在存储分配之前,编译器还必须完成一项重要的工作,就是计算每个数据对象所需占用的存储空间大小。通常,数据对象的存储空间大小依赖于其数据类型。对于简单类型来说,计算空间大小是非常容易的。不过,对于复杂类型来说,就需要一定的技巧。数据对象的存储布局受目标机寻址约束的影响很大,合理的存储布局对提高程序的执行效率是非常有效的。这里,介绍一种比较常见的方案——整字对齐。
笔者先来介绍一下整字对齐的背景。所谓“字长”,简而言之,就是CPU -次读、写数据的最大长度。例如,32位机指的就是一次读、写数据的最大长度为32位(4字节)。在现代计算机体系结构中,为了便于设计,CPU通常是按整字访问数据的,即地址必须能整除机器字长。如果数据不按规定存储,CPU就不得不耗费多个周期进行读、写数据,并按实际情况进行拼接,这样会大大降低程序的执行效率。以32位机为例,如果用户将4字节数据存储在0006h为首地址的单元中,那么,CPU就必须花费两个周期分别寻址0004h(获取字的高两个字节,即0006h、0007h单元的字节数据,舍弃低两个字节数据)、0008h(获取字的低两个字节,即0008h、0009h单元中的字节数据,舍弃高两个字节数据),然后将相应的数据拼合成一个完整的4字节数据。
因此,避免这种情形的发生是非常有必要的。如果编译器仅仅依照声明的次序及数据对象的实际大小来安排存储布局,那么,发生这类问题的概率是非常大的。如图8-3所示。
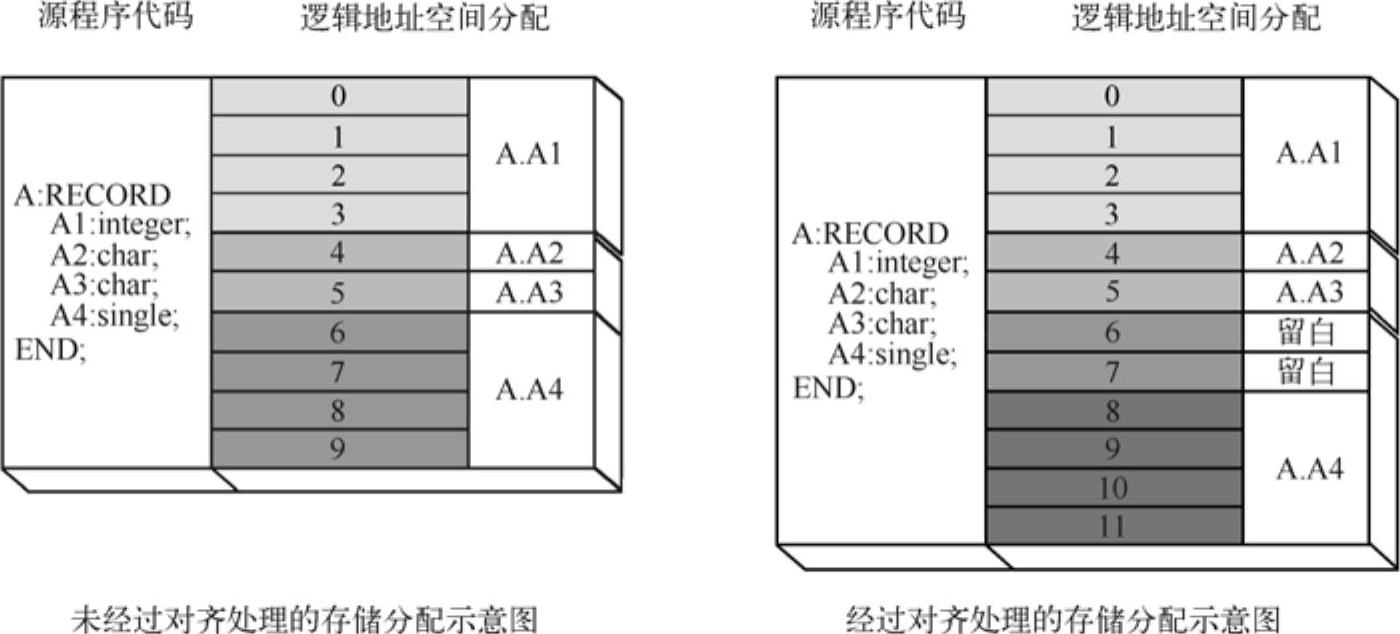
图8-3 存储布局的比较
在图8-3的左图中,不难发现A.A4这个4字节数据的起始地址是不符合整字对齐要求的。最简单的解决方法就是适当地留白,实践证明,以少量的存储区域来换得效率的提高是完全值得的。不过,实际情况却并非如此简单。例如,声明8-1如下:
【声明8-1】

根据先前的解决方法,编译器必须为Al、A3两个数据对象之后分别留白3B的空间。有效的数据空间仅为10B,而留白的空间却达到了6B,这恐怕是程序员与编译器设计者都不能接受的。因此,这个存储布局方案是值得商榷的。(https://www.daowen.com)
在现代编译器设计中,人们提出了一种更有效的存储布局方案,就是打破声明次序的先后原则,按照数据对象占用空间的实际大小顺序,由小至大(或由大至小)地依次分配。这样,就能有效地避免因用户声明次序的不合理导致留白过多的问题。这种处理方法的实现代价较小,但对节省存储空间却是效果显著的。
下面,再来看看更一般化的存储布局问题。这里,读者应该了解一个概念,编译器存储分配的基本单位是什么?实际上,几乎所有的编译器都是以过程或函数为单位来分配存储区的。也就是说,编译器将一个过程或函数内的所有局部变量收集起来,组成一个数据块。而全局变量则是独立组成一个或多个数据块,这可能是根据目标机体系结构而定的。然后,编译器以数据块为单位进行存储分配。C、Pascal等都是如此。当然,这里并不考虑优化技术产生的影响。在优化的前提下,讨论变量的存储分配是不合适的。那么,编译器为什么以过程或函数为单位进行存储分配呢?这里先不作解释,当读者阅读完本章内容后就明白了。
了解了存储分配的基本单位后,讨论基于整个用户程序的存储布局问题就变得非常容易了。实际上,编译器只需将一个过程或函数内的所有局部变量都看作是某一虚拟记录类型的字段列表,这样就可以依据记录类型变量的存储布局原则讨论所有用户变量的存储布局了。通常,可以得到若干以过程、函数为单位的逻辑数据块以及若干全局变量的数据块,这些就是存储分配的对象。为了便于讨论,本书假设只存在一个全局变量的数据块。
前面,主要讨论了存储布局的一些基本问题。无论是记录字段,还是局部变量的存储布局都涉及对数据对象的重新排序。因此,有两个要点是值得注意的:
(1)重排的安全性。事实上,重排的安全性更多是取决于高级语言本身的设计规范,即语言各种数据对象的存储布局是否公开。如果语言向用户完全公开数据组织与存储布局结构,例如,规定记录的字段列表的组织顺序即为声明顺序,那么,编译器是不能随意更改其存储布局的,否则,一切不安全性都应该由编译器负责。然而,如果语言并没有明确公开存储布局,而用户仅仅是凭借经验推断,那么,重排可能带来的某些不安全性就应该由用户承担。典型的例子就是应用指针的自增方式来遍历函数局部变量或记录字段。
(2)重排的方式。最常见的重排方式就是以占用空间大小排序,这几乎是没有争议的。不过,到底是以逆序还是顺序重排,不同编译器的实现是存在一定差异的。事实上,两者各有优缺点,并不能一概而论。针对不同的声明形式,读者只需进行少量实验,即可了解两种重排方式的优缺点。本书就不再深入讨论了。
至此,已经详细讨论了存储布局的相关话题,了解了离散的数据对象是如何被组织成数据块的,并且明确了存储分配的基本单位是数据块。存储布局的设计思想更多是源于实践总结,并没有太多的理论支持。随着高级语言功能的丰富,存储布局的问题也是与时俱进的,因此,深入研究这一话题是有现实意义的。例如,托管机制、索引器等都对传统编译器的存储布局机制提出了挑战。不过,笔者想再次强调的是,存储布局通常只是讨论合理与否,要做到真正的最优却并不容易。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。




