数据流分析(data-flow analysis)指的是一组用来获取有关数据如何沿着程序执行路径流动变化的相关信息的技术,这些信息对于优化算法设计是极其重要的。从程序执行的角度而言,数据流分析就是把每个程序点和一个数据流值关联起来的过程。而这个数据流值就是该程序点所能观察到的所有程序状态的集合(即程序所有变量值的集合)的抽象形式。同时,希望得到程序中每个位置点上的数据流值。在优化编译器中,数据流分析的主要目的就是在保证安全的情况下定位优化的机会。告知优化算法哪些位置可以进行代码变换,以获得更优的执行效果。
与优化算法类似,通常可以将数据流分析分为两类,即基本块内分析与基本块间分析。由于基本块内的IR都是自上而下顺序执行的,根据IR的语义,确定每句IR的数据流值并不是非常困难的。当然,对于某些支持指针或引用的编译器来说,问题可能会复杂一些。
基本块间的数据流分析是基于流图讨论的。块间分析主要是根据流图建立相应的数据流方程组,并设计迭代算法实现求解方程组的过程。块间数据流分析也称为“全局数据流分析”,是优化技术中一个重要的研究领域。本章将重点讨论这一话题。
无论是块内数据流分析还是块间数据流分析,都不得不面临一个问题,那就是必须严格区分“可能”还是“必然”。
如图7-3所示,请问哪些关于变量j的定值IR能够到达第5行的引用处?第4行IR中j的定值是必然能够到达的,这是毋庸置疑的。那么,第2行IR的j的定值是否能够到达呢?实际上,这只是一个可能到达的定值点。如果指针k指向变量j时,第3行IR的定值将影响变量j的值,那么,此时第2行的定值就不可能到达第5行。然而,仅依据图7-3,编译器根本无法判断k具体指向的变量。针对这种情况,编译器设计者只能认定第2行的定值是无法到达的,否则可能导致优化算法不安全。(www.daowen.com)
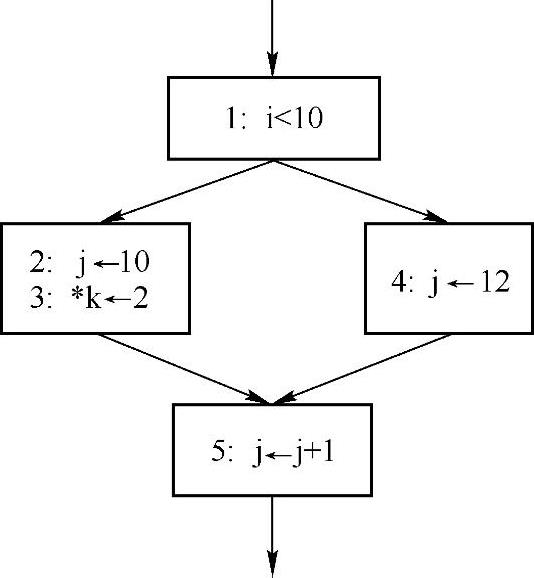
图7-3 可能定值的流图
当然,读者可能会想到对k的引用情况进行分析,这是完全可行的。不过,其分析过程却是比较复杂的,因为设计者不得不考虑二重或多重的指针引用情况。在现代编译技术中,针对指针、引用、别名等语言机制,通常有两种策略:积极的和消极的。所谓“积极”就是对引用、指针、别名进行完整的分析,然后,基于分析结果实现更精准的数据流分析。所谓“消极”就是以一种比较保守的态度处理引用、指针、别名等,充分考虑存在“可能”的条件。相对而言,消极方式的实现要简单一些,它不必准确地进行引用、别名等分析。虽然基于消极方式实现的数据流分析可以被大多数编译器接受,但也不可否认一个事实:这种分析方法必然会影响结果的精准程度,也不可避免地会对优化效果有一定副作用。
最后,笔者再次强调:安全性是一个原则问题,是不容置疑的。无论使用何种优化策略或分析方法,每一个转换动作执行的前提就是保证转换的正确性。针对“可能”还是“必然”的问题,考虑安全性可能比其他任何因素都重要。优化失效是可以接受的,但不安全的优化却是不能接受的。尤其是在分析一些复杂的指针、引用操作时,这是最容易忽视的。例如,引用参数可能给实参带来的副作用、多重指针的真实目标等都是需要考虑的。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。




