定值点与引用点的分析是实现数据流分析的基础,通常涉及的绝大多数数据流问题都是基于这两者讨论的。在经典编译技术中,关于定值点、引用点的讨论通常是比较精炼的,并没有太多的理论与技术。确实,基于一种模型语言讨论定值点、引用点的分析是相对比较容易的,它规避了许多现实中的细节问题。然而,对于一门实际语言而言,试图设计一个较完备的分析算法却并不简单,需要关注的问题远比模型语言复杂得多。下面,来谈一些与实际语言相关的定值点、引用点问题。
1.全局变量
与局部变量不同,全局变量的定值点、引用点可以散布于整个程序范围内。因此,讨论全局变量的定值点、引用点并不是一件容易的事。这应该不难理解,因为任何一次有效的函数调用都可能引用或改变全局变量的值。要准确分析全局变量的定值、引用信息,就必须分析过程、函数的调用关系,只有基于完整的调用关系图才可能分析得到较为精准的结果。这种分析算法就是通常所说的过程间数据流分析。事实上,过程间数据流分析不仅解决了全局变量引用、定值的问题,同时也可以为分析函数对实参的影响提供必要的决策信息。不过,过程间数据流分析也是一项具有挑战性的工程,其难度主要体现在如下两个方面:
(1)当源语言支持函数指针之类的语法结构时,问题可能会变得异常复杂。
(2)多文件编译机制使得过程间数据流分析不得不在链接阶段完成。
试图完美地实现过程间数据流分析是需要付出一定代价的。这是因为过程间数据流分析是由链接器完成的,而不是由编译器完成的。其中,最主要的原因就是多文件编译机制的存在。下面,笔者通过一个实例来分析多文件编译对过程间数据流分析提出的挑战。
如图7-6所示,这个C语言项目包含a.c、b.c两个源程序文件,右列则详细描述了这个项目的编译过程。绝大多数C编译器都是依据这个过程完成编译、链接的。首先,编译器分别编译a.c和b.c,并生成相应的汇编文件。然后,由汇编器生成对应的obj文件。最后,由链接器将多个obj文件链接成一个可执行文件。因此,试图在编译阶段实现准确的过程间数据流分析可能是徒劳的。例如,在编译a.c时,编译器根本不可能预测aa()函数对全局变量的影响,也无法得到aa()函数内部的调用关系图。在整个处理过程中,只有链接阶段才能对整个项目有一个全局的概括。因此,也只有链接器才可能实现真正的过程间数据流分析。不过,obj文件中存储的是二进制机器码及重定位、符号等信息,故仅仅依据obj文件的信息,试图在链接器中实现数据流分析是非常复杂的。因此,一些商用编译器开发商自主研发汇编器及链接器的一个重要原因就是试图让链接器可以从一些由编译器生成的格式文件中获取更多关于输入源程序的信息,而不仅仅依赖于obj文件。以微软的编译器为例,它提供了一个“/GL”选项,有兴趣的读者可以参阅MSDN相关文档,其中明确说明了启用全程序优化(即过程间优化)前后,生成的obj文件是完全不同的。
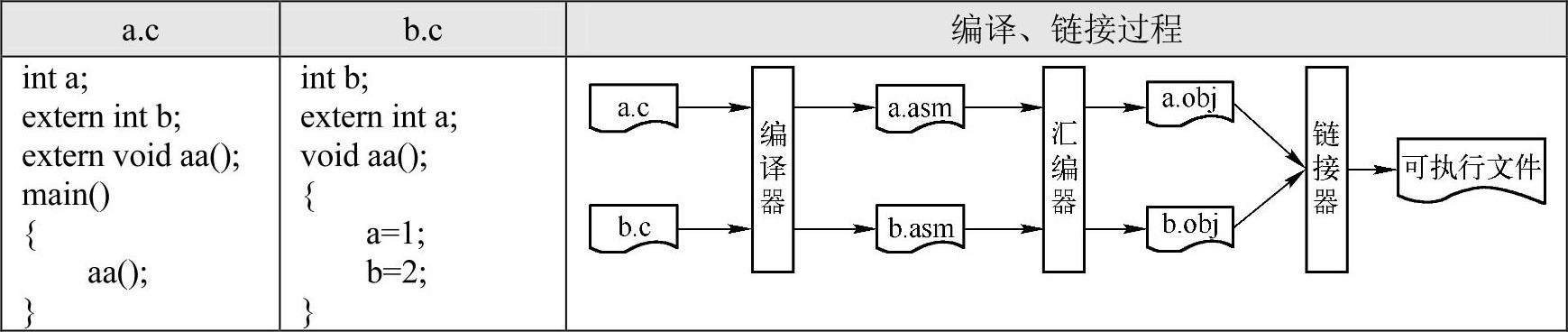
图7-6 多文件编译示意图
鉴于语言的特性,Neo Pascal并没有考虑过程间数据流分析,只是用了一个消极的策略,除了普通的定值、引用形式之外,假设每一个有效的过程、函数调用点都可能对全局变量定值、引用。虽然这种处理方式并不够完美,但也是工程领域可以接受的。
2.内嵌汇编(https://www.daowen.com)
一些经典程序设计语言都支持内嵌汇编机制,例如,C、Pascal等。从表面上来看,内嵌汇编机制的实现似乎是非常简单的,只需将相应的汇编源代码复制到目标代码中即可。不过,事实却远比想象的复杂。Neo Pascal的处理方式与GCC类似,即编译阶段不识别内嵌汇编,而直接将内嵌汇编粘贴到目标代码中。换句话说,编译器根本不需要关注内嵌汇编的语法与语义,而是统一由汇编器处理。不过,相应的问题也就由此产生了,即编译器如何估计内嵌汇编对程序变量的影响。事实上,对于不识别内嵌汇编的编译器来说,是根本不可能预计内嵌汇编对程序变量的定值、引用情况的。在GCC中,编译器将这项烦心的工作交由用户完成。也就是说,用户以参数形式显式说明当前内嵌汇编中的定值、引用信息,尤其是对C变量的影响。
虽然这种处理方式表面上看起来并不完美,但也不失为一种高效的解决方案。编译器只需根据用户的参数标记定值、引用信息,即使内嵌汇编中存在额外的定值、引用也不必理会。如果因此产生副作用而导致优化不安全,其中的责任完全是由用户承担。当然,不同的编译器对内嵌汇编的处理方式是不尽相同的。有些编译器可能会在编译阶段识别与分析内嵌汇编。在这种情况下,编译器就可以根据得到的汇编源代码的实际情形分析定值、引用信息,例如,Delphi就采用了这种处理方式。
3.指针引用
在现代编译技术中,关于指针引用的分析是一个非常复杂的话题。相信对于了解C语言指针的读者来说,其中的原因不必多作解释了。事实上,在很多情况下,即使是人工分析指针的引用关系都是困难重重的,更何况是由编译器来完成。早期的Pascal规定指针所指向的对象只能是动态申请的,不允许使用“@”运算符对普通变量取地址。这样做的目的也就是为了便于处理指针引用的问题。在这种情况下,编译器不必关注指针与普通变量的差异,只需一视同仁地分析定值、引用信息即可。因为无论指针如何设置,它指向的对象都是在执行过程中动态申请存储空间的,因此不可能影响用户声明的普通变量。
如果语言提供的指针机制比较完善,即允许指针指向普通变量。那么,这种情况下,分析指针引用或可能引用的信息是非常必要的。在数据流分析中,指针处理的复杂性主要体现在对指针的间接寻址上。例如:

在最后一句IR中,形式上似乎是对P的定值。不过,由于结果操作数是对P的间接寻址,所以其实际定值是对P所指向的变量而言的,而不是P本身。反而这句IR却是P的一个引用点,因为间接寻址访问依赖P所存储的值(即所指向对象的地址)。那么,编译器又该如何确定哪些变量可能被P引用呢?在现代编译技术中,别名分析的话题已经并不陌生了,但是,试图准确分析这个集合仍然不是一件简单的事情。
与指针引用类似,变参传递同样存在间接寻址的问题。当然,试图分析变参引用对实参的影响可能比指针引用的分析更为复杂。变参引用不但需要考虑函数体内的逻辑,还可能涉及过程间的分析。
这个问题,一些研究型的编译器通常很少涉及,即使是商用编译器的实现也并不完美。出于实现代价的考虑,Neo Pascal并没有采用精准的引用分析策略来解决指针引用的问题,而是采用一种比较保守的策略。例如,假设上例的IR序列中不存在其他的取址IR(即GETADDR指令)时,试图精确了解P指向的目标变量就必须分析程序的控制流,甚至还不能忽略指针之间赋值带来的副作用。不过,在不考虑“精确”的情况下,这个问题可能就不难解决了。可以肯定地得到一个P可能指向的目标变量集(I,J),因为整个IR序列中只存在对I、J的取址操作。当然,由于指针之间可能存在赋值,因此,安全且保守的做法就是假设所有的被取址变量对于任意指针都是有效的。在上例中,即使第1行IR的结果操作数不是P,而是其他的指针变量R,依然不会影响P的可能目标变量集。虽然这种策略并不激进,但它却得到了许多编译器设计者的认可。甚至还被一些早期的商用编译器采用。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。




