当一个汉字拆分成的字根不足4个时,依次输完字根码后,还需要补加一个识别码,加识别码后仍不足4码时,按空格键。
识别码即“末笔字型识别码”,适用于不足4个字根(即不足4码)组成的汉字。我们知道,在五笔字型中,笔画分为5种,字型分为3种,那么,末笔与字型交叉的可能性就是5×3=15种。其识别码如表3-7所示。
表3-7 末笔字型识别码
注意
识别码共15个符号,输入时,只打圈里边的字根所在键就行了。外带圆圈只是为了便于与真正的字根所在键相区别。
由上表可知,“末笔字型识别码”由单字的末笔画的类型编号和单字的字型编号组成。具体地说,识别代码为两位数字,第一位(十位)是末笔画类型编号(横1、竖2、撇3、捺4、折5),第二位(个位)是字型代码(左右型1、上下型2、杂合型3)。当把识别代码看成一个键的区位码时,即得到对应的字母键。
识别码的作用是减少重码,加快选字,如表3-8所示。
表3-8 识别码示例表
表3-8中,沐、汀、洒的字根都一样,即字根码都是IS,而且字型相同,但末笔画不同,所以加上末笔识别码之后,它们的编码就不相同了。否则就会重码(都是IS)。同样,只、叭的字根码一样(KC),但字型不一样,所以加上字型识别码后,编码也就不相同了。下面我们再举些例子来说明:
把:末笔为“乙”,代号5,字型为左右型,代号1,识别码为 (按N键)。
(按N键)。
回:末笔为“一”,代号1,字型为杂合型,代号3,识别码为 (按<D>键)。
(按<D>键)。
扛:末笔为“一”,代号1,字型为左右型,代号1,识别码为 (按<G>键)。
(按<G>键)。
晃:末笔为“乙”,代号5,字型为上下型,代号2,识别码为 (按<B>键)。
(按<B>键)。
使用末笔字型识别码,主要是对末笔和字型进行判断,然后分别取末笔代码和字型代码,那么五笔字型输入法对末笔和字型有哪些规定呢?下面的内容将告诉你答案。
1.关于末笔的规定
1)所有包围型汉字中的末笔,规定取被包围的那一部分笔画结构的末笔。如:“国”,其末笔应取“丶”,识别码为 43(I)。
43(I)。
2)带“辶(廴)”的杂合型汉字规定取里边字的末笔作为末笔。如:“远”,其末笔应取“乙”,识别码为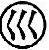 53(V)。
53(V)。
3)对于字根“刀、九、力、匕”,凡是这4种字根为拆分最后一个字根而又需要识别时,一律用它们向右下角伸得最远的笔画“折”来识别。如:仇:亻九 ;化:亻匕
;化:亻匕 等。
等。
4)“我、戋、成”等汉字应遵从“从上到下”的原则,取“丿”作为末笔。(https://www.daowen.com)
2.关于字型的规定
1)凡单笔画与字根相连者或带点结构都视为杂合型。
2)字型区分时,也用“能散不连”的原则。如:矢、卡、严都视为上下型。
3)内外型字属杂合型。如:困、同、匝,但“见”为上下型。
4)含两字根且相交者属杂合型。如:东、串、电、本、无、农、里。
5)下含“辶(廴)”的字为杂合型。如:进、逞、远、过。
6)半包围字都为杂合型。如:式、后、反、司、床、处、办、习、死、疗、皮、厅、尼、压、龙,但相似的友、左、冬、有、看、右、者、布、灰等视为上下型。
对于如何快速掌握末笔识别码,我们总结了以下3点经验:
1)对于左右型汉字,当输入完字根后,只要补打一个末笔笔画代码就等同于加了“识别码”。例如:
杞:木(S)己(N) (N)(“乙”为末笔,补“乙”的末笔代码“N”为识别码)
(N)(“乙”为末笔,补“乙”的末笔代码“N”为识别码)
沽:氵(I)古(D) (G)(“一”为末笔,补“一”的末笔代码“G”为识别码)
(G)(“一”为末笔,补“一”的末笔代码“G”为识别码)
汀:氵(I)丁(S) (H)(“丨”为末笔,补“丨”的末笔代码“H”为识别码)
(H)(“丨”为末笔,补“丨”的末笔代码“H”为识别码)
2)对于上下型汉字,当输入完字根后,补打由两个末笔画构成的“字根”,即为识别码。例如:
会:人(W)二(F)厶(C) (U)(“丶”为末笔,补两个“丶”组成的字根“
(U)(“丶”为末笔,补两个“丶”组成的字根“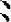 ”的代码“U”为识别码)
”的代码“U”为识别码)
华:亻(W)匕(X)十(F) (J)(“丨”为末笔,补两个“丨”组成的字根“〢”的代码“J”为识别码)
(J)(“丨”为末笔,补两个“丨”组成的字根“〢”的代码“J”为识别码)
青:(G)月(E)二(F)(“一”为末笔,补两个由“一”组成的字根“二”的代码“F”为识别码)
3)对于杂合型汉字,当输入完字根后,补打由3个末笔笔画构成的“字根”,即为识别码。例如:
同:冂(M)一(G)口(K) (D)(“一”为末笔,补三个“一”组成的字根“三”的代码“D”为识别码)
(D)(“一”为末笔,补三个“一”组成的字根“三”的代码“D”为识别码)
平:一(G)(U)丨(H) (K)(“丨”为末笔,补三个“丨”组成的字根“川”的代码“K”为识别码)
(K)(“丨”为末笔,补三个“丨”组成的字根“川”的代码“K”为识别码)
其实,末笔识别码主要是用来区别可重复的两个字根或三个字根的汉字,当然有时字根虽少但可能不重复,此时就不必输入识别码了。有人可能会问,怎么才能知道什么时候需要输入识别码,什么时候又不需要输入识别码呢?对此,一是查看本书附录中的《五笔字型字根及编码字典》或其他标有简码的五笔字典;二是靠平时的练习,从实践中寻找答案。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。




