在高性能计算领域,并行体系结构主要可分为三类:向量计算机、共享存储器并行计算机、分布存储器并行计算机。下面,笔者对这三类并行结构及其编译系统作简单介绍。
1.向量计算机及其编译系统
向量是一个数学概念,就是指类型相同的数据项的集合。向量的概念看似有些神秘,不过,它的实现形式却早己深入人心。在程序设计语言中,向量的实现形式就是数组。例如,对于向量语言的标准化具有里程碑意义的Fortran 90也被称为“数组语言”。其主要原因就是从体系结构和编译器实现来看,数组操作就是向量操作的一种实现形式。
而向量计算机就是指具有高效的向量处理能力的计算机系统。有读者可能疑惑,似乎普通计算机也同样具有向量处理能力,那么,它们是不是向量计算机呢?答案显然是否定的。在普通标量计算机中,向量处理是基于软件实现的。例如,在C语言中,计算两个向量的和就必须依赖程序实现。而这里所说的向量处理能力通常是指硬件层次上的,也就是说,向量计算机可以通过硬件指令直接完成复杂的向量运算,而不需要借助软件实现。对于超级计算技术而言,向量计算对提高超大规模科学计算的性能是极其重要的,尤其在大型机、巨型机等系统中。
与普通标量计算不同,向量计算对计算机的寄存器组、流水线处理、存储访问控制都提出了新的需求。通常,需要计算机能够一次读取、存入一组数据并执行相关的计算处理。因此,除了标量功能部件之外,向量计算机还专门设有向量寄存器、向量长度寄存器、向量屏蔽寄存器、向量流水功能部件和向量指令系统等。这里,以两个向量求和为例作简单说明,如图10-5所示。
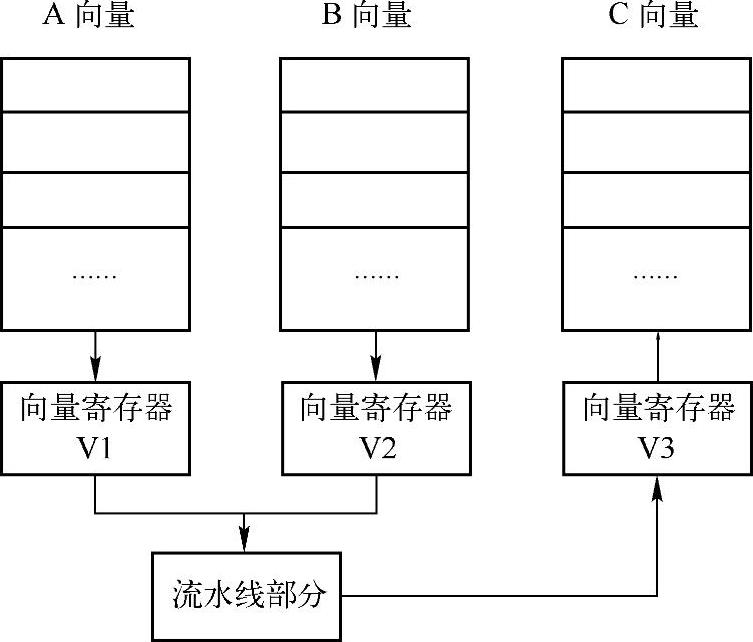
图10-5 向量求和的处理过程
在图10-5中,假设A、B、C三个向量的长度都是64,那么,此求和操作需要进行的迭代次数为1,这比普通标量计算机需要的64次迭代高效得多。Fortran 90的描述形式如下:
C(1:64)=A(1:64)+B(1:64)
但是,更多时候,用户习惯于书写如下的简单循环形式:
D0 1=1,64
C(I)=A(I)+B(1)
ENDDO
当然,这两种形式是完全等价的,因此,并行化的任务就是将后者转换为前者。不过,这种转换是非常复杂的,不像读者想象的那样简单。
下面,笔者再给出一个例子:
DO I=1,64
A(I+3)=A(I)+B(I)
ENDDO
试想一下,是否可以将其简单地将其转换为:
A(4:67)=A(1:64)+B(1:64)答案是否定的,原因非常简单,每一个迭代完的结果将影响后续迭代的过程,因此,这种存在依赖关系的情况是不可向量化的。那么,哪些情况可以转换,而哪些情况不可以转换呢?这就是依赖关系分析要解决的问题。
2.共享存储器的并行计算机及其编译系统
共享存储器的并行计算机主要由多个处理机、一个共享的中央存储器及专门的同步通信部件组成。处理机可以是向量机,也可以是标量机。系统一般是MIMD(多指令流多数据流)体系结构。如图10-6所示。(https://www.daowen.com)
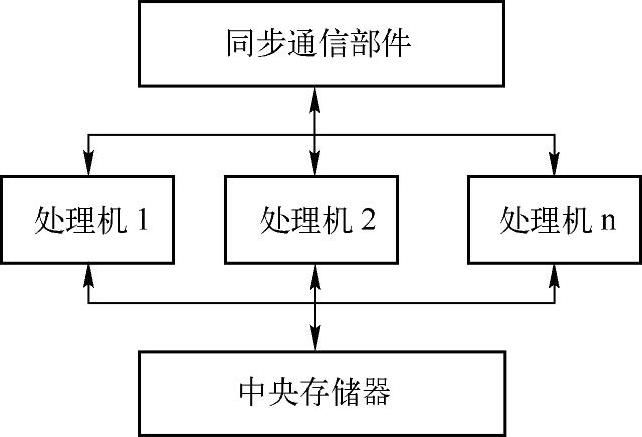
图10-6 共享存储器的并行计算机的基本结构
在共享存储器的并行计算机中,虽然,物理上多个处理机是共享一个中央存储器的,但是,一个处理机究竟可以访问哪些存储数据及一个数据应该被哪个处理机优先访问等都是由用户控制的,硬件机制并没有严格的限制。而其中的同步通信部件只是为处理机之间的同步通信提供硬件支持,例如,用于实现同步原语的共享信号灯等。
与向量计算机相比,共享存储器的并行计算机在更大程度提高了并行处理的能力。多处理机的结构使得计算机可以并行执行多个循环迭代、程序块或函数。如果所属的处理机都是向量计算机,那么,该系统的并行能力将更为出色。在低层次上,由向量计算机完成向量计算方面的迭代,而高层次上,则由共享存储器的并行计算机提供服务。
基于共享存储器的并行计算机的编译系统通常需要完成如下工作:
(1)串行程序并行化。识别与分析输入串行源程序的可并行化的部件,将整个程序任务划分为多个可并行执行的部分,以便多处理机并行计算。当然,这项工作是基于依赖关系分析完成的。正如先前讨论的,并行化的主要对象仍然是循环迭代,也就是将循环迭代形式转换为等价的可并行处理的形式,或者插入并行编译指导命令。
(2)处理并行语法机制。根据并行语言的特点,将源程序编译成相应的目标程序。这里主要指的是一些与并行机相关的语法成分,如并行循环结构、并行段结构、并行区结构等。除此之外,编译器还需关注任务调度、处理机分配、任务同步等方面的工作。
3.分布存储器的并行计算机及其编译系统
分布存储器的并行机是由很多相对独立的结点(通常就是独立的计算机)通过网络连接而成的,每个结点都有自己的处理机和存储器。结点数是庞大的。如图10-7所示。
这类计算机的特点是存储访问时间不一致,即处理机对远程存储器的访问时间比对本地存储器的访问时间要长得多。分布存储器的并行计算机得以发展主要有两方面的原因:
(1)系统组建的价格相对便宜。与向量计算机、共享存储器的并行计算机相比,分布存储器的并行计算机主要是依赖于微型计算机的,因此,其成本有其他两类并行计算机无法比拟的优势。
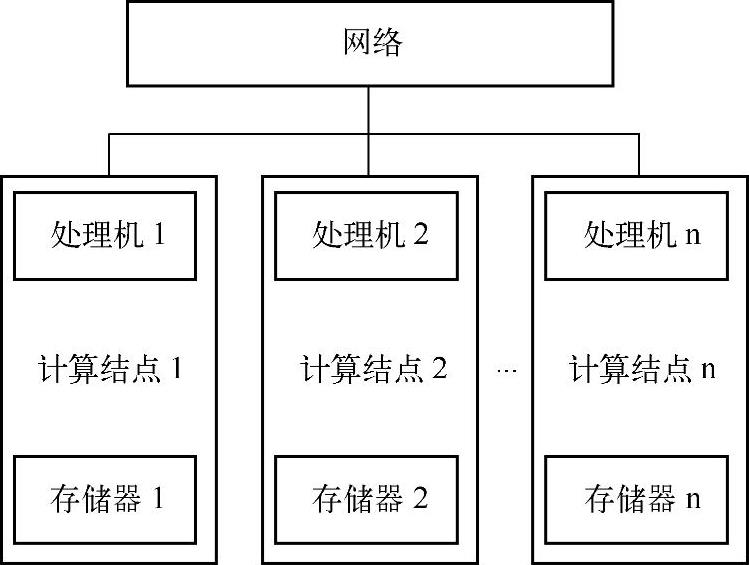
图10-7 分布存储器的并行计算机的基本结构
(2)分布存储器结构突破了共享存储器的性能瓶颈。虽然共享存储器结构的并行计算机可以在计算处理方面达到高峰值,但存储器的访问却是这类并行计算机的瓶颈。而分布存储器结构的方案却不存在这种瓶颈,从而可以追求更高的峰值。不过,值得注意的是,这种方案也不是绝对完美的,网络性能将在很大程度上约束并行执行及存储器访问的效率。
随着互联网的普及与发展,分布存储器的并行计算机结构已经成为当今最热门的话题之一。近年来,被炒得热火朝天的“云计算”也可以视为这种计算机结构的商业化产物。而分布计算的主要研究对象就是这种计算机结构。
在分布存储器的并行计算机中,数据并行程序设计语言是主要的并行语言,它扩充了普通语言在数据分布与并行处理方面的描述能力。例如,Split-C、CM Fortran等。数据并行语言便于用户简单且直观地编写并行程序,而不必关注并行处理的细节问题。
目前,在分布存储器的并行计算机上的编译系统主要是用于处理数据并行语言的,其工作包括如下几项:
(1)数据分布。为了减少通信资源耗费,提高执行的效率,并行任务与相关数据的分布是编译器需要关注的。虽然无论使用何种分配算法,保证并行任务与相关数据绝对被分配在同一个计算结点是不现实的,但这却是编译器设计者的努力方向。根据计算结点的分布情况,合理安排任务与数据的布局,以减少通信资源的耗费,这是完全可行的。
(2)任务划分。如何合理地划分任务,也是实现计算与参与计算的数据尽可能被分配到同一个计算结点的一种有效策略。通常的任务划分原则是拥有者计算,即数据在哪个计算结点上,则优先考虑由哪个结点完成计算任务。
(3)同步与通信。主要工作包括确定同步与通信点、插入相应的并行库子程序调用、同步通信优化等。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。







