中间表示,通常称为IR(Intermediate Representation,简称IR),是编译器设计中的另一个重要话题,它是编译器前端的产物。在编译技术发展历程中,IR的提出具有里程碑的意义,它是划分编译器前、后端的一个重要标准。IR的应用使得编译器可以方便地适应源语言、目标语言的变化与扩展。在理想状态下,与源语言相关的变化只需改变编译器的前端,而与目标语言或目标机相关的变化只需修改编译器的后端即可。图5-1是两种经典编译器的模型示意图。
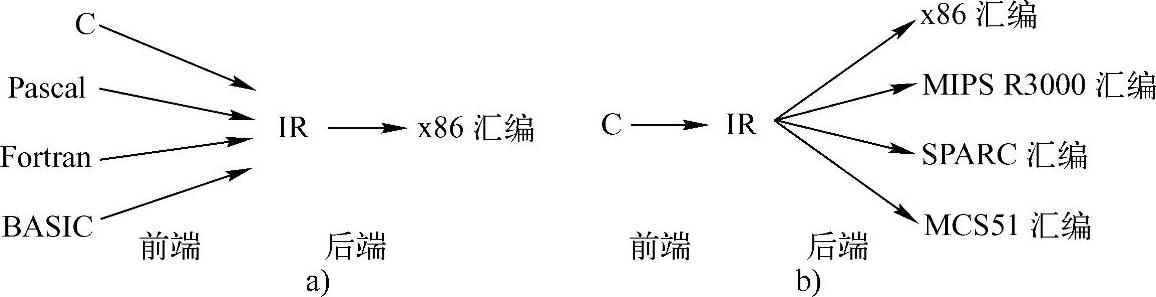
图5-1 编译器前、后端模型示意图
a)模型A b)模型B
模型A允许输入多种不同源语言编写的程序,将其翻译成同一目标代码。为了便于源语言的扩展,通常前端将其编译生成一种具有一定通用意义的IR。而后端(例如,优化、目标代码生成等)并不需要理会编译器到底存在几种不同的源语言,对于后端而言,唯一的源语言就是IR。VS.NET就是基于这种模型的编译器,只不过它的后端是.NET Framework的动态编译框架,而前、后端的接口就是IL。(www.daowen.com)
模型B描述的是一种常见的编译器,称为“可变目标编译器”,即编译器的后端可以生成不同的目标代码。使用这种编译器的源语言编写程序的优点在于可以方便地将同一个程序移植到各种目标机上运行,用户不必过多关注各种目标机体系结构的细节。不过,需要指出的是,可变目标编译器并不是读者所熟悉的跨平台编译器。可变目标编译器关注的是目标机的变化,而不仅仅是操作平台的变化。当然,在现代编译领域,这种模型也用于解决目标程序跨平台的I司题。
在实际应用中,还存在一种更为特殊的模型,它可能存在多种源语言与目标语言。这类编译器的IR可能更像是一种标准接口,分别提供给前、后端使用。事实上,能够完美实现这一目标的经典编译器并不多见,可能唯有GCC才当之无愧,GCC支持C、C++、Java、Fortran、Pascal等多种源语言及i386、MIPS、ARM等数十种目标机。
最后,笔者有必要指出,在很多情况下,编译器前、后端之间并不存在非常明确的界线。尤其是源语言的专业性比较强时,前、后端的界线可能是非常模糊的。因为,在这种情况下,编译器设计者没有必要过多考虑源语言、目标语言的横向扩展,当然,也没有必要为此付出巨大的精力。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






