前面已经提到了三地址代码的概念。在众多IR中,三地址代码是最为常用的。由于Neo Pascal的IR也是一种三地址代码的形式,因此有必要详细讨论这种IR。所谓的“三地址”指的就是两个运算分量(操作数1、操作数2)及目标操作数三个对象的地址。例如,(ADD 5,A,B)的含义是5+A—B,其中“ADD”称为操作码,而5和A是两个运算分量,B是目标操作数。注意,三地址代码的书面表示形式并不唯一,本书将使用“四元组”的形式表示三地址代码。
计算机科学家提出三地址代码的理由如下:三地址代码是一种线性IR。由于输入源程序及输出目标程序都是线性的,因此,线性IR有着其他形式无法比拟的优势。另外,相对于其他表示形式而言,程序员对于线性表示形式通常会有一种莫名的亲切感,编译器设计者当然也不例外。早期编译器设计者往往都是汇编语言程序设计的高手,可以非常自然、流畅地阅读线性的三地址代码形式。同时,线性表示形式也会降低输入输出的实现难度。随着编译器“端”、“遍”等概念的出现,IR已经不仅仅是一种存储在内存中的数据结构。有时它也需要以文件形式转存输出,作为接口供其他系统读取使用。
那么,一定有读者会心存疑问:为什么将其设计为“三地址”的形式呢?实际上,这是计算机科学家经过多年实践探索后才得到共识的。三地址代码并不是唯一的线性IR,只能说是最为常见的而己。在编译技术领域,二地址代码、单地址代码(即栈式机代码)都曾出现过,也曾在某些应用领域盛行一时,尤其是单地址代码。
二地址代码比较简单,就是选择其中一个对象同时充当运算分量与目标操作数。在早期,二地址代码主要就是着眼于x86机器而提出的。不过,实践证明,这只是人们的一厢情愿而已,即使是针对x86机器,二地址的优势也并不明显,它反而可能会给编译器带来一定的麻烦,所以这种表示形式已经逐步被淘汰了。
然而,单地址代码的情况则截然不同了,在现代编译器设计中,单地址代码也是应用比较广泛的一种IR。尤其是近年随着混合语言的日渐壮大,单地址代码也重新进入了人们的视野。由于执行单地址代码程序的栈式机架构相对比较简单,可以非常方便地构造相关的解释器或虚拟机,所以单地址代码深受混合语言设计者的欢迎。读者熟悉的Java字节码、.NET的IL都是单地址代码。栈式机或者单地址代码与常见的x86体系结构相差甚远,可能读者所知不多。不过,单地址代码还是一种比较有意思的表示形式,因此,笔者想通过一个简单的实例让读者对单地址代码有所了解。
例5-1 单地址代码实例。
表5-1是一个.NET IL汇编的实例,左侧是C#的源程序片段,右侧是IL汇编的片段(使用ildasm.exe将可执行文件反汇编即得到该结果)。当然,注释是笔者事后加上的。
表5-1 IL汇编实例
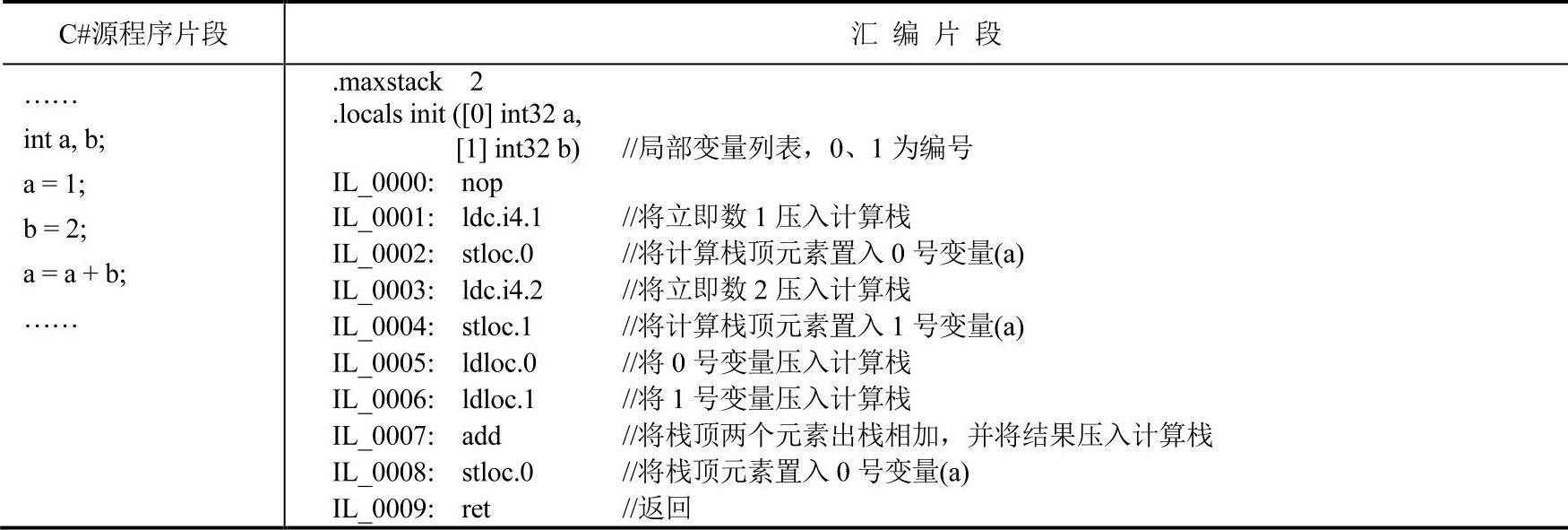
某些读者可能对IL汇编语言比较陌生。相信无论熟悉与否,借助笔者的详细注释,要读懂这段简单的IL汇编程序并不困难。设置这个实例的目的只是让读者了解一下栈式机及单地址代码的形式。这里,笔者必须澄清一点:实际上,IL汇编语言并不简单,读者千万不要被本例误导。当然,对有志于深入研究.NET编译器的读者而言,学习IL汇编语言还是非常有必要的,它是深入研究.NET编译器的基础。
三地址代码是在二地址代码的基础上发展而来的。二地址代码的不足之处在于它通常会给其中一个源操作分量带来一定副作用。当然,这种设计的灵感最初是来源于x86指令系统的,但是却忘了一个重要的区别:x86指令中往往都是以寄存器作为暂存空间的。而暂存空间对于二地址代码却是一个棘手的问题。为了解决二地址代码的不足,人们提出了一个对源操作分量不产生任何副作用的形式,那就是三地址代码。也就是说,在一行三地址代码中,任何运算都不会改变两个源操作分量。这是三地址代码与二地址代码的主要区别。这个特性是非常重要的,它将使得编译器更自由地复用名字与值,不必考虑代码带来的副作用。
一般来说,三地址代码的大多数操作都是由四项组成,即一个操作码和三个地址。不过,三地址代码同样存在级别差异。随着语言复杂性的提高,在现代编译器设计中,三地址代码的级别概念显得尤其重要。根据编译器设计的需要,有些三地址代码可能近似于源语言,而有些三地址代码则更接近于目标语言。当然,级别主要就是取决于三地址代码的操作符及操作分量的复杂性。下面,笔者就操作符及操作分量这两个话题来讨论三地址代码。
操作符是用于标识三地址代码操作含义的元素。根据源语言、目标语言的特点,三地址代码操作符的集合以及抽象程度是各不相同的。其中,抽象程度是三地址代码设计中的重要因素之一。一般而言,三地址代码将包含大部分低级操作,即目标机所支持的指令。不过,这并不意味着三地址代码就是机器指令系统的映射。设计者应该从便于后端处理的角度考虑,尽可能地发挥三地址代码作为中间语言的作用。
在Pascal语言中,集合变量的赋值或者传参实际上就是存储区的复制操作,这与指针、数组等是完全不同的。一个集合变量所需的存储空间是32B(256位),集合变量的赋值就是一次32B的存储区拷贝。对于大多数机器而言,通常都不提供类似的指令。那么,针对这种情况,应该如何设计三地址代码呢?可能有两种方案可选。第一,只生成一条三地址代码,设置一个独立的操作符(例如,MOV_SET),其含义就是将源地址起始的32个字节连续存储区中的数据复制到目标地址起始的存储区中。这种方案更多是从源语言的角度考虑,尽可能在IR中体现源语言的语义。至于如何由该三地址代码生成相应的目标代码是由目标代码生成器完成的,目标代码生成器可以使用一段目标语言的指令序列来替换这一条三地址代码,从而实现等价转换。第二,从目标语言的角度考虑,按目标机的字长生成若干条标准字长的赋值代码,例如,以32位目标机为例,就需要生成8条三地址代码。这种方案使得目标代码生成比较简单,编译器只需用一两条指令替换一条三地址代码即可。不过,就三地址代码本身而言,它更多地只是承载了目标机的特性,却很难明确地表达源语言的语义。对于单一IR的编译器而言,笔者并不提倡使用第二种方案。然而,对于存在多种IR的编译器而言,可根据不同的需要选用,两种方案是各具特色的。
读者可能会有疑问,第一种方案的优势又是什么呢?实际上,其优势就是便于后端的优化处理。这里,暂且不详细讨论优化,笔者只是通过一个简单的实例来阐明三地址代码与优化技术的联系。
例5-2 三地址代码与优化技术。(www.daowen.com)
三地址代码与优化技术如图5-2所示。

图5-2 三地址代码与优化技术示意
a)源程序 b)方案1的三地址代码 c)优化后的三地址代码 d)方案2的三地址代码
本例的三地址代码只是一种逻辑形式而已,并不是由Neo Pascal实际生成的。为了突出重点,笔者简化了一些细枝末节的元素。
本例是一个Pascal集合变量相关的源程序,其中a、b、c都是集合类型的变量。程序运行结果:a的值为[2],b的值为[3],c的值为[2,3]。注意,在Pascal语言中,当运算分量为集合类型变量时,加法运算的语义即为集合的并运算。先来比较一下(b)、(c)两段三地址代码的差异,不难发现,(b)代码段是完全按照c:=a+b的语义生成的,而(c)代码段是直接将集合加计算的结果[2,3]赋给c的。这里,暂且不论实际生成的目标代码形式如何,仅从这个简单的变换而言,相信不难得到如下结论:省去了集合加运算,程序的执行效率是有所提高的。如果考虑实际编译器生成(b)代码段时,还可能产生临时变量的情况,那么优化的效果就更为明显了。当然,不得不承认编译过程必须为优化付出一定的时间代价。不过,实践证明,大多数用户愿意用编译时间来换取运行效率的提高。显然,(b)代码段的语义非常明确,对于优化算法来说,它可以非常方便地获得这三条三地址代码所承载的语义,这对优化是非常有利的。
再来看看(d)代码段,它是根据方案2生成的三地址代码列表。注意,Pascal语言规定类型的基类型元素的总和必须小于256个,这是由集合类型的物理结构决定的。一个集合变量占用256位(32B)存储空间,每一位表示一个元素的状态,置位表示元素存在于集合中,否则表示元素不存在于集合中。若基类型为BYTE(允许最小元素为0),那么,集合[2,3]可表示为(1100)b,即第2、3位置1,其余位置0。因此,在(d)代码段中,集合[2]的十进制表示就是4,而集合[3]的十进制表示就是8。从(d)代码段中,似乎已经很难看到源程序的实际语义了,更多的只是考虑目标机的物理结构及目标语言的语义。在这种情况下,优化算法要想实现(d)→(c)的转换也就变得非常困难。当然,这并不意味着这种转换是不可能实现的,只是代价较大而己。
通过例5-2的讲述,读者应该已经了解了三地址代码操作符抽象性的意义所在。当然,本例提到的优化只是冰山一角而已,不同的优化算法对于三地址代码的需求也是不尽相同的,这里就不再展开了。
下面,笔者再从操作分量的角度来讨论三地址代码。操作分量是三地址代码的另一个组成元素。讨论操作分量的目的就是明确一个操作分量需要承载哪些信息。
汇编语言指令的操作分量是非常简单的,在大多数情况下,汇编语言中只需描述操作分量的地址及操作分量的宽度(即占用空间大小)即可。例如:
mov eax,dword ptr [aa]
该指令的左操作分量是一个寄存器,寄存器的地址及宽度是机器的固有属性,所以不必显式说明。而指令的右操作分量是一个内存空间,地址即为标号aa所指出的地址,dword ptr表示其宽度为4B。在汇编语言中,操作分量的相关属性并不多,这可能是仅有的几个属性。通常,汇编器并不关心该存储空间中的数据到底是什么类型,也就是说,aa所标识内存空间中数据的类型可能只有程序员本人可以解释。当然,笔者仅针对那些经典汇编语言及汇编器进行讨论,而HLA之类的高级汇编语言暂不做考虑。
同样,三地址代码作为一种中间语言,也有必要说明其操作分量的相关属性,这是决定三地址代码级别的关键因素。实际上,从操作分量上来说,不难发现,高级语言与汇编语言最主要的差异就在于类型。高级语言的操作分量通常都是有类型的,而汇编语言则不具备这一特点。然而,类型又是一个非常复杂的元素。在很多情况下,三地址代码的级别就是取决于其是否支持以及如何支持类型。这个问题并不好回答,人们也很难评价这两种三地址代码孰优孰劣。不过,它却影响着后续工作的进行。在国内编译原理书籍中,很少提及关于三地址代码操作分量的类型描述等话题。读者可能会有一个错觉:三地址代码就是一种近似于汇编语言的IR。这是一种比较常见的情况,但并不是绝对的。作为一种模型,完全可以避开类型描述之类的繁复细节,只需要关心操作分量的名字等主要属性即可。不过,就实际编译器设计而言,这恐怕是无法回避的。本书提及这一话题的目的就是希望读者对此给予足够关注。
最后,笔者简单谈谈三地址代码的物理存储结构。三地址代码是一种线性表示形式,所以有许多经典的线性表结构可以参考。关于线性表的结构,这里就不再深入讨论。不过,有个概念是需要说明的,根据一些经典编译器的设计经验,三地址代码的物理结构并非自始至终一成不变的。在多遍编译器中,使用不同物理存储结构来实现不同阶段的三地址代码是有意义的。例如,在前端,主要就是致力于生成三地址代码,顺序结构可能较优。而在后端,可能会涉及一些三地址代码的修改、调度,链式结构就优势明显了。当然,根据应用的需要,创新设计一些更适合本系统的物理结构是完全可以接受的。
至此,笔者已经详细讨论了三地址代码的相关理论话题,从实践设计角度,阐明了某些现代编译技术的观点。囿于篇幅,笔者省略了其中的某些常识性的概念,有需要的读者可以参见相关书籍。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






