复写传播(copy propagation)是一种代码转换,其基本思想如下:对于给定的关于某个变量v和s的赋值V←s,在没有出现其他关于v定值的程序范围内,编译器用s来替代出现的v的引用。从定义上来说,不难发现复写传播与常量传播有着惊人的相似之处。的确如此,这正是传播优化的基本思想。下面,通过一个简单的实例来解释复写传播的方法及意义。
例7-5 局部复写传播的实例。见表7-7。
表7-7 局部复写传播的实例分析
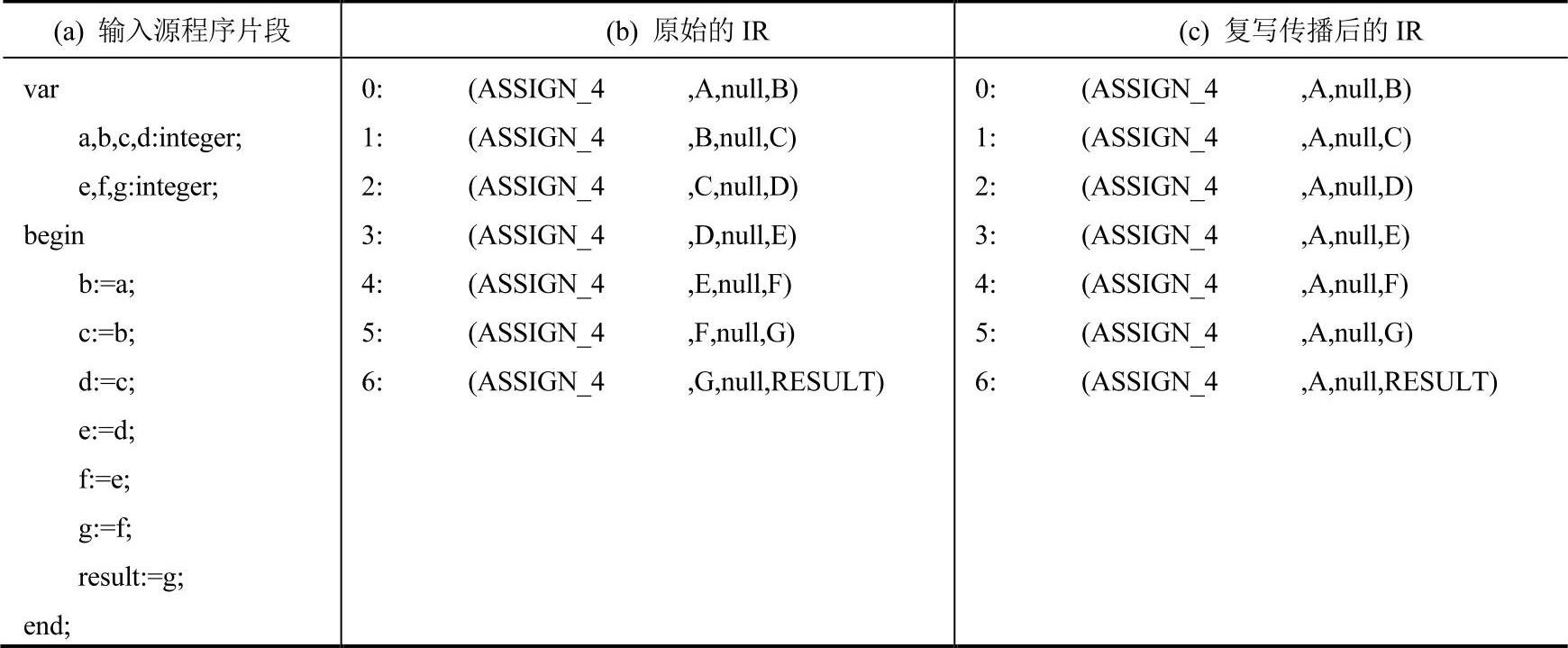
从形式上来说,这个实例可能有些极端,但非常有利于说明复写传播的方法及意义。比较(b)、(c)两列,不难发现,(c)列中所有指令的第1个操作数都被替代为“A”。根据复写传播的定义,由于(b)列中第0行是B←A的赋值,而整个程序中并不存在其他关于B的定值,编译器则可以用A来替代所有出现的对B的引用。因此,将第1行替换为C←A的赋值。以此类推,不难得到(c)列的结果。关于复写传播的方法,应该并不难理解。
复写传播的现实意义是什么呢?或者说,相比(b)列代码而言,(c)列代码的优势是什么呢?实际上,复写传播的意义就是在于尽可能减少程序中的活跃变量的个数。从一个函数的角度来说,只有RESULT是活跃变量,因为它是用于存储函数返回值的,其他的变量在离开函数体后,都是没有意义的。当然,除了RESULT之外,与RESULT定值相关的变量也将是活跃的。先来分析(b)列代码的活跃变量的个数。由于RESULT值是从G中得到的,故G也是活跃的。而G的值又是从F中获得的,因此F也将是活跃的。以此类推,(b)列代码中A、B、C、D、E、F、G都将是活跃变量。以同样的方法分析(c)列代码,不难发现,其中只有A是活跃变量。根据先前关于活跃变量的讨论,对于非活跃变量的赋值操作都是没有意义的,即可删除。这样的话,(c)列代码最终就只剩下最后一行IR了,这个成果是令人可喜的。不仅如此,就本例而言,当删除了(c)列中冗余的赋值之后,由于整个程序中不存在任何关于B、C、D、E、F、G的引用与定值,因此,编译器不必再为这些变量分配存储空间。(https://www.daowen.com)
同样,复写传播也可以分为局部遍与全局遍,即局部复写传播与全局复写传播。前者是基于基本块内实现的,而后者是基于整个过程讨论的。这里,就不再详细分析全局复写传播的实例了。复写传播虽然成效显著,但并不是万能的。在一些特殊的情况下,复写传播是可能失效的。正如先前讨论的,优化算法都是针对某类特殊问题的一种解决方案,不可能要求一个优化能做到以不变应万变。
在实践中,有些初学者可能试图使用复写传播优化如图7-8所示的结构。实际上,这是完全徒劳的。这种代码形态已经不是复写传播讨论的范畴了。读者仔细推敲复写传播的定义,不难发现,定义中非常明确地指出了复写传播的前提只是v←s的赋值,而其中并不能含有其他运算。当然,在图7-8中,形如基本块B2、B3中的i—j+l也是不能接受的冗余。在现代编译技术中,通常使用一种称为尾融合的算法来实现两个复写赋值的合并。尾融合的基本思想就是将B2、B3这两个基本块尾部相同的代码提取出来,移至另一个新生成的基本块B5中。删除B2、B3与B4的后继关系。同时,令B5成为B2、B3的唯一后继基本块。而B5的后继基本块即为B2、B3的原后继B4。
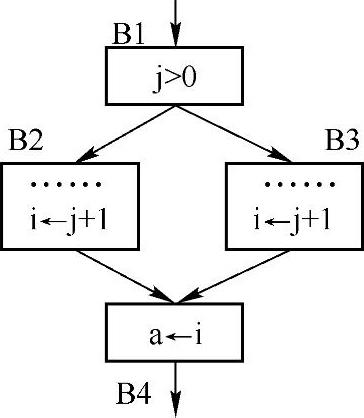
图7-8 尾融合的实例
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。







