前面,笔者已经讲解了一些与生成IR有关的理论知识,这些理论知识是分析IR生成模块的基础。在本小节中,笔者将着眼于分析编译器的翻译机制,看看编译器是如何将输入源程序翻译成IR的。对大多数程序设计语言而言,编译器的翻译主要涉及两个领域:语句翻译、表达式翻译。结构化语句与表达式是高级语言最重要的两个组成元素,同时也是区别于低级语言(汇编语言)的主要标志。
程序设计语言的语句是一个非常精致的体系结构,它们的组合可以诠释任何复杂的逻辑。一门程序设计语言的语句少则数种,多则十几种,就是这样一个体系规模却创造出了一个干变万化的奇妙世界。在笔者看来,“精致”一词仍不足以描绘其本质。读者熟悉的这个语句结构模型非常经典,无论是结构化语言还是面向对象语言都没有颠覆其主导地位。
习惯上,将语句结构分为三类:顺序结构、选择结构、循环结构,这恐怕是每位程序员早己烂熟于心的。本章将从编译器设计的角度,让读者理解各种语句结构的内核实现。Neo Pascal一共提供了12种语句结构,分别是赋值语句、过程函数调用语句、goto、continue、复合语句、while、repeat、if、for、case、asm、with。Neo Pascal的语句结构是完全参考标准Pascal实现的,并在标准Pascal的基础上加入了asm语句。
笔者先给出Neo Pascal语句相关的文法,以便后续章节中针对各类语句结构进行详细的分析。
【文法5-1】
语句序列 → 语句行语句序列ε
语句行 → 语句:
语句 → 标识符061标识符起始语句1其他语句Iε
标识符起始语句 → 变量1 053:=表达式064 1 :062语句l过程调用语句
过程调用语句 → (101实参列表)066 Iε005
其他语句 → goto标识符063
→ break 081
→ continue 082
→ begin语句序列end
→ while 071表达式073 do语句072
→ repeat 074语句序列until表达式075
→ for标识符076:=表达式077 for语句后部
→ if表达式068 then语句if语句后部070
→ case表达式084 0f case分支end 089
→ asm字符串常量,字符串常量083 end
→ with 090变量053 091 do语句092
for语句后部 → to表达式078 do语句079l downto表达式080 do语句079
if语句后部 → else 069语句| ε
case分支 → 常量列表087:语句088;case分支|ε
从Neo Pascal的文法来看,笔者将Neo Pascal的语句结构分为两类:标识符起始语句、其他语句(也就是关键字起始语句)。其中,标识符起始语句只有三种,即赋值语句、过程调用语句以及标号语句,而其余的语句都属于后者。这里,读者应该注意一个细节,在Pascal语言中,复合语句(BEGIN...END结构)处理与其他普通语句是一样的,所以复合语句结束处仍需要标注分号。
下面,先来谈谈Neo Pascal语句翻译的总体实现。根据IR的设计目标,高级语言的任何语句结构都将转换成等价的IR形式,而这种转换工作完全是由若干个语义子程序协调完成的。然而,NPIR是一种MIR,仅提供了一些跳转操作符,所以编译器不得不将Neo Pascal的各种语句结构转换成由跳转、标号等组成的IR序列。虽然各种编译器设计IR形式不尽相同,但是,使用跳转、标号组合实现源语言的语句结构却是得到共识的。(www.daowen.com)
语句的各种嵌套组合是不可预知的,设计者通常是无法穷尽各种存在可能性的,转换工作的复杂性可能是难以想象的。那么,面对这个复杂的问题,通常的解决方案就是分而治之。初期,并不需要过多考虑嵌套组合等复杂情况,只需实现基于各种基本语句的等价翻译即可。待解决了最基本语句的翻译后,再逐步考虑各种复杂情况的存在。实际上,基本语句的翻译是非常简单的,这里。笔者通过一个if语句的实例来看看编译器是如何翻译基本语句的。
例5-4 if语句的IR实例,见表5-5。
表5-5 if语句的IR实例
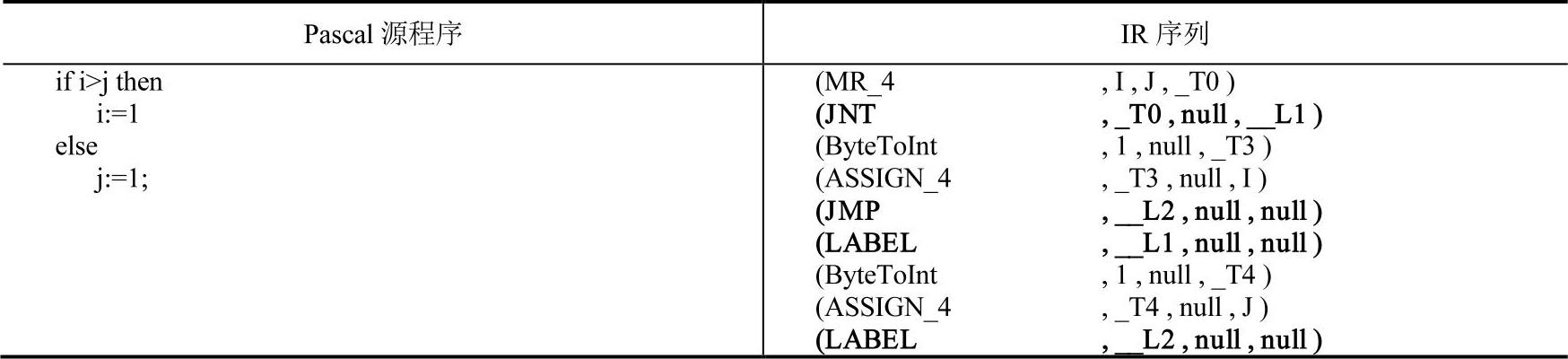
这是一个if语句的IR实例,读者可以先忽略IR序列中的非粗体代码。除了临时变量名、标号名可能存在一定的变化之外,粗体所示的IR结构正是if语句的标准翻译方案。如果省略了else子句,则只需忽略翻译方案(黑体所示的IR序列)中的2、4两行IR即可。就本例而言,读者可能觉得从源程序到IR的转换过程似乎并没有想象中的复杂。实际上,确实如此,当问题规模很小的时候,一些原本表面上比较复杂的问题可能就会变得简单,将语句翻译的问题细化到各个语句结构时,就可以指导编译器很机械地完成等价转换的工作。从上例不难发现,if语句翻译方案是非常简单的,只要稍有汇编语言基础的读者都可以轻松理解。类似地,设计各种基本语句结构的翻译方案并不是非常困难的,详细的翻译方案将在后续章节中逐一描述。
解决了基本语句的翻译之后,就得考虑各种语句之间的嵌套情况。根据程序设计语言的语法、语义规定,语句的嵌套并不是任意为之的,它必须满足一定的层次条件。抽象语法树的观点认为任何复杂的语句嵌套情况都可以借助于树的形式加以描述。确实,不得不承认应用抽象语法树可以使语句翻译变得相对容易,它很好地描述了语句、表达式之间的联系。不过,由于Neo Pascal并不会显式构造抽象语法树,所以不得不借助于其他数据结构实现。根据先前的经验,栈结构就是不二之选。那么,就来详细看看Neo Pascal又是如何实现这个栈结构的呢?在Neo Pascal中,称其为“当前语句栈”,声明如下:
【声明s-3】
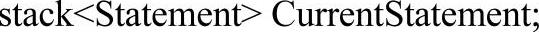
CurrentStatement:栈顶元素描述的就是当前(控制)语句的相关信息。与符号表不同的是CurrentStatement只是一个暂存结构,而符号表却是一套贯穿于整个编译过程的数据结构。由于各种语言结构的不同,编译器需要得到的信息也不尽相同。同样,也不可能要求Statement结构应对各种应用需要,但是仅针对Pascal语言来说,Statement结构所描述的信息已经足以完成编译工作了。读者必须注意,Statement结构的功用并不是承载语句语义,而是存储一些与编译相关的信息或者属性。
【声明5-4】

m_eType:用于描述该语句结构的类型。注意,这里并不需要考虑那些不允许嵌套的语句,如break、goto等。虽然它们也可能产生跳转,但是却不可能出现因嵌套导致的复杂标号联系。根据Neo Pascal语言的特点,这里只需设置五个枚举值即可。
m_Labels:这是一个标号列表,用于存储与当前语句相关的所有标号信息。关于Labelldx结构的解释,笔者将稍后给出。
m_iLoopVar:如果当前语句是for语句时,则m_iLoopVar就是指向循环变量的指针。在Pascal语言中,循环变量对于for语句是尤为重要的,循环变量的增、减或者比较运算并没有显式的表达式,而是隐含于语句结构的语义中,这就需要编译器加以识别处理。然而,在C语言中,循环变量的作用就完全被for语句的三个表达式替代了,而这三个表达式是由用户设计编写的,因此,只需将表达式翻译成目标代码即可。当然,m_iLoopVar属性在case语句中还有一个特殊的作用,待后续章节中详述。
m_bIsDownto:这是一个标志属性。前面,读者应该已经了解了Pascal的for语句与C语言for语句的区别,标准Pascal的for语句规定每次循环完毕循环变量自增或自减1。而编译器则是通过for语句中的to或downto关键字加以区分。注意,在标准Pascal中,并没有循环步长的概念,唯一的步长就是1。而m_bIsDownto属性就是用于标识当前for语句是否为自减模式。
m_bIsElse:用于标识当前if语句是否存在else子句。
m_CaseExp:用于存储一个实际的操作数(case表达式)。由于case表达式对于翻译case语句是非常重要的,所以有必要加以记录。
下面解释一下LabelIdx结构及其各属性的作用。
LabelIdx:这是一个内嵌结构类型声明。根据前面的讲述,标号信息是语句翻译过程中极为重要的元素,例如,语句结构的入口标号、出口标号等。实际上,控制语句翻译的关键就是正确生成与管理各种标号。下面,笔者详细分析其中各属性的含义。
m_labelType:这个属性的作用是标识该标号的类型。根据常见的高级语言控制结构的特点,一般可以将标号分为如下五种类型:TrueLabel(真分支标号)、FalseLabel(假分支标号)、ExitLabel(出口标号)、EntryLabel(入口标号)、CaseLabel(Case标号)。其中,真、假分支标号主要是指标识if语句真、假分支的标号。而出、入口标号主要是指标识循环结构出、入口的标号,当然出口标号也常见于其他控制结构中。严格区别五种标号类型的主要目的是为了提高程序的可读性。
m_Label:这个属性用于存储一个实际标号操作数。
m_iIdx:指向该标号的指针。
m_iConst:这个属性仅当所属Statement实例的m_eType的值是CASE(即表示当前语句是case语句)时才有效。在Pascal语言中规定一个case分支只能关联一个常量值,而不是一个常量列表。通常,在翻译case语句时,会为每一个case分支分配一个标号,而m_iConst就是用于标识当前标号所关联的常量值在常量信息表中的位序号。
总体上来说,Pascal的语句结构是比较精简的,但也是比较经典的结构化语言模型,因此,Pascal语句翻译机制的设计对于其他语言编译器设计是具有一定指导意义的。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





