前面已经对“简单变量”的概念作了相关的说明。本小节将关注简单变量的语义处理动作的设计及其实现。那么,直接引用一个标识符来表示的操作数必定是简单变量操作数吗?答案是否定的,事实上,with结构和过程调用语句是不可忽略的。下面对这两个话题作简单讨论。
with结构是一种比较特殊的语法机制,其设置的目的就是为了便于程序员对记录字段的引用。因此,在处理简单变量操作数时,需要区分通过with结构引用记录字段的情形。当然,从某种角度而言,with结构可能降低程序的可读性,尤其是多层嵌套的with结构可能导致程序的结构比较零乱。因此,包括C语言在内的很多程序设计语言是不提供with结构的。不过,作为一个Pascal编译器,Neo Pascal还是继承了标准Pascal的with结构。
先简单介绍一下Pascal语言的with结构。如图6-8所示,这是一个关于with结构的例子,程序中有3条赋值语句,不过,它们的赋值对象却是完全不同的。这是由with结构的优先引用原则决定的。在with结构中,当字段名与其他对象重名时,字段名将被优先引用,这和全局变量、局部变量重名时的处理原则是一致的。另外,当with结构嵌套时,在内、外层字段名重名的情况下,内层字段将屏蔽外层字段。设计者需要关注with结构的两个基本特性,它们是编译器设计的准则。虽然编译器设计者对with结构其他特性的理解可能存在一定的差异,但这两个基本原则似乎是不可突破的底线。
除了with结构之外,还需要考虑函数调用语句的情况。判断标识符是不是函数名应该并不复杂,只需遍历符号表即可。如果是函数调用,那么,编译器就应该生成相应的调用函数并获取返回值的IR。在处理函数调用时,还有一个问题不得不处理,那就是函数调用与with结构的优先关系。从理论上来说,函数调用与with结构之间是不应该存在二义性的,即使存在重名的情况亦是如此。不过,遗憾的是,标准Pascal的语义却并非如此。图6-8所示的程序,包括Delphi在内的许多Pascal编译器都不支持。换句话说,在with结构中,当字段名与其他对象(包括过程、函数)重名时,字段名将被优先引用。
了解了with结构及函数调用语句后,也就明确了哪些标识符属于简单变量操作数的讨论范畴了。而那些属于记录字段或者函数名的标识符当然就由其他语义子程序处理。由于操作数翻译涉及with结构处理的相关数据结构_WithStack栈,因此,笔者对此结构作简单说明。WithStack栈的声明形式如下:
【声明6-8】

图6-8 with结构的优先级

对于一个with结构而言,最重要的信息应该就是开域记录的相关信息。从文法上而言,标准Pascal的开域记录可以是由“变量”推导得到的任何形式,所以其形式还是比较复杂的。那么,以什么数据结构暂存开域记录的相关信息(编译信息)呢?当然,使用Var结构来暂存开域记录的信息应该是不错的选择。相对于OpInfo结构而言,Var结构可以提供更多有用的信息,而且便于被操作数翻译的相关语义子程序共享访问。通过m_Var字段,编译器可以轻松获得开域记录相关的类型信息,在semantic054中,就将涉及这方面的应用。当然,由于标准Pascal允许with结构嵌套声明,所以编译器必须借助于WithStack栈将每一层次开域记录的信息都予以保存。关于with结构的实现细节,将在后续章节中讨论。下面,再来看看简单变量操作数的相关文法:
【文法6-3】

程序6-10 semantic.cpp



第5~19行:遍历WithStack栈,判断当前输入标识符是否为开域字段名。根据标准Pascal的语义,编译器将由内向外逐层检索,即从WithStack栈顶向栈底逐一检索各个开域记录的字段列表。
第20~24行:如果当前输入标识符是开域字段名,则调用semantic056完成相应的语义动作。这里,先不必深究第22行、第23行的功能,笔者将在后续章节中详述。
第25行:检索过程信息表,判断当前输入标识符是否为过程名。
第26~83行:由于当前输入标识符不是过程名,即为常量符号名或变量符号名。因此,语义子程序主要完成两项工作:
(1)确定输入标识符是常量符号名还是变量符号名。同时,还需要确定该符号是全局符号还是局部符号。由于同一过程或函数内的符号常量名与变量名是不允许重名的,因此检索的先后顺序并没有本质差异。不过,根据全局符号与局部符号重名的相关规范,编译器应优先检索当前过程所属的局部符号列表。这个检索顺序是由语言规范确定的,编译器设计者不可随意改变。第29~65行的代码主要就是完成这项工作。
(2)根据当前输入标识符的性质,完成相应的语义动作。
如果该标识符是常量符号名,则直接生成一个OpInfo对象,设置m_iType属性为CONST,并设置m_iLink属性。最后,将其压入Operand栈。注意,常量符号与普通常量类似,无需借助于Var对象完成操作数翻译。这里,值得注意一点,第72行将bConstFlag标志设为true是比较重要的,有助于后续语义子程序的合法性判断。通常,程序员试图对一个常量符号进行“[]”、“.”或“^,’运算都是没有意义的。不过,根据文法来说,程序员却可以书写类似的表达式。然而,因为常量符号并不生成Var对象,所以编译器试图在语义子程序中发现与解决这些问题也并不容易。而bConstFlag标志就可以轻松实现这一功能,它的主要思想就是略过非终结符“变量”推导过程中执行的语义子程序,直到semantic053为止。
如果该标识符是变量名,根据先前讨论的原则,生成Var对象暂存变量的相关信息。第76~79行代码就是用于设置Tmp的各个属性。其中,调用了PushVarType函数将变量的类型信息压入了Tmp.m_VarTypeStack栈。第80行代码将Tmp压入CurrentVar栈。
第85~94行:这段代码主要用于处理输入标识符为过程名时的相关语义动作。与操作数翻译类似,过程调用的翻译同样需要栈结构的支持,因为编译器不得不考虑某一函数返回值出现在另一个过程(函数)调用语句的实参列表中的情况,例如,a(b(2))。因此,笔者设置了一个ProcCall结构及一个CurrentProcCall栈用于处理过程(函数)调用的语句的翻译。在操作数翻译中,主要涉及一些将过程相关信息保存到ProcCall对象中的语义处理动作。在此,笔者不打算详细解释各字段属性的含义与作用,读者只需大概了解该程序段的作用即可。过程(函数)调用的处理将在后续章节中详细讨论。
前面已经分析了semantic054的实现细节。下面看看semantic053的相关源代码实现。semantic053是操作数翻译的核心语义子程序,它的主要工作就是根据Var对象的相关信息,生成操作数寻址IR。
程序6-11 semantic.cpp

 (https://www.daowen.com)
(https://www.daowen.com)

第3~7行:根据bConstFlag标志,判断是否需要完成后续工作。semantic053是用于生成变量操作数的寻址IR的,对于常量符号是没有任何意义的,必须略过。semantic053是非终结符“变量”推导过程中的最后一个语义子程序,因此,在第5行中,将bConstFlag设回初始状态false。实际上,当输入标识符为常量符号名时,“变量”推导过程中的所有语义子程序都将被略过,直至执行完semantic053后。至此,读者应该能够理解bConstFlag标志的意义了。
第12~17行:根据bWithFlag标志,完成with结构的相关语义处理。
第18~25行:根据CurrentVar栈顶元素,即当前操作数的Var信息,生成OpInfo对象。实际上,也就是将变量的首地址打包成一个OpInfo对象。这里,值得注意的是指针变量的特殊语义处理。
第26、27行:判断当前操作数是否存在偏移信息。注意,根据当前操作数的Var信息,判断偏移信息是否有效。遵守如下两条判断标准:
(1)m_eOffsetType属性不为NoneOffset。这里,可能并不需要关心常量偏移或变量偏移,而只需界定是否存在偏移即可。
(2)m_VarTypeStack栈中是否包含记录类型或数组类型描述。只有数组元素或记录字段可能存在偏移信息,其他数据类型根本不需要关注该属性。因此,仅当用于跟踪类型变化的m_VarTypeStack栈中存在记录类型或数组类型描述信息时,操作数的偏移信息才可能是有效的。当然,这里并没有强调该类信息的详细位置,而只关注其存在与否。
第28~97行:根据当前操作数的偏移信息,生成操作数寻址IR,这是semantic053的核心代码段。简而言之,操作数寻址部分的IR主要由以下两部分组成:
(1)获取符号首地址的IR指令(GETADDR)。获取首地址IR指令的操作数是输入源程序的某个数组或记录对象,其结果是一个存储地址的临时指针变量。
(2)叠加偏移的IR指令(ADD_4)。无论是常量偏移还是变量偏移,只要存在偏移,就需要生成加法指令来计算首地址与偏移的和。
例如,house.address.road操作数相应的IR序列如下:

操作数翻译与表达式翻译的接口就是Operand栈,两者是通过Operand栈传递数据的。前者将得到的操作数压入Operand栈。而后者根据运算符的目数,从Operand栈弹出操作数,生成相应的IR,并将结果操作数再次压入Operand栈,以备后用。根据前面的分析,不难发现,将操作数压栈的动作将由semantic053完成。这里,值得注意的是无偏移量的操作数与有偏移量的操作数的处理是不尽相同的。以先前的“Tl”为例,根据IR的语义,临时变量Tl中存储的值是一个地址(house首地址+8)。按照无偏移量的操作数的处理方式,通常是将“Tl”直接压入Operand栈。实际上,这种做法是不正确的。
以i:=house.address.road-l为例,编译器可能得到如下IR序列:

非常明显,第3句IR的含义是将临时变量Tl的值减1后赋给i。不过,由于Tl中的值是一个地址,这个结果并不是用户所预期的。实际上,从输入源程序的语义来说,期望得到的是Tl所示地址指向的存储空间内的值,换句话说,就是需要对Tl进行一次间接寻址后再访问。因此,对于编译器而言,区分直接寻址访问或间接寻址访问是非常重要的。同一个操作数在不同IR中的访问方式也可能是不同的。在上例中,前两句IR中的Tl都是直接寻址访问,而最后一句IR中的Tl应该是间接寻址访问。在Neo Pascal中,笔者使用m_bRef来标识IR操作数的寻址访问方式,m_bRef为true表示该操作数为间接寻址访问,反之则表示该操作数为直接寻址访问。在生成IR序列时,设计者应该谨慎处理m_bRef标志,否则将导致程序异常。在本书的IR文本中,使用“@”符号表示间接寻址访问,例如:
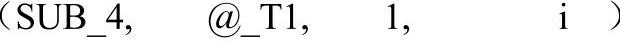
即表示将临时变量Tl的内容作为地址寻址得到的值减1后送入i。读者必须注意与标准Pascal的“@”运算符的区别。
这里,讨论了一种具有通用意义的操作数寻址方式,使用这种方式的前提就是对象的物理地址在编译阶段是不可知的,其物理地址是由操作系统分配的。不过,假设在某些特定的机器环境下,物理地址(首地址)在编译阶段是己知的,那么,也可以通过更简洁的IR序列实现同样的语义。事实上,这种假设并非无稽之谈,一些嵌入式系统并没有真正意义的操作系统,其程序空间的分配都是在编译阶段完成的。在这种情况下,物理地址的分配通常是由链接器完成的,而不是由编译器本身直接完成的。至少在语义处理阶段,物理地址仍然是未知的。因此,在类似的系统结构下,如何生成更为简洁的IR序列(略去取首地址的IR语句)是一个值得深入研究的问题。关于这个话题,笔者就不再深入阐述。了解了操作数寻址IR的处理流程后,阅读与理解相关源码并不复杂。下面,针对Neo Pascal的源代码,笔者谈三个实现细节:
(1)临时变量的取地址。通常,取地址运算(GETADDR)只可能在两种情形下出现:1、翻译含有“@”运算符的表达式。2、获取复杂类型变量的首地址。事实上,这两种情形都不可能出现对临时变量进行取地址运算。不过,有一种特殊的情形是值得注意的,那就是对复杂变量的某个元素取地址,例如,@a[1]、@(house.road)等。这里,以@(house.road)为例,按照先前讨论的翻译规程,编译器将产生如下IR序列:

注意,IR序列中“@_Tl”表示Tl是间接寻址操作数。从语义上来说,第3行IR的翻译并没有错,它的含义是将Tl值所指示的存储空间的地址赋给T2。不过,这种翻译方式是非常繁琐的。事实上,_Tl中存放的数据本身就是house.road的地址,根本不需要进行间接寻址后再取地址。理想的方案是将第3行IR替换成如下形式:
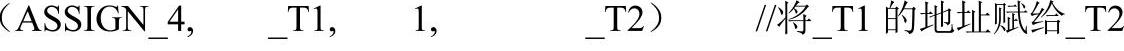
(2)变参的取地址。变参是一种比较特殊的传参方式。其本质就是将实参的地址传递给形参。不过,对于程序员而言,这是完全透明的。在引用形参时,并不需要对形参作“^,’运算,这个过程是由编译器处理的。因此,对形参取地址时,编译器只需直接将形参的值赋给目标对象即可,并不需要生成取地址相关的IR。
(3)叠加m_OffsetVec向量所存储的常量偏移。在此,笔者暂且不介绍m_OffsetVec向量的作用,读者只需了解m_OffsetVec中的常量同样作为偏移处理即可。关于m_OffsetVec向量,将在后续章节中详解。在本例中,第31~38行即用于处理m_OffsetVec向量。
第98行:将结果操作数压入Operand栈,供表达式翻译相关语义子程序使用。
第99行:至此,一个完整的操作数就分析完了,故将CurrentVar栈顶元素弹出。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





