这里所讨论的栈主要指的是控制栈。实际上,控制栈与传统意义上的栈是有差异的,主要体现在两个方面:
(1)可访问元素。传统的栈可访问的元素只有一个,也就是栈顶。无论入栈、出栈,其操作的对象只是栈顶而己,如果想访问栈的其他非栈顶元素是不可能实现的。然而,控制栈不但需要支持传统的入、出栈访问方式,还必须支持通过直接、间接等寻址方式访问栈的任意元素,否则将无法满足分配策略的需求。
(2)栈的大小。用户在声明一个栈时,必须说明其大小。然而,编译器却不需要过多考虑控制栈的大小。换句话说,如果一个程序能够将系统栈耗尽,那么,这个程序的逻辑可能是值得商榷的,
在编译原理书籍中,一般很少讨论以上话题,这是因为常见的通用机所提供的系统栈都满足这两个条件。不过,笔者认为讨论以上话题是具有一定现实意义的。事实上,并不是所有的系统栈都适合作为控制栈的。在一些嵌入式系统中,有些栈结构可能容量比较小,有些栈结构则不支持寻址访问或者入、出栈访问,这样的栈都不适合作为控制栈。
栈式存储分配的基本思想就是每当进入一个过程时,就在控制栈顶为该过程分配所需的数据空间,当一个过程工作完毕返回时,它在栈顶的数据空间也随即释放。习惯上,将那块与过程有关的数据空间称为活动记录(activation record),亦称为帧(frame),缩写为AR。AR的空间一般由以下几部分组成:过程局部变量的空间、实参列表、返回值空间、返回地址、机器状态等。在一次过程调用中,控制栈的变化是一个非常精巧的过程,要求编译器经过非常严谨的计算,方才得以实现。
根据所实现语言的不同,AR的内容与布局也是不尽相同的。事实上,包括很多书在内,关于AR的观点也存在一定的差异。这里,笔者参考了“龙书”关于AR的描述,并结合NeoPascal的实现,介绍AR的各基本组成部分。如图8-5所示。
(1)实参。从经典编译技术的观点来说,实参是由过程调用点压入控制栈,供过程内部读取使用的。不过,在现代编译器设计中,参数传递更多地依赖于寄存器,而不是通过AR传递的。即便如此,编译器仍然需要在AR中预留适当的实参空间,想通过寄存器传参解决任意参数列表的传递问题是不可能的。Delphi在这方面的处理是比较出色的,第一、二个参数通过ecx、edx传递,其他参数依然压入控制栈。这就是fastcall的调用约定,是继stdcall、cdecl之后另一种经典的调用约定。

图8-5 AR结构示意图
(2)返回值。返回值是由函数执行完毕后,返回给调用点的值。由于返回值的类型不同,返回值的空间大小各异。不过,一个函数最多只允许存在一个返回值,因此,借助于寄存器传递返回值相对容易得多。在现代编译器设计中,通过eax传递返回值几乎是公认的。
(3)保存的机器状态。用于保存当前过程调用之前的机器状态信息,包括返回地址、通用寄存器的值等。其中,有些信息可能是由调用点或被调过程保存的,而有些信息则可能是由机器自动保存的。在i386体系结构中,返回地址就是由机器自动压栈保存的。当过程调用完毕返回时,必须将保存的机器状态恢复,以便调用点继续执行后续程序。
(4)局部数据与临时变量。这两部分都是与过程的相关局部数据对象,从编译器设计的角度来说,在存储分配中,并不需要严格区分局部数据与临时变量。当然,如何存储布局?如何删除死变量?这些问题还是值得注意的。
(5)控制链。指向调用者的AR。
(6)访问链。用于指向其他AR中可访问的非局部数据对象。
由于Neo Pascal和C都不支持嵌套过程声明,所以,本书将略过控制链与访问链的话题。不过,它们对于实现标准Pascal、Alogl 60、ML等是有实际意义的,有兴趣的读者可以参考相关资料。下面通过一个实例来分析过程调用的详细步骤。
例8-1 过程调用的分析。代码如下所示。
 (https://www.daowen.com)
(https://www.daowen.com)

函数调用的AR变化如图8-6所示。
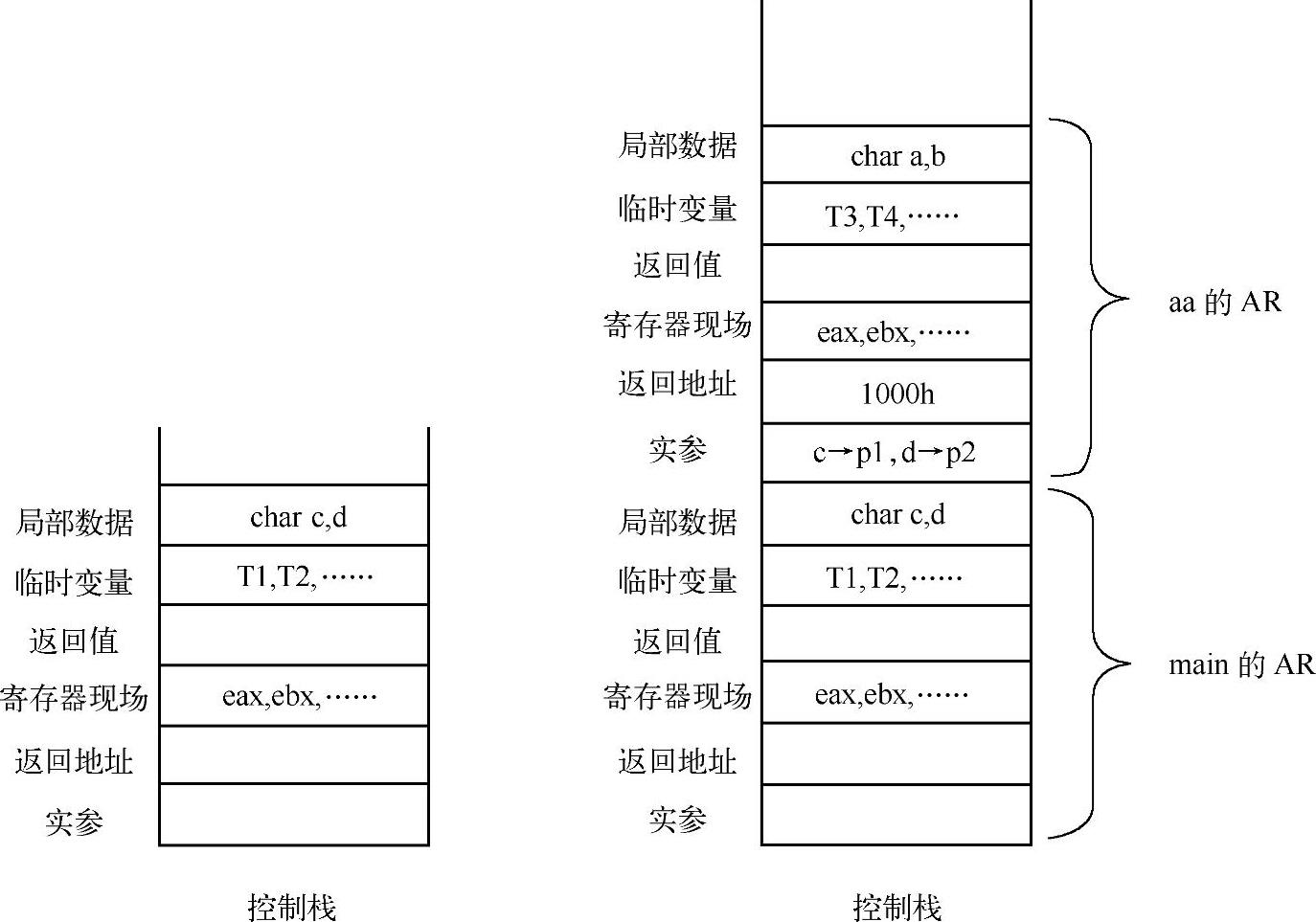
图8-6 函数调用的AR变化
a)main调用aa前的栈示意图 b)main调用aa后的栈示意图
图8-6a的控制栈是调用aa前的状态,注意,main函数也有一个AR。当然,其中某些项允许为空,编译器不必分配相应的空间。这里,为了便于读者理解,故未将空表项删除。在本例中,临时变量是笔者假设存在的。main函数在执行前同样需要保护寄存器现场。当然,对于main来说,这个动作看起来可能意义并不大。请读者结合图8-6b,理解调用aa函数的大致过程。可以分为如下几步:
1)参数传递。这里,假设使用stdcall方式传递参数。编译器会将实参自右向左依次压栈。实际上,实参与形参是共享同一片存储区的,aa函数体内对形参的访问就直接变成了对实参的存取,这将是非常方便的。
2)返回地址压栈。在正式执行aa函数之前,必须将返回地址压栈。前面,笔者已经介绍了返回地址压栈的方式很多,有些是由用户程序负责的,有些则是由机器自动完成的。不仅如此,压栈的地址也可能存在差异,有些是将aa函数调用点call指令所在地址压栈,而更多的是将aa函数调用点call指令之后的一条指令所在的地址压栈。这主要依赖于目标机的体系结构。本例假设返回地址是1000h。
3)转入aa函数。进入aa函数的程序体执行。注意,在转入aa函数执行时的栈顶是“返回地址”。那么,当aa函数执行完后,返回main函数前,也必须保证栈顶仍然是“返回地址”。否则,将导致异常。
4)aa函数的调用代码序列。转入aa函数后,率先执行的并不是aa函数的实际程序,而是编译器在aa函数体前插入的一段特定代码序列。这段代码序列主要用于生成AR。其中,包括保护寄存器现场、分配临时数据、局部变量等存储空间。待AR构造完毕,就得到了一个完整的AR布局示意,如图8-6b控制栈所示。
5)aa函数的返回代码序列。当aa函数完全执行完毕,必须执行一段由编译器生成插入在返回指令之前的代码序列。这段代码序列主要完成空间回收,并恢复寄存器现场。当然,也包括返回值处理。事实上,所谓“空间回收”并不是真正的数据清空,而只需将栈顶调整到“返回地址”即可,以保证函数能正常返回。
6)返回main函数。当执行到返回指令时,从栈中弹出返回地址,根据返回地址返回调用点。原则上,弹出返回地址的动作应该由压栈者负责。也就是说,如果返回地址是由机器自动压的,那么,就由机器处理返回地址的弹出。否则,就由用户程序负责。
7)清理现场。虽然程序得以继续正常执行,但是控制栈里却多了几个实参数据,这是不能接受的。通常,需要将栈顶恢复到传参之前的状况。那么,由谁来完成这项工作呢?关于这个问题存在两种观点,一种认为由调用者清理,一种认为由被调用者清理。cdecl方式是前者的经典实例,而stdcall方式则实现了后者。从理论上来说,更规范、灵活的清理方式是前者,处理个数不定的参数列表时,它显得更方便。被调函数只关心如何引用参数,不需要过问参数的数量。而后者在处理个数不定的参数列表时,不得不将参数的个数同时传递给被调函数,因为其清理工作将在函数返回时工作。当然,后者也不是没有任何优势的,在处理个数确定的参数列表时,调用者可以省去很多烦心事。WINAPI的标准调用方式就是stdcall。
关于被调者清理现场的方案,还有一个问题需要了解,那就是如果目标机的返回指令功能比较弱时,实现由被调用者清理现场将是比较复杂的。这是因为无论是调用者还是被调用者清理现场,都必须保证清理现场是在返回指令执行后进行的。理由很简单,因为返回地址位于实参之上,一旦清理了现场,返回地址就将丢失。为了解决这个矛盾,现代目标机体系结构一般不仅支持简单的RET指令,还支持RET X指令(即返回后,同时退X字节的栈)。这样,由被调用者清理现场也并不困难。不过,并非所有的目标机都支持RET X指令。如果基于不支持这类指令的目标机,那么,就必须在返回指令之前,将“返回地址”暂存后清理现场,清理完后再将“返回地址”压栈,以保证正常返回调用点。
实际上,无论是普通调用,还是递归调用,都可以借助于这个模型实现。从理论上来说,只要栈空间允许,任意多级嵌套调用都是合法的。C、Pascal等语言并没有规定函数调用的级数或递归的层次等。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。




