Pascal语言所支持的表达式是比较有限的,从形式及功能上而言,Pascal表达式也是比较规范的,虽然不及C语言灵活,但也足以满足实际编程的需要。下面,就来看看Pascal表达式的文法:
【文法6-1】

在表达式文法中,没有将非终结符“变量”展开。因为“变量”涉及数组、结构等比较复杂的话题,所以将在下一节中详细分析。
笔者先来谈几个与表达式有关的话题。
(1)运算符的种类。一般而言,运算符的种类并非越多越好。运算符过多,必定会使语言的易学、易用性降低,对语言的推广是不利的。当然,运算符的种类也不能过少,那样会导致语言功能的不足。那么,设计多少个运算符为宜呢?这个问题并没有非常科学的定论,更多地依赖于语言设计者的经验。
(2)运算符的优先级。高级语言的运算符通常都是有优先级差异的。在设置运算符优先级时,语言设计者主要考虑两个方面的因素:
1)运算习惯。这是最重要的因素,例如,加、减运算符的优先级通常是低于乘、除法运算符的。这是一个数学常识,不应该颠覆。
2)运算优先级别不应过多。在实际编程中,有经验的程序员很少依赖语言本身的运算优先级,为了安全起见,他们更愿意使用括号。尤其当优先级过于复杂时,大多数程序员可能更不信赖优先级了。而且优先级别过多会给初学者带来不便。虽然C语言如此经典,但是,在优先级设置方面,它却不是一个经典范例。相对而言,Pascal的优先级别的数量比较合适,但是Pascal同样不是一个成功的例子。根据标准Pascal的规定,Pascal的关系运算符优化级低于逻辑运算符,这是一个非常奇怪的规定,与人们一贯的逻辑思维方式是不符的。例如,书写i>10 and i<100的本意就是判断i的值是否界于(10,100)之间。不过,根据标准Pascal的规定,由于and优先级高于关系运算符,所以10 and i被优先计算,这就使程序员不得不使用括号来改写这个表达式。
在第5章中,笔者已经提到了表达式翻译的基本思想。利用栈结构分析与翻译表达式的方式是比较常见的,由于栈结构分析表达式算法是数据结构课程的相关内容,这里,只作简单介绍,不作深入讨论。
实际上,就表达式计算算法而言,编译技术中讨论的算法要比数据结构课程简单一些。当然,只是因为有些琐事是由词法分析器、语法分析器完成的,并不需要语义子程序关心。下面,就通过一个完整的实例来看看表达式计算的过程。
例6-2 计算表达式3+5 x2-4的值。
根据Neo Pascal文法,可以将表达式的推导过程抽象为语法分析树,如图6-7所示。在语法分析树中,笔者特意用虚线框标识语义子程序,以便与终结符区别。事实上,通常意义的语法分析树只是用于描述语法的推导过程,并不需要标注语义子程序。
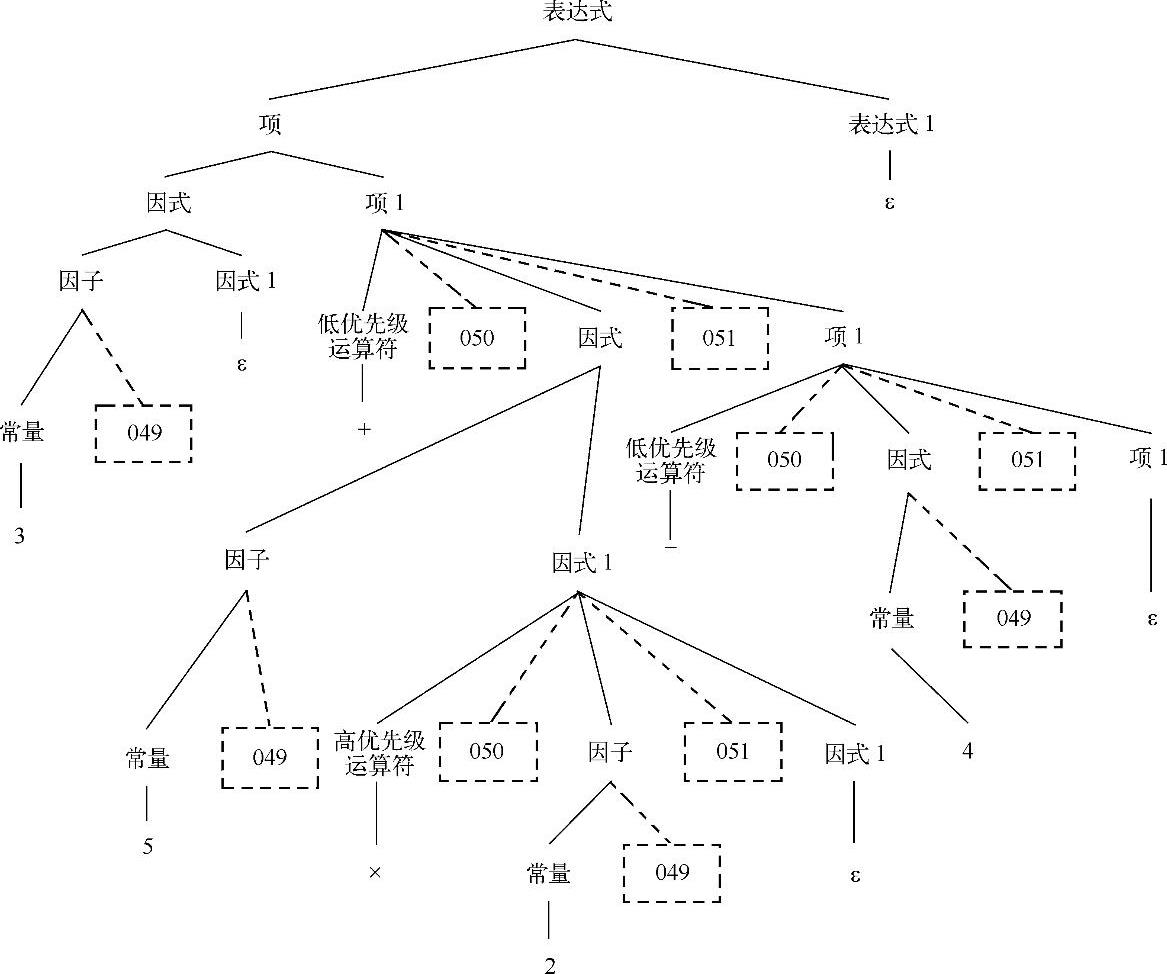
图6-7 表达式3+5×2-4的语法分析树
不难发现,在语法分析树中只出现了三个语义子程序(049、050、051),现在问题的关键就是赋予这三个子程序一定的语义动作,使之达到预定的目标。那么,暂且定义这三个子程序的语义动作如下:
049:将当前单词压入操作数栈。
050:将当前单词压入运算符栈。(https://www.daowen.com)
051:从操作数栈弹出两个操作数,从运算符栈弹出一个运算符,进行相应的计算,并将计算结果压入操作数栈。这里,值得注意的是先出栈的元素是第二操作数,而后出栈的元素是第一操作数。在处理一些不符合交换律的运算时,必须加倍注意。
下面,就来看看表达式处理的过程。
对语法分析树进行后序遍历,忽略非终结符与“e”后,可以得到如下的序列:

根据先前定义的语义动作完成相应的操作,最终,操作数栈的栈顶元素即为表达式的结果。
如果分析过程完全正确且不考虑表达式组等情况,操作数栈内有且仅有一个元素,而运算符栈应该为空。笔者就不再模拟详细的入、出栈操作了,这应该是非常简单的。
读者可能会有疑问,包括Neo Pascal在内的许多编译器并不显式生成语法分析树,那么,又如何进行后序遍历呢?实际上,是否显式生成语法分析树并不影响语义动作的执行。前面曾经提到,自上而下语法分析的过程本身就是一次后序遍历,因此,并不会影响语义子程序的调用顺序。
上述常量表达式的计算实例,旨在说明编译器是如何计算表达式的。下面,将通过一个更一般化的例子,来谈谈变量表达式的处理。当然,含有变量的表达式是不可能由编译器在编译过程中计算得到结果的,那么,计算表达式的问题就变成了如何将表达式翻译成IR的问题了。实际上,这是非常简单的,只需对051的语义动作稍作修改即可,具体修改如下所示:
051:从操作数栈弹出两个操作数,从运算符栈弹出一个运算符,申请一个临时变量用于存储计算结果。生成形如(Op,Opl,Op2,T)的IR,并将临时变量压入操作数栈。
以表达式i+j×k-6为例。这个表达式对应的语法分析树与图6-7是非常类似的,笔者就不再重绘了。后序遍历语法分析树后,可以得到如下的序列:
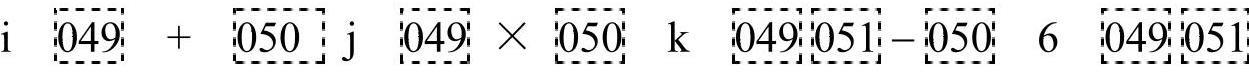
根据先前讨论的语义动作,可以得到如下的IR序列:
(MUL j , k , Tl)
(ADD i , Tl , T2)
(SUB T2 , 6 , T3)
这里的IR形式并不是NPIR,只是一种逻辑表示形式而己。Tl、T2、T3是编译器临时变量,在表达式翻译过程中,每次运算的结果都必须用临时变量保存。有些读者可能会问:这样处理是否会产生大量的临时变量呢?确实如此,不过,在优化阶段及存储分配阶段,编译器会进行相关分析与优化,因此,并不会影响目标程序的效率。
至此,笔者已经详细解释了手工实现表达式的翻译的过程,并获得了一个相对完整的IR序列。这个过程就是实际表达式翻译的抽象模型,值得推敲。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





