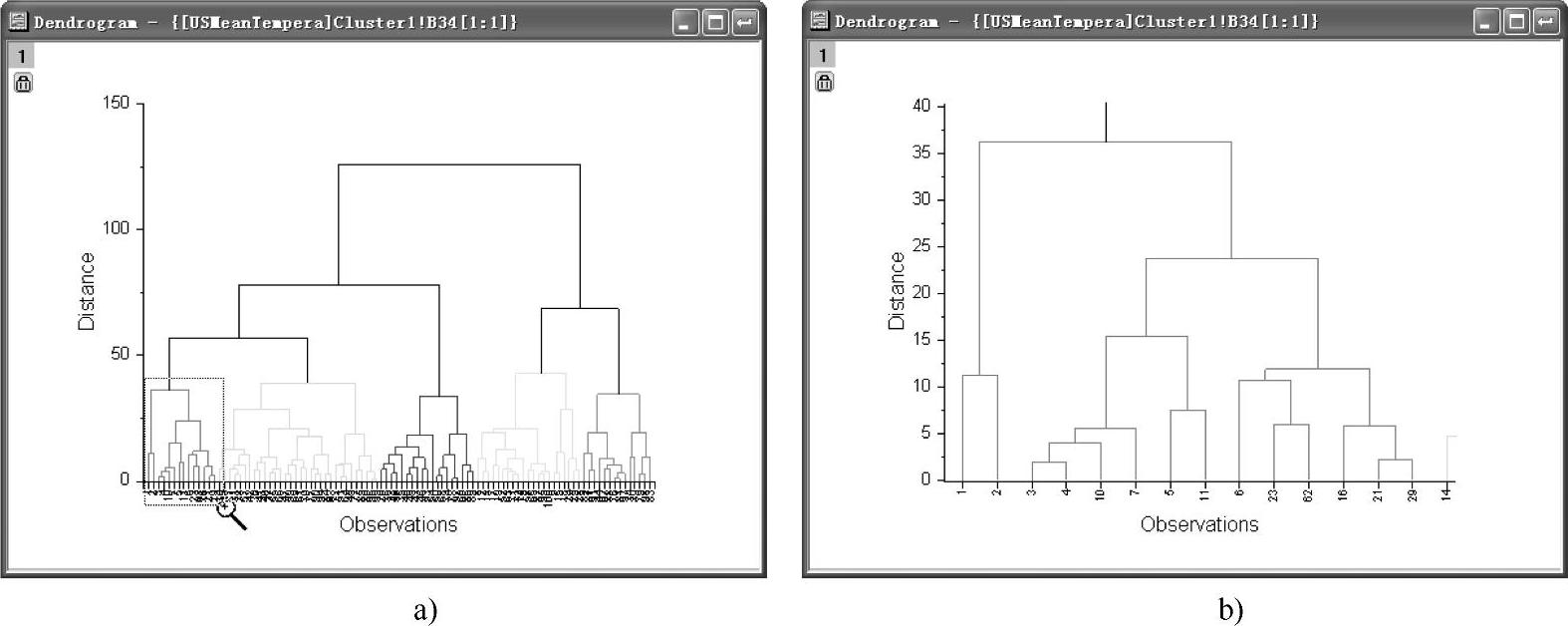
图12-94 “Dendrogram”图和局部放大图
2.K-means聚类分析
在层次聚类分析报告的基础上,对数据进行K-means聚类分析。
(1)用右键单击层次聚类分析报告中的聚类中心(Cluster Center)表,在弹出的菜单中选择“Create Copy as New Sheet”命令(见图12-95),得到采用层次聚类分析的聚类中心数据表(Sheet2)。聚类中心数据表为K-means聚类分析中的“Initial Cluster Centers”数据,如图12-96所示。
(2)选中“US Mean Temperature.dat”工作表中的D(Y)~O(Y)列,选择菜单命令【Statistics】→【Multivariate Analysis】→【K-Means Cluster A-nalysis】,打开【Statistics/Mul-tivariate Analysis:kmeans】对话框。在该窗口中选中“Speci-fy Initial Cluster Centers”复选框,在“Initial Cluster Centers”右边单击切换按钮 ,输入聚类中心数据表(Sheet2)中的Col(D)~Col(O)列。在“Plot”栏中选中“Group Graph”复选框,并通过单击切换按钮
,输入聚类中心数据表(Sheet2)中的Col(D)~Col(O)列。在“Plot”栏中选中“Group Graph”复选框,并通过单击切换按钮 ,回到“US Mean Temperature.dat”工作表。在“X Range”和“Y Range”分别输入Col(B)经度和Col(C)纬度。设置好的【Statistics/Multivariate Analysis:kmeans】对话框如图12-97所示。
,回到“US Mean Temperature.dat”工作表。在“X Range”和“Y Range”分别输入Col(B)经度和Col(C)纬度。设置好的【Statistics/Multivariate Analysis:kmeans】对话框如图12-97所示。
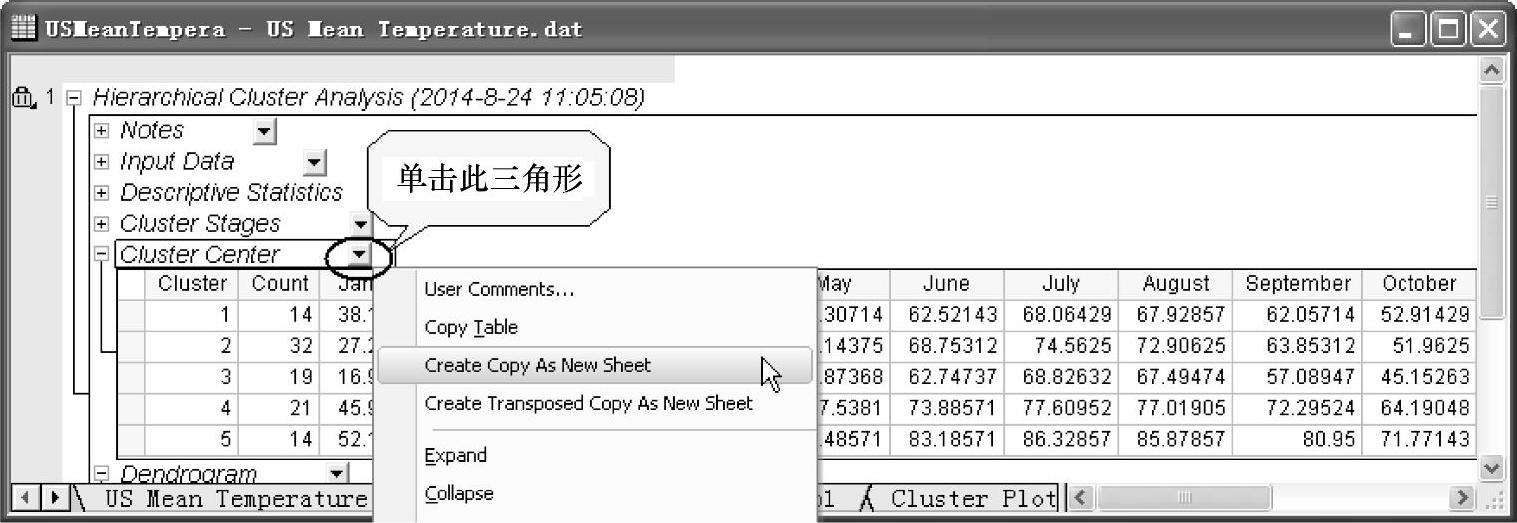
图12-95 在层次聚类分析报告中的聚类中心(Cluster Center)表创建新表
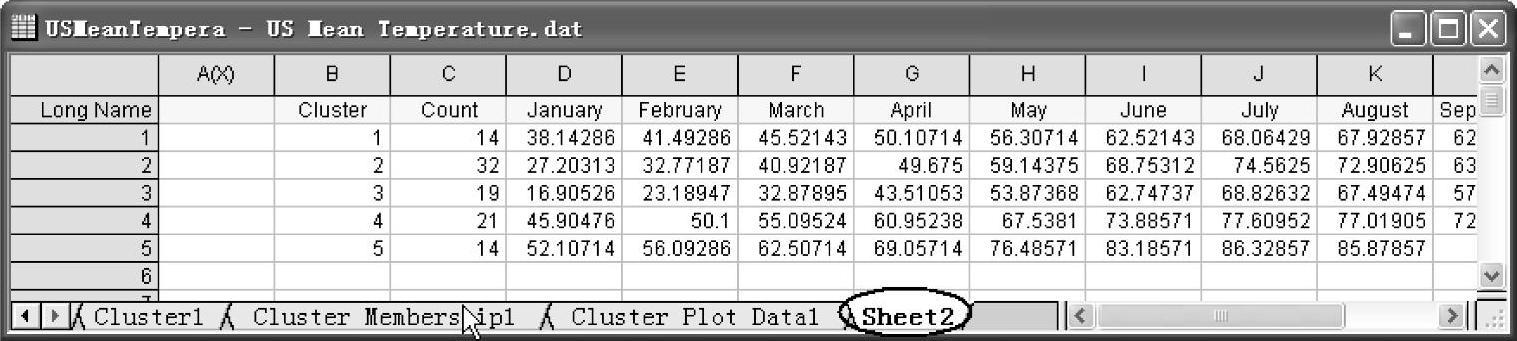
图12-96 聚类中心数据表
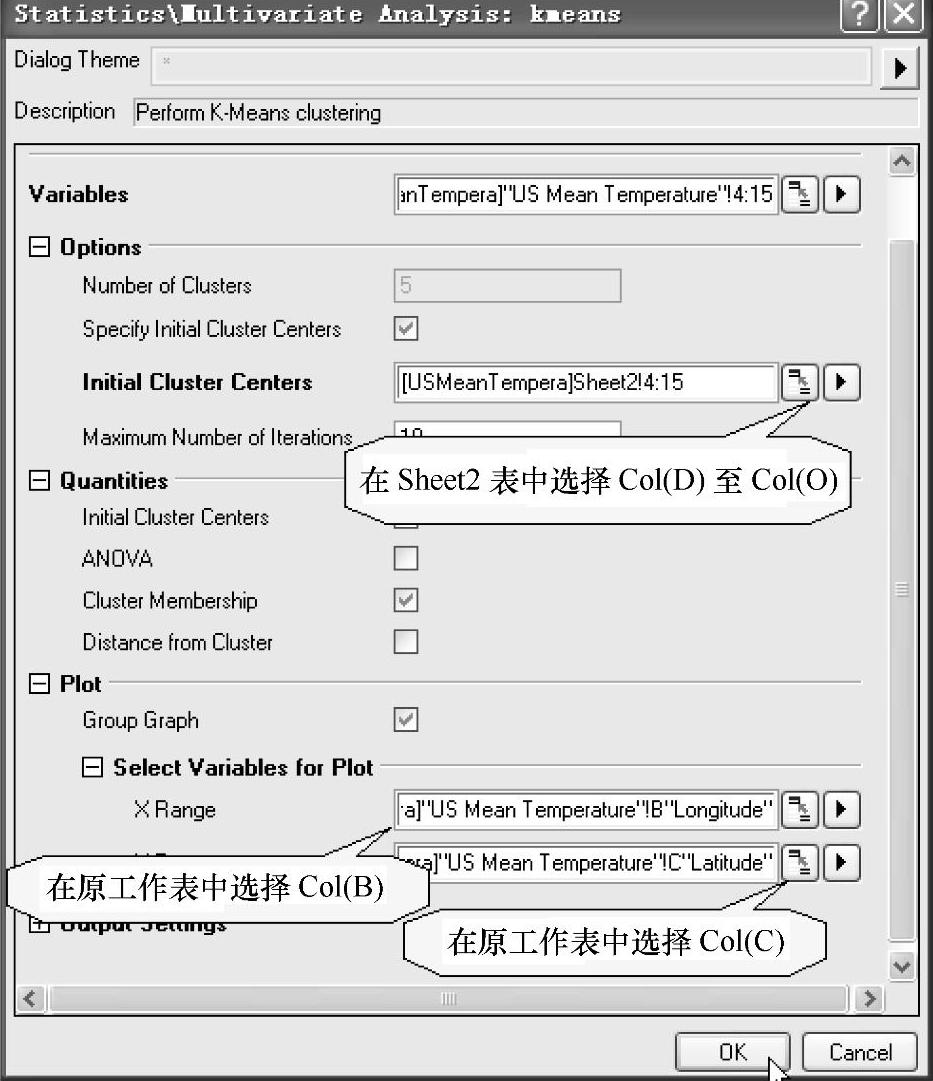
图12-97 设置好的【Statistics/Multivariate Analysis:kmeans】对话框
(3)单击“OK”按钮,得到K-means聚类分析报告,如图12-98所示。在该分析报告中,城市平均温度数据根据城市的纬度聚类为5组。双击该分析报告中的“Group Plots”图,得到图12-99所示图形。该图用5中颜色清晰地聚类分析了城市平均温度。
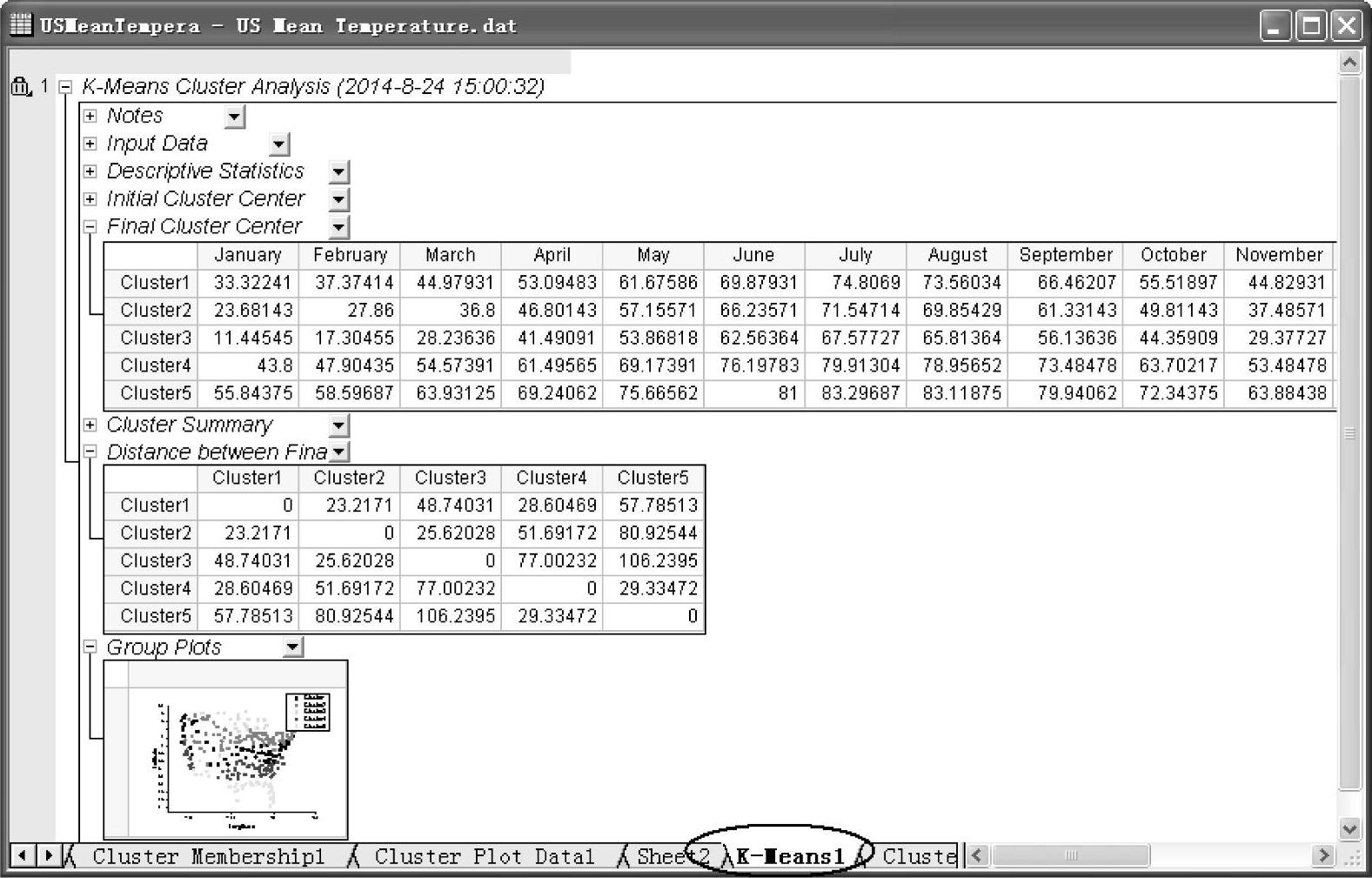
图12-98 K-means聚类分析报告
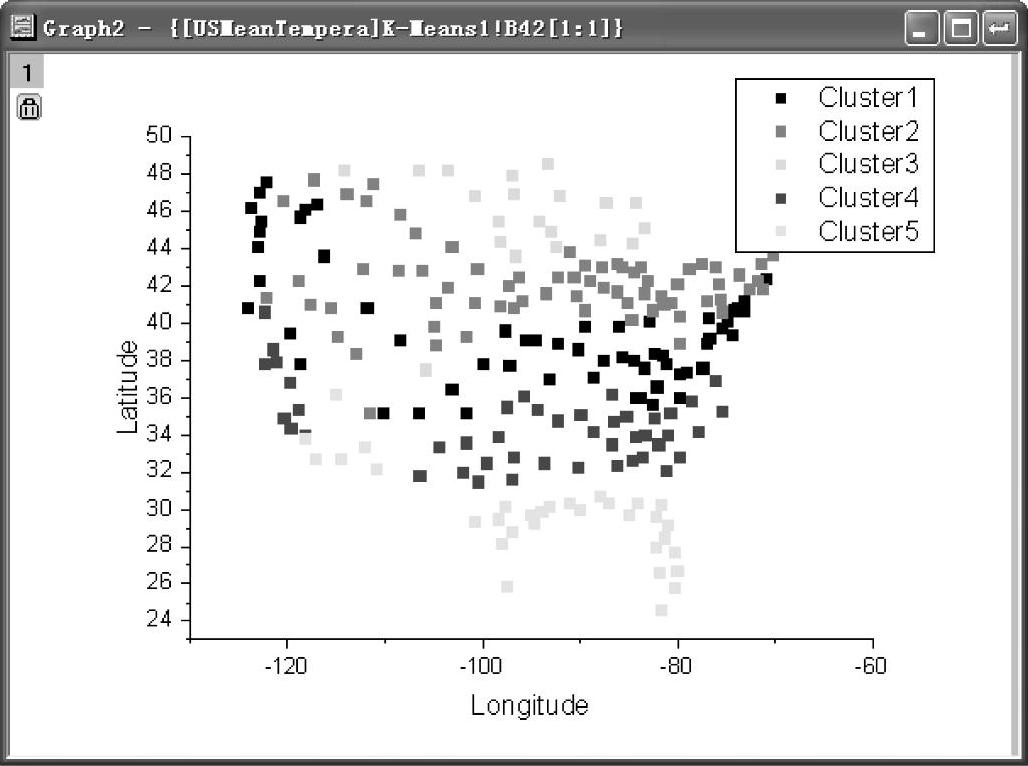
图12-99 “Group Plots”图
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。




