前面已经讲述了关于栈式存储分配的基本思想,本小节将基于一个具体的目标机模型深入讨论栈式存储分配的一些细节实现。为了便于读者更好地理解,先简单介绍一下i386系统栈相关的话题。
在i386体系结构中,系统栈是由CPU直接管理与维护的,它主要涉及两个寄存器:ss、esp。在保护模式下,ss寄存器存放的是段选择器,用户模式程序不应对其进行修改。在实模式下,ss寄存器存放的就是系统栈的段首地址,通常是由用户程序指定的。而esp寄存器存放的是指向栈内特定位置的一个32位偏移值。一般来说,esp寄存器指向的就是最后压入到系统栈上的数据。在实模式下,由于栈元素的地址只有16位,因此,只需要使用esp的低16位(即sp寄存器)即可。相对于实模式而言,现代编译器更多关注的是保护模式下的相关话题,因此,本书将重点讨论32位保护模式下的系统栈机制。关于系统栈的操作,主要包括两类:压栈操作、出栈操作。
压栈操作将esp指针减4,并将值复制到esp指向的位置,如图8-7所示。
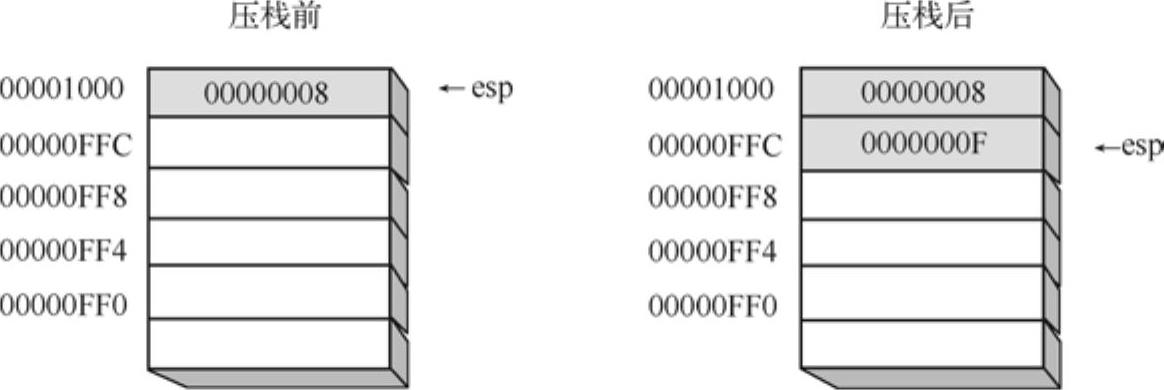
图8-7 i386系统栈压栈示意图
出栈操作将esp指向位置的值复制出来,并将esp指针加4,如图8-8所示。
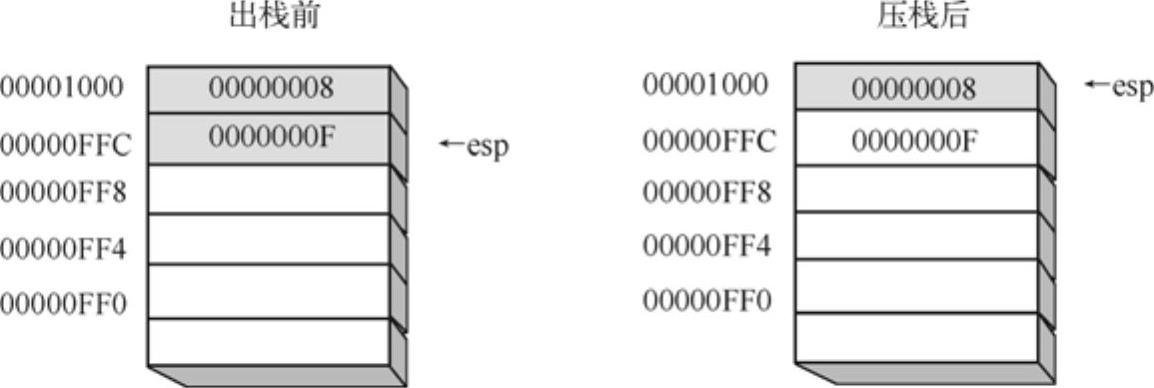
图8-8 i386系统栈出栈示意图
针对i386的系统栈,笔者作如下三点简单说明:
(1)系统栈区域的初始状态。理论上说,系统栈区域的初始状态为空。不过,实际却并非如此。在i386体系结构中,系统栈区域的初始状态是随机的,其实际存储的值是完全取决于存储器的当前状态的。因此,为了避免出现意外错误,在函数初始化过程中,有些编译器设计者会考虑系统栈初始化的问题,例如,VC++是将“OxCC”填充即将使用的栈区域。注意,并不是初始化整个系统栈。
(2)系统栈的扩展方向。关于这个问题,从图8-7及图8-8中,读者应该已经看出来了。的确,与数据结构课程中描述的栈结构相比,i386系统栈的扩展方向是向下扩展的,即随着栈内元素的增加,esp指向的地址却是逐步减小的。有些读者可能会疑惑向下扩展系统栈是否有特殊的原因。事实上,这是没有任何原因的,只是Intel设计者的个人喜好而已。
(3)出栈元素并不清除。与传统的栈结构类似,CPU并不会刻意去清除那些己出栈的元素所在的存储区域。当有新的元素需要入栈时,CPU就直接覆盖原有数据即可。以图8-8为例,虽然OOOOOFFC单元的数据已经出栈,但CPU只对esp作了修改,却并不真正清除该数据。直到有新的元素入栈时,CPU就将其写入OOOOOFFC单元中,此时,并不关注是否存在数据,而是直接无条件覆盖即可。
下面,笔者通过一个完整实例来介绍i386栈式分配的内核,以便读者深入理解这一精巧的处理过程。
例8-2 i386栈分配的实例,见表8-1。
表8-1 输入源程序与相应IR序列
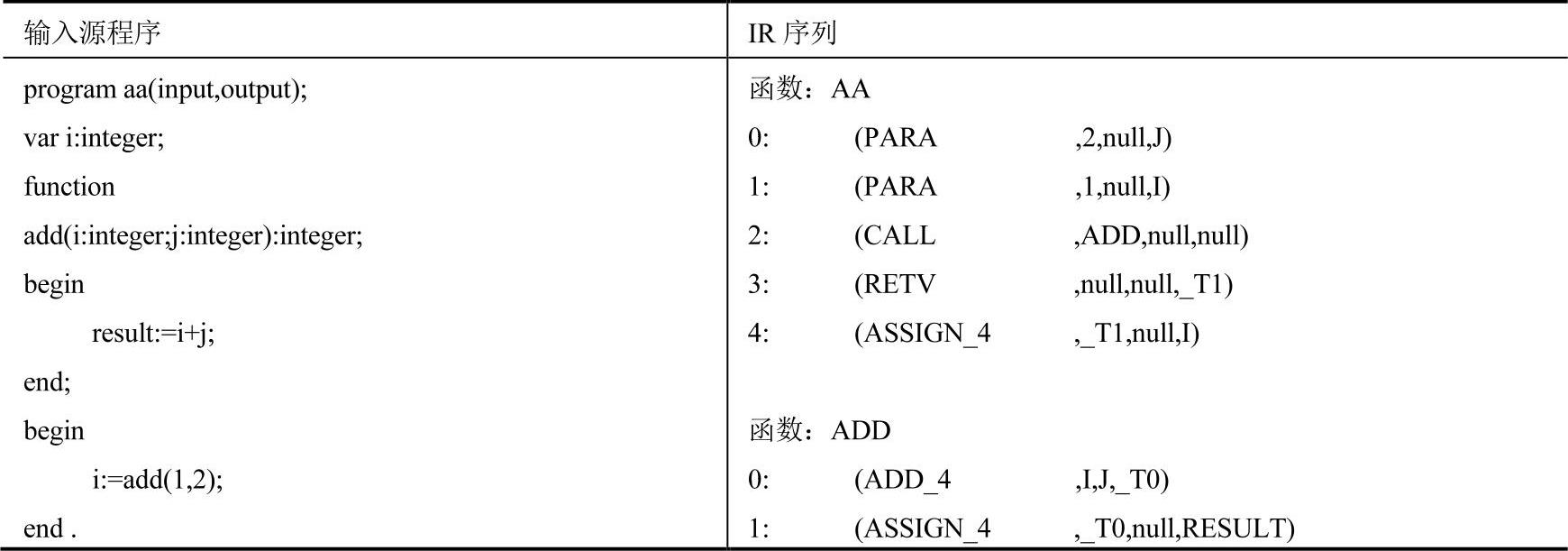
表8-1所示的程序是非常简单的,读者应该不难理解其IR序列的意义。这里,笔者特意关闭了优化选项(包括汇编级的窥孔优化),目的就是为了更好地还原调用过程的全貌。下面,笔者就详细列出相应的汇编程序代码,如程序8-1所示。
程序8-1

 (https://www.daowen.com)
(https://www.daowen.com)

这是一个标准的宏汇编程序,使用MASM 6.15汇编、链接得到可执行文件。笔者并不打算深入讲述汇编语言方面的话题,有兴趣的读者可以参考《Intel汇编语言程序设计》一书。这里,假设esp的初始值为1000H。下面,就来看看函数调用的详细过程,如图8-9所示。
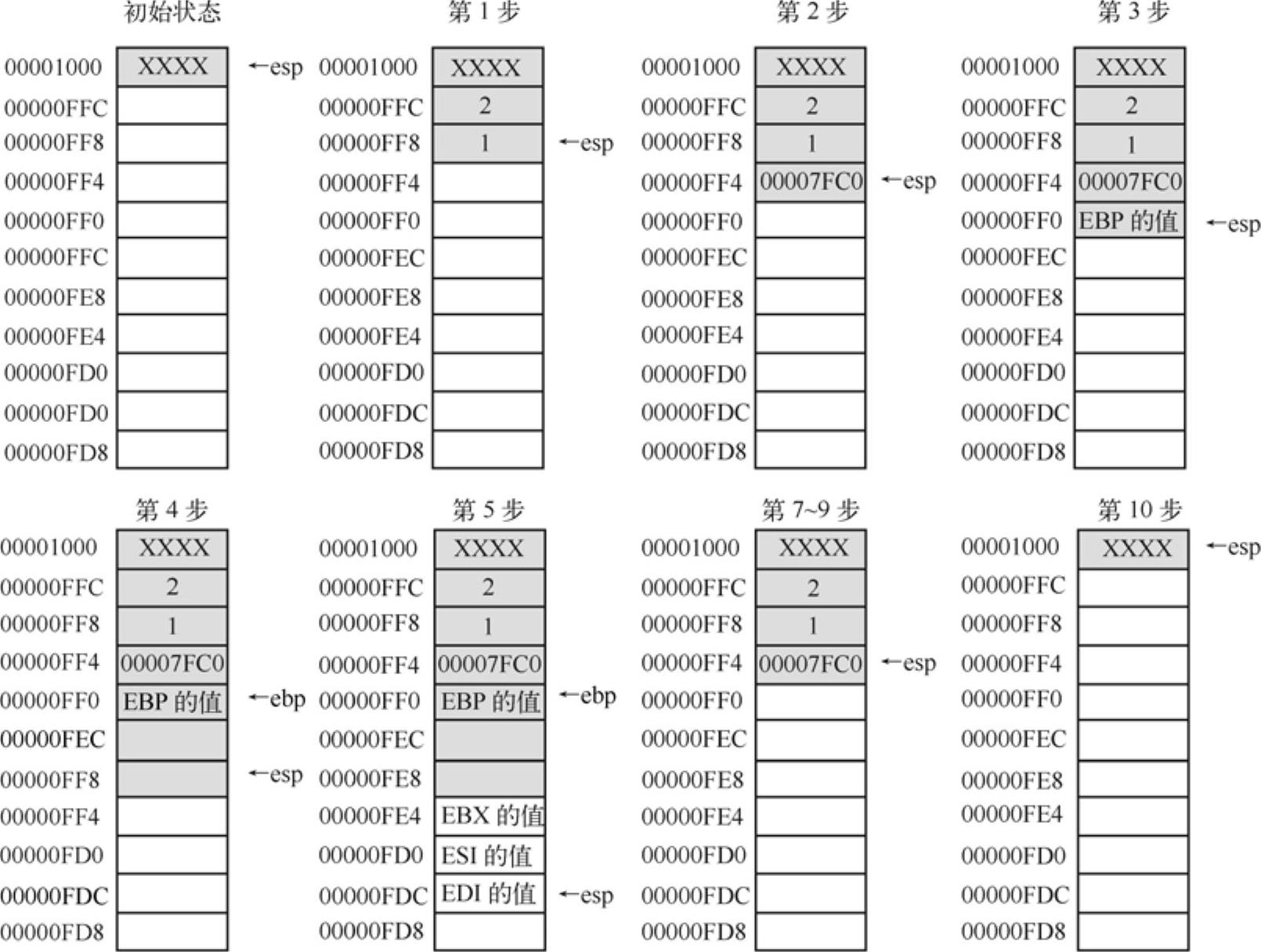
图8-9 程序8-1的栈变化过程
(1)参数压入系统栈。注意,为了便于被调函数访问实参,参数压栈的顺序恰好与参数书写顺序相反。
(2)调用ADD过程。首先,CPU会自动将调用点(即call指令)之后首条指令的地址压入系统栈。这里,假设第35行指令的地址为00007FCOh。然后,CPU转入ADD过程执行。
(3)保护ebp。由于ebp将在程序中用于变址寻址,故必须将ebp压入系统栈。然后,将esp的值置入ebp中。注意,由于esp是栈顶的指针,压、出栈将时刻影响esp的值,因此,不便于后续局部变量的寻址处理。
(4)申请存储空间。ADD过程有两个4B的变量,故需要分配8B的存储空间。注意,由于系统栈是向下扩展的,因此,esp的值减8即表示向下预留8B的存储空间。
(5)保护ebx、esi、edi的值。一般编译器都考虑将这三个寄存器保护,以便后续处理。
(6)局部变量(包括参数)只需以“[ebp+该变量的偏移]”形式引用即可。
(7)恢复ebx、esi、edi的值。
(8)恢复esp的值。
(9)恢复ebp的值。
(10)清理参数并返回。在i386系统中,提供了“ret X”指令来清理参数,这是一种非常有效的机制。
在图8-9中,有一个事实是显而易见的,那就是函数调用前后的系统栈是平衡的,因此,本次调用可以视为是安全的,读者千万不可忽视这一要点。在应用系统栈时,平衡可能比其他任何因素都显得重要。一些商用编译器甚至不惜通过在目标程序中插入检测代码,以保证栈的平衡。除了栈平衡之外,编译器需要关心的另一个问题就是局部变量、参数等数据对象的寻址,这是被调函数正常运行的关键所在。仔细分析图8-9,读者不难发现以下两个结论:
(1)实参存储区就是以ebp+4为基准地址向上扩展的存储区域。
(2)局部变量存储区就是以ebp-4为基准地址向下扩展的存储区域。
有了以上两个结论以后,寻址问题将变得非常容易。例如,可以通过[ebp+8](即[ebp+4+4])访问参数i。当然,在这个过程中,访问的越界控制完全是由编译器处理的,编译器必须准确计算每个对象的偏移,以及预留的空间等。这是一项非常精巧的工程,稍有不慎,就将导致编译结果不正确。值得注意的是,关于系统栈的布局形态并不唯一,因此,以上两个结论未必适用于任何编译器。不过,笔者可以肯定地说,栈分配的基本思路必定如此,差异仅可能存在于一些实现的细节中。例如,需要保护的寄存器个数可能有差异。甚至有些优化编译器不必借助于ebp寻址,而是直接使用esp。那样的话,由于整个函数范围内esp是可能发生变化的(嵌套调用其他函数),因此,计算偏移的问题将变得异常复杂。有兴趣的读者可以尝试。而且,可以肯定的是,这种做法是绝对可行的。
最后简单解释一下关于存储区布局的问题。实参存储区的布局是根据实参的压栈顺序而定的。一般而言,为了便于函数顺序访问实参,在传递实参时,将实参逆序压栈是通用的解决方案,这是不存在任何异议的。而变量存储区的布局则完全是由编译器决定的,编译器根据函数局部变量的个数及所占空间的大小分配相应的存储区。至于局部变量到底是如何映射到存储区中的问题,已经在8.1.2节中作了详细讨论,不再赘述。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





