在Neo Pascal中,许多优化算法都是基于ud链、du链信息实现的。相比先前的数据流分析算法而言,ud链、du链分析可能稍复杂。
1.du链分析算法
du链分析算法的基本步骤是:
1)在基本块内,分析当前IR之后是否存在其他IR对当前变量的定值。如果存在,则du链仅包含两条定值IR之间的对当前变量的所有引用点,并结束分析。如果不存在,则执行步骤2。
2)沿流图向下流的边,查找各条可能路径中最先出现的对当前变量定值的IR位置。如果查找成功,则将查找该IR过程中所经过的所有对当前变量的引用点都加入du链。如果查找失败,则将整个查找路径中的所有对当前变量引用的IR位置加入du链中。
du链分析算法的关键就在于搜索流图的可能路径。实际上,搜索流图路径的算法是图深度遍历的一种特殊应用。对于不熟悉图深度遍历算法的读者,建议阅读数据结构相关章节。设计搜索流图路径算法时,有个细节值得注意,那就是环路的处理。
流图并不是DAG结构,在很多情况下,流图中可能出现有向环。路径搜索算法应该注意环状结构的处理,避免进入循环搜索。在图深度遍历算法中,通常是借助于一个顶点集合来避免结点的重复访问。即把己访问过的结点存放到一个顶点集合中,每次访问一个结点前,依据顶点集合判定该结点是否已访问。这里,值得注意的是,在ud链、du链分析中,起始结点(即当前IR所在的结点)是需要特殊处理的。与其他结点不同,起始结点并不是在第一次访问时,就将其加入顶点集合的。其中最主要的原因就是流图可能存在类似于图7-7所示的特殊环路,即某一个结点存在一条流向自身的边。以图7-7为例,讨论P2处关于i的du链。如果起始结点的处理与其他结点一样,那么,搜索算法首次访问起始结点时,首先将其加入顶点集合,再依据du链分析算法从当前IR所在位置(即P2)开始向下搜索。显然,本次访问并不会涉及Pl处的IR。当P2之后不存在任何对i的定值点时,du链分析算法就沿流图向下流的边搜索可能的路径。此时,搜索算法将第二次访问到起始结点,但是该结点已存在于顶点集合中,即表明该结点己被访问过了,因此就直接略过了。至此,该路径也就搜索完毕了。不过,整个过程中始终没有处理Pl处的IR。根据流图所示,显然P2处对i的定值是可以到达Pl的。最简单的解决方法就是在第二次访问起始结点时,将其加入顶点集合。下面将详细分析du链分析算法的源代码实现。
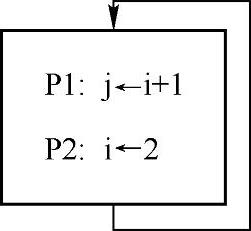
图7-7 特殊的环路
程序7-6 DataFlowAnalysis.cpp


第5、6行:判断当前基本块是否己访问。其中,bHasVisit即为先前讨论的顶点集合,其声明形式如下:
【声明7-9l
set<int> bHasVisit;
如果当前基本块的位序号己存在于bHasVisit中,即表示该基本块己被访问,故返回即可。
第8~13行:将当前基本块的位序号加入bHasVisit集合中。其中,bFirst是一个布尔变量,用于满足起始基本块特殊处理的需要。
第14行:调用BackwardHasDef分析当前基本块内自iStart之后是否有其他IR对当前变量进行定值。如果存在,BackwardHasDef将返回该定值点的位置,否则返回-1。关于BackwardHasDef函数的实现稍后详解。
第15~21行:如果i!=-l,即当前基本块内自iStart之后有其他IR对当前变量进行定值,那么,将两条IR之间所有关于当前变量的引用都加入tmp向量中。否则,将当前基本块内自iStart之后所有关于当前变量的引用都加入tmp向量中。
第22~25行:如果i!=-l,则无需沿流图向下边搜索可能的路径,返回tmp即可。
第28~35行:沿流图向下边搜索可能的路径,并将搜索过程中求得的引用点集合加入tmp向量中。值得注意的是第31行递归调用语句。有读者可能会问:为什么第3个实参需要在CurrentB asicBlock->at(i).iStart的基础上减1?原因很简单,主要是为了适应当前IR处理的特殊需要。在起始基本块中,搜索引用点是从当前IR之后开始的,而不是从当前IR开始的。举个简单的例子,讨论a←a+l中a的du链时,在不考虑循环的情况下,可以断定对a的定值是不可能到达本句IR中对a的引用点的。因此,在第14行中,调用BackwardHasDef函数搜索当前引用点集合时,第2个参数是iStart+l,而不是iStart。但除了起始基本块外,其他基本块却无需考虑这些特殊处理。为了兼容BackwardHasDef函数,这里不得不预减1。
下面来看BackwardHasDef的源代码实现。
程序7-7 DataFlowAnalysis.cpp


第4行:从VarDef中获取关于给定变量的定值集。
第5行:如果给定变量的定值集为空或者给定检索范围为空,则返回一1,表示检索失败。
第10~16行:检索给定范围内的定值点。注意,定值集是按IR的位序号升序排列的,这是由定值、引用点分析算法处理的。因此,算法的实现就相对简单。
第17~21行:返回检索结果。如果检索成功,则返回定值点信息,否则返回一1。
2.ud链分析算法
ud链分析算法的基本步骤是:(https://www.daowen.com)
(1)在基本块内,分析当前IR之前是否存在其他IR对当前变量的定值。如果存在,则ud链仅包含该定值点,并结束分析。如果不存在,则执行步骤2。
(2)沿流图向上流的边查找各条可能路径中最后出现的对当前变量定值的IR位置。如果查找成功,则将该定值点加入ud链。如果查找失败,则不做任何处理。
这里,主要讨论ud链分析算法在编译器设计中的一个特殊应用,即判定变量使用前是否初始化的问题。在大多数语言中,关于变量使用前是否必须初始化的问题,并没有提出明确的规定。在实际编程中,程序员应该杜绝此类情形的发生。由于各种编译器的实现差异,故此类异常是随机的,这是非常可怕的。即便如此,编译器最多只能对这类现象给出语义警告而己,却不能强制禁止,除非语言有明确的约定。当然,并不要求编译器对此类问题一定要给出显式的警告或者其他提示。事实上,有些编译器对此并不关注。不过,数据流分析必须得到精准的分析结果,否则可能影响编译正确性。
严格地说,变量使用前未初始化的问题可以归入语义分析中讨论。但是,在语义分析阶段,编译器试图判定输入程序是否存在这类情形是非常困难的。因此,比较理想的解决方法就是在ud链分析算法中实现。那么,如何从ud链分析中获取相关的信息呢?假设从某个变量引用点出发开始分析该变量的ud链,在分析过程中,可以发现存在至少一条从流图的入口到当前引用点的路径,且该路径上没有任何对该变量的定值点。那么,也就表示该变量可能存在未初始化的情形。
ud链分析算法的大致框架与du链类似。从算法实现来说,ud链分析可能更简单些。下面,就来看看相关源代码的实现。
程序7-8 DataFlowAnalysis.cpp

第5、6行:判断当前基本块是否已访问。这与du链分析算法是类似的。
第8~13行:将当前基本块的位序号加入bHasVisit集合中。其中,bFirst是一个布尔变量,用于满足起始基本块特殊处理的需要。
第14行:调用ForwardHasDef分析当前基本块内自iStart之后是否有其他IR对当前变量进行定值。如果存在,则ForwardHasDef函数将返回该定值点的位置,否则返回一1。
第15、16行:如果已经遍历到流图的入口结点且仍没有找到定值点,则表示存在变量使用前未初始化的情形。
第17~20行:如果i!=-l,则无需继续沿流图向下边搜索,返回tmp即可。
第23~32行:沿流图向上边搜索可能的路径,将路径中最后一个定值点加入tmp向量中。由于遍历IR的过程是自下而上的,因此,路径中的最后一个定值点也就是遍历过程中的第一个定值点。如果检索成功,则不再继续遍历本条路径。在第27行中,递归调用GetUd函数时,第3个实参的情况与GetDu函数类似,这里就不再解释其原因了。
ForwardHasDef的源代码实现与BackwardHasDef非常类似,这里,笔者仅给出源代码,详细的解释请读者参阅BackwardHasDef函数。
程序7-9 DataFlowAnalysis.cpp

前面,已经详细讨论了ud链、du链分析算法的实现细节。这两个算法是针对一个特定的程序点讨论某一变量在该程序点上的ud链、du信息。最后,来看看ud链、du链分析的主控函数,以便了解主控函数是如何调用GetUd、GetDu函数实现ud链、du链分析的。
程序7-10 DataFlowAnalysis.cpp



第3行:获取当前过程的基本块信息。
第5~16行:遍历当前过程的IR列表,清空各操作数的ud链、du链。
第17~58行:遍历流图中各基本块。
第20~57行:遍历基本块内的IR序列。
第24~29行:获取处理方案。
第36--42行:调用GetUd函数,分析m_Op2的ud链信息。注意,在ud链分析中,不分析间接寻址变量的ud链信息。由于Neo Pascal并没有打算做指针相关的优化,因此,分析间接寻址变量的ud链信息的意义不大。当然,目前的定值、引用点信息也不足以完成分析间接寻址变量的ud链。
第43~49行:调用GetUd函数,分析m_Opl的ud链信息。
第50~55行:调用GetDu函数,分析m_Rslt的du链信息。
至此,已经详细阐述了经典编译技术中关于数据流分析的一些基本思想与算法实现,并结合Neo Pascal剖析了几个最为常见的算法模型。数据流分析是优化技术中一个重要且复杂的话题。虽然笔者尽可能结合程序实例与Neo Pascal源代码解释一些经典的数据流问题,但是,对于没有学习过编译原理的读者来说,理解上述内容可能还是有一定难度的。针对尚未深入理解算法实现的读者,笔者的建议如下:暂且不必关注源代码实现,可以先把握两个要点。第一,理解数据流分析的一些名词概念;第二,理清Neo Pascal数据流分析算法的主要数据结构。这两个要点是学习后续章节的基础,相信读者阅读完本章内容之后,可能会对数据流分析有更深刻的认识和理解。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





