记录是由若干己知类型的数据元素组合而成的一种复合数据类型,C语言中称之为“结构”。众所周知,记录类型有一个非常重要的特点,就是记录变量的字段(分量)是连续存储的。因此,根据操作数的字段名,编译器是可以得到相应的常量偏移的。如图6-9所示。
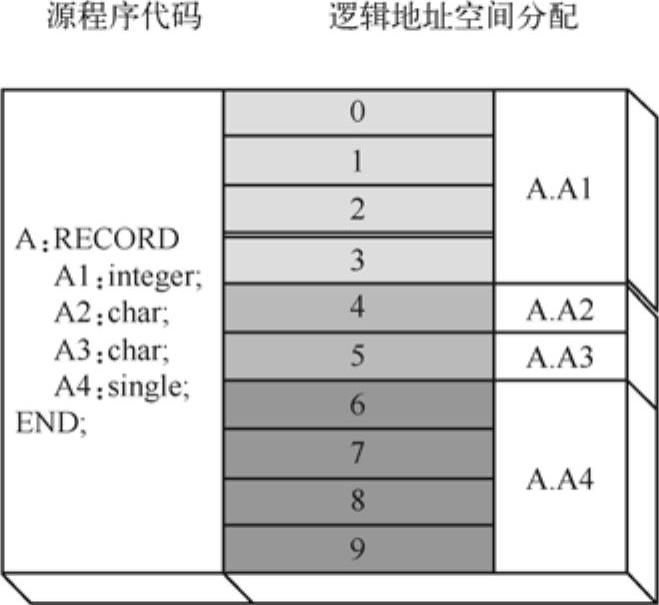
图6-9 记录存储分配示意图(未经过数据字对齐处理)
这是记录类型变量A的标准存储形式,从图中可以看到编译器是按字段声明的先后顺序,依次组织各字段数据的。由此,编译器就可以根据符号表相关记录计算得到一个相对于逻辑空间块首地址的常量偏移。实际上,上图所示并不一定是记录类型变量A的实际存储形式。在存储分配时,根据字段的类型信息,分配算法将得到一个更合理的分配方案,未必是简单地按字段声明先后来组织字段的存储结构的。存储分配是一个比较复杂的话题,笔者将在后续章节中详细讨论。不过,无论记录类型变量的内部组织形式如何,有一个事实是不可否认的,那就是字段相对于记录变量首地址的偏移在编译阶段是已知的常量。迄今为止,绝大多数程序设计语言仍然是遵守这个约定的。虽然一些新型语言对传统的记录类型的理解或实现可能存在一定的差异,但始终没有突破这一底线。
在记录类型的字段信息表中专门有一个属性(m_iOffset)用于描述字段相对于记录变量首地址的偏移。这里,读者并不需要关心编译器如何计算m_iOffset属性,只要知道如何应用即可。下面,先来看看记录字段操作数的相关文法:
【文法6-4】
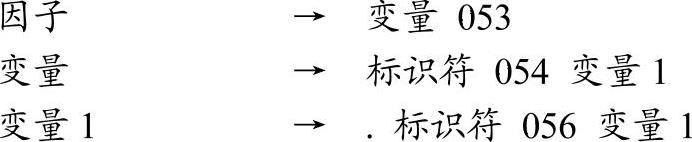
笔者已经详细分析了semantic053与semantic054的实现。由于简单变量操作数并不涉及偏移量的问题,所以不需要生成计算偏移的IR语句。然而,本小节将更多关注操作数偏移的相关话题,这是因为记录字段操作数是需要偏移信息的。实际上,操作数偏移的问题远比操作数寻址复杂得多,针对不同的代码情景,编译器设计者必须做非常周详的考虑,否则很难保证编译的正确性。例如,a[i].p、a[l]^.p或者a^.p等形式的处理。从文法上来说,不难发现,处理操作数偏移的动作就是由semantic056完成的。因此,详细分析semantic056的实现对于理解操作数偏移处理的基本思想是非常重要的。
根据当前操作数信息(即CurrentVar的栈顶元素),通常分为如下三种情形处理:
(1)当前操作数没有偏移,即CurrentVar.栈顶元素的m_eOffsetType值为NoneOffset。由于记录字段的偏移是常量偏移,所以只需将常量偏移登记在当前操作数信息中即可,以便semantic053统一处理。
(2)当前操作数的偏移类型为常量偏移,即CurrentVar的栈顶元素的m_eOffsetType值为ConstOffset。由于当前操作数的原偏移与当前记录字段的偏移都是常量偏移,那么,编译器就必须将两个常量偏移相加折叠。
(3)当前操作数的偏移类型为变量偏移,即CurrentVar的栈顶元素的m_eOffsetType值为VarOffset。在这种情况下,不存在常量折叠的可能性,所以编译器只能生成相应的IR语句,以完成偏移值的累加。
程序6-12 semantic.cpp(https://www.daowen.com)


第3~7行:如果当前主符号是常量符号,那么,对常量进行“.”运算是无意义的。
第12~18行:遍历当前操作数的字段列表,以获取相应的字段信息。编译器以输入标识符为关键字检索当前操作数所属记录类型的字段列表,以此判断输入标识符的有效性。
第19~20行:输入标识符的有效性检查。根据文法形式,输入标识符必定是当前操作数所属记录类型的某一字段,否则即存在语义错误。
第22~24行:根据检索结果,令pFieldlnfo指向相应字段,以便后续处理。同时,获取该字段的偏移信息。
第26~29行:如果当前操作数的偏移类型为无偏移,则只需直接修改当前操作数相关属性即可。
第30~34行:如果当前操作数的偏移类型为常量偏移,则完成常量偏移的折叠。也就是用两个常量偏移的和生成一个新的常量,并将该常量的位序信息存入iTmpOffset变量中,以备后用。注意,iTmpOffset变量就是用于存储操作数偏移的位序信息,并不严格区分常量信息表或变量信息表,而是视结果偏移信息的实际情况而定的。
第35~49行:如果当前操作数的偏移类型为变量偏移,则直接生成计算偏移的IR。实际上,就是生成一条操作码为“ADD_4”的IR语句,将当前操作数的偏移与当前字段的常量偏移相加后暂存于一个临时变量中。这里,分别声明了三个OpInfo对象,即Opl、Op2、Rslt,主要用于表示当前操作数的偏移、字段的常量偏移及结果操作数。当然,在生成IR后,必须注意Operand栈的维护。
第50~56行:生成一个Var对象,设置完相应的属性后压入Operand栈。值得注意的是m_VarTypeStack栈的设置。m_VarTypeStack栈主要是用于跟踪操作数类型的变化情况,并予以记录。其中,栈顶元素描述的就是当前操作数的类型信息。实际上,在调用semantic056之前,当前操作数是一个记录类型变量。然而,在调用以后,当前操作数就是一个记录字段变量。为了跟踪类型变化的过程,通常会将当前操作数的最新类型信息压入m_VarTypeStack栈,而不是简单地覆盖原始类型信息。
至此,笔者已经分析了记录字段操作数的翻译与处理过程。其中,常量偏移的折叠是关键所在,了解了常量偏移的处理对于理解后续章节是相当有用的。事实上,严格来说,常量偏移的折叠是常量折叠的一种特例,也是IR优化讨论的范畴。在语义处理中,完全可以将其忽略,直至IR优化再作处理。不过,笔者却不认为这是一个值得提倡的做法。在设计一些类似于编译器之类的复杂系统时,应该尽可能避免将即时出现的问题延后到后期处理,因为期间可能发生的变化有时是很难预见的。虽然IR优化作为单独的一遍存在于整个编译过程中,但是,并不意味着必须将所有的优化问题集中到这一点上处理。笔者的观点是适时而动,即在最有利于解决某一问题的时刻处理该问题是最优的选择,而不必过多拘泥于模块结构的限制。在C编译器中,逻辑表达式的短路问题亦是如此。当然,也可以将短路问题视作IR优化的范畴,不过,可能因此而付出巨大的代价。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





