本小节主要讨论设计者以何种形式来组织符号信息。符号表的设计很大程度上是一门艺术而不是科学。有时,面对几种设计方案,很难判定孰优孰劣。与数据库逻辑设计类似,在实施验证之前,仅仅凭借理论分析评价一个数据库模型可能并不是非常科学的。当然,笔者并不否认理论分析的重要性,但是太多实践经验让人们不得不承认这个观点。
总体而言,符号表的逻辑组织形式主要有两种:单表、多表。
所谓单表形式,就是指把所有的符号都组织在一张符号表中。这种组织方式的优点是管理集中。而其缺点是由于不同符号的属性字段并不相同,使用符号表的表项长度会因为符号的不同而不同,这是数据库设计者通常无法接受的。这种组织形式多见于一些早期编译器。
与单表形式相比,多表组织形式相对优越一些。
所谓多表形式,就是指把类型相似的符号(即属性字段基本相同)组织在一张符号表中,在整个编译过程中,编译器可能需要维护若干张类型不同的符号表。这种形式使得类型差别明显的符号分散在不同的符号表中。例如,可以将变量符号集中在一张变量表中,编译器在检索变量符号时,只需按变量名和作用域在变量表中检索即可,无需额外判定符号类型。从数据库设计观点而言,这种方式更符合数据库设计的思想。虽然未必所有的符号表都能符合3NF要求,但它的确有利于降低管理复杂度。现代编译器设计观点更倾向于这种组织形式,当然,关于符号相似程度并没有统一的标准,完全是凭借设计者经验、具体语言与目标系统而定的。
下面详细谈谈Neo Pascal符号表的逻辑结构。Neo Pascal的符号表采用多表组织形式,根据Pascal语言的特点,Neo Pascal设置了六张符号表:过程信息表、变量信息表、常量信息表、枚举类型信息表、类型信息表、标号信息表。笔者提出的这种分类方法未必是最佳的设计,只能说是一种可行的设计方案而己。另外,需要说明一点,为了照顾一些初学者的需要,笔者选择了STL的map模板类作为符号表的主要描述形式,而避免使用链表之类的复杂结构。map模板类的内核实现是红黑树,它是一种极其高效的平衡树结构,在一些特殊场合下,其性能可以接近或超过hash_map(即散列表)。因此,本书符号表中涉及的指针都是以类似于下标形式的关键字描述的,不过,为了便于讲解,本书仍然将沿用“指针”这一名称。
1.变量信息表
变量信息表主要用于存储变量符号的相关信息。这里讨论的变量一般包括两类:用户声明的变量、编译器产生的临时变量。与用户声明的变量类似,临时变量也具有类型、所属过程等信息,但是在编译过程中由编译器自动产生的,对于用户是完全透明的。根据Pascal语言的特点,Neo Pascal变量信息表表项的结构如下:
【声明4-1】
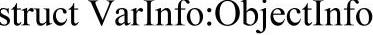

m_szName:变量名。对于临时变量而言,Neo Pascal采用统一的命令规则,即为“T×××”。其中,“×××”表示一个任意长度的正整数值,这个值由编译器顺序编码,以此保证都不存在重名现象。而变量名以下画线开头,则保证了临时变量不可能与用户定义的变量名冲突,因为Pascal语言规则变量名必须以字母开头。如果是C语言,则必须用其他字符开头来命名临时变量,以区别C语言中下画线开头的变量。注意,m_szName属性是继承自Obj ectInfo的。
m_iProcIndex:变量所属过程的指针。根据Pascal语言的语义,变量必须隶属于某一个过程,即使是全局变量也是隶属于主程序的,这与C语言是不同的。注意,miProcIndex属性是继承自ObjectInfo的。
m_iTypeLink:变量的类型描述指针。在分析变量声明时,必须在符号表中将变量类型完整地进行描述,这是后续语义分析及代码翻译的决策依据。由于类型描述比较复杂,类型符号与变量符号的属性信息也差异较大,因此,笔者将类型描述信息构造成一张独立的符号表,即类型信息表。而m_iTypeLink就是指向该表类型描述信息的指针。
m_eRank:变量的类别,取值范围为(VAR,PARA,RET),分别表示普通变量、形参、返回值。严格地说,过程、函数的形参和返回值都不是用户声明的变量,但与用户声明的变量非常类似。对于编译器而言,同样需要对它们作语义检查、类型分析,也要分配相应的存储空间。当然,与普通用户定义的变量相比,形参、返回值毕竟又具有一定的特殊性。例如,Pascal语言规定返回值只能作为右值。因此,符号表必须对形参、返回值加以标识。
m_bRef:用于标识该变量的寻址方式是直接寻址还是间接寻址。
m_MemoryAlloc:这个属性将在存储分配中使用,主要用于标识变量的逻辑存储地址。语义分析阶段并不需要关注这个属性。
m_bUsed:标识变量是否被使用。在整个程序范围内,如果该变量没有被使用,则不必分配存储空间。
注意,VarInfo结构是继承自Obj ectInfo结构的。这是由于m_szName与m_iProcIndex是大多数符号共有的属性,因此,笔者将其抽象到ObjectInfo结构中,而其他各类具体符号的表项结构都是ObjectInfo的派生结构。
2.常量信息表
常量信息表主要用于存储常量符号的相关信息。常量信息表中的常量不一定局限于词法分析器所识别获得的常量,可能还会包括编译过程中产生的一些常量值。例如,编译器在分析表达式a=3+5时,为了提高目标程序的运行效率,通常会自动计算3+5的值,将计算结果8直接赋给变量a,而不需要生成具体的计算指令。这时,编译器必须将常量8记录在常量信息表中,以便后续处理。从程序设计语言的角度来说,常量与变量是完全不同的,因为常量在目标程序中是不予分配存储空间的,而变量必须占用一定存储空间。即便如此,对于编译器而言,常量信息仍然是非常重要的,它是代码生成的依据。因此,设置常量信息表是有现实意义的。常量信息表表项的声明形式如下所示:
【声明4-2】

m_ConstType:常量的基本类型。与变量类似,常量也具有类型信息,例如,字符串型常量、整型常量等。在词法分析阶段,编译器能够识别常量符号,并将其登记到符号表中,但是编译器无法也没必要精确断言常量的实际类型,因为这项工作通常是由类型系统完成的。m_ConstType的取值为{STRING,REAL,INTEGER,EREAL,BOOLEAN,ENUM,SET,PTR},即字符串型、实型、整型、科学记数法的实型、布尔型(True、False)、枚举型、集合型、指针型(NIL)。当然,这里讨论的常量可能并不等同于C语言中由const修饰符指示的常量。在大多数编译器中,复杂类型的常量信息一般并不记录在常量信息表中,例如,记录类型常量、数组常量等。
m_StoreType:常量的实际类型。在编译过程中,根据常量的取值,编译器将自动计算确定常量的实际类型。例如,在分析常量123.12时,词法分析器可以识别它是整型常量,但无法准确断言它是到底是INTEGER、BYTE、SHORTINT、SMALLINT、WORD、LONGWORD中的哪一类型。类型断言的工作通常由类型系统完成。
m_szVal、m_iVal、m_bVal、m_fVal、m_szSet:常量的值。根据常量基本类型,将值存储于相应的字段中。例如,12.31是实型常量,则将12.31存储在mfVal字段中。
m_iEnumIdx:枚举类型描述指针。在大多数语言中,枚举类型数据都通常是以整型值进行存储的。例如:
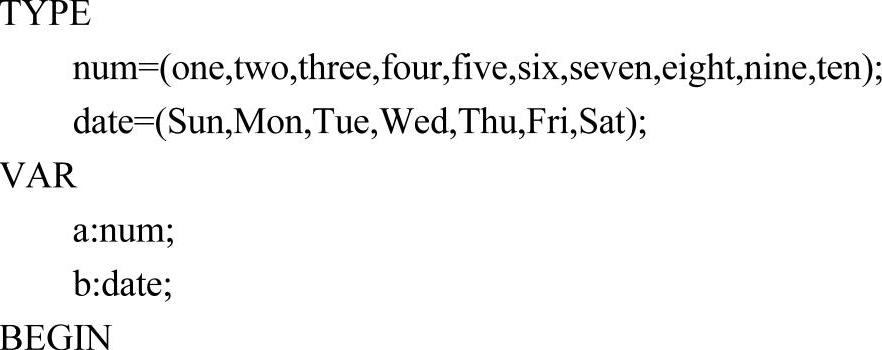
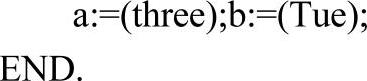
在分析num类型声明时,通常会为num中的每个枚举常量分配一个唯一的序号。同样,编译器也会为date中的每一个枚举常量顺序编号。而a'b中存储的值则是枚举常量的编号。例如,执行完该程序段后,a中的值为2(three的编号为2),b中的值也是2(Tue的编号为2)。当然,Pascal语言的枚举类型不允许用户像C语言那样为枚举常量指定序号。对于枚举常量three与Tue而言,它们的实际存储值是完全相同的,然而,它们所属类型却是完全不同的。因此,在常量信息表中,登记枚举常量时必须记录其所属的枚举类型信息,以便后续阶段分析处理。
m_bUsed:标识常量是否被使用。在整个程序范围内,如果该常量没有被使用,则可以不予分配关注。
3.过程信息表
过程信息表主要用于描述输入源程序中过程、函数的相关信息。通常包括形参列表、返回值类型以及参数传递方式等。除了普通的过程、函数信息之外,如果输入源程序中使用了函数指针类型,那么,相关信息也将在过程信息表中体现。由于函数指针的属性与函数非常相似,所以,笔者将其组织在过程信息表中。早期,函数指针或者函数类型的概念主要是源于函数式语言。标准Pascal是较早接受函数指针概念的语言,之后一些Pascal编译器又参考了C语言的经验,改进了函数指针及其实现细节。因此,Neo Pascal也有必要考虑函数指针的相关实现。过程信息表表项的声明形式如下所示:
【声明4-3】

m_szName:过程、函数名字。注意,由于Neo Pascal并不允许过程、函数的嵌套定义,所以,过程、函数名字必须唯一。
m_eRank:过程等级。标识该过程或函数是主程序还是子过程。
m_eType:表项类型。标识该表项是过程表项、函数表项还是函数指针类型表项。
m_ParaTbl:形参列表信息。存储该过程或函数的形参信息,包括形参名称、形参类型描述、形参变量、形参传递方式等。
m_iReturnType:返回类型描述指针。
m_iReturnVar:返回变量指针。与形参类似,函数的返回值也与普通变量处理比较相似,通常,也需要在变量信息表中建立一个符号表项。
m_eFlag:过程修饰标志。不少语言允许过程、函数的声明与使用不在同一个源程序文件中,甚至允许用户程序调用一些外部定义的过程、函数。例如,用户程序调用系统接口、库函数等。无论是哪种调用方式,编译器都必须知道被调函数的形参列表和返回值类型。熟悉dll库或Windows API的读者应该不难理解,在调用一个函数时,必须事先在程序中显式声明函数头部。在Pascal、C语言中,除了常规的函数声明调用以外,还允许用户程序调用以下两种函数:其他源文件中的函数、其他二进制文件中的函数。Extern标志表示该表项是一个外部函数的头部声明。Forward标志表示该表项是一个内部函数的向前引用声明。注意,前者是现代编译器普遍支持的,它是动态扩展编译器功能的基础。而后者是实现一遍扫描编译的基本要求,其目的就是告知编译器函数的实际定义可能在本文件稍后位置或其他源文件中,保证编译器能够在尚未完整分析函数定义之前,就能知道该如何准确调用此函数。实际上,这样的设计只是为了便于编译器能够在一遍扫描过程中完成编译。当然,在现代编译器实现中,有时也会使用多遍扫描,此时,Forward引用将是完全多余的。
m_iExternStr:外部修饰说明。仅当m_eFlag为Extern时,此字段存储外部函数相关说明信息。例如,外部函数所属的文件名、函数参数传递方式等。为了便于管理,通常将修饰信息统一存储在外部修饰信息表中,而m_iExternStr则是指向相应信息表项的指针。
m_iProcDefI'oken:原型单词流。有时,编译器需要判定过程或函数声明与定义的头信息是否完全相同,仅仅依据其名字、形参列表、返回类型等语义元素作出判断并不一定正确。尤其在输入源程序中存在向前声明时,编译器必须严格判断前后两个声明形式是否完全一致,对于不完全一致的情况,编译器必须给出错误或警告提示。在Pascal语言中,这种判断是相对严格的,有时并不局限于语义层次上的一致。例如,在如下两个函数声明中,其语义是完全相同的,但是当前者是后者的向前引用时(当然,需增加forward关键字),大多数Pascal编译器并不认可,而是提示命名冲突错误。
(1)function aa(a:integer):integer;
(2)function aa(al:integer):integer;
在C语言中,这种判断则相对较弱。C编译器更多关注的是语义层次上的一致,例如,参数类型、参数个数、返回值类型等。
m_Codes:中间代码序列,将在第5~6章中讨论。
m_TmpMemShare:可共享存储区域的临时变量集合。
以下几个属性都将在第8章中讨论:
m_ValSize:相关局部变量的空间大小。
m_TmpLink:临时变量的指针。
m_bUsed:表示过程或函数是否被使用。在整个程序范围内,如果都没有被使用,则不必分配关注。
m_bTmpUsed:表示过程或函数中是否使用了临时变量。
下面简单介绍一下形参列表表项结构及其意义。
【声明4-4】

m_szName:形参名。
m_iParaType:形参类型指针。
m_iParaVar:指向形参所关联变量的指针。
m_eAssignType:传递类型。用于描述形参的传递方式。在程序设计语言中,参数的传递方式主要有三类:值传递、址传递、引用传递。C语言只支持值传递,Pascal语言支持值传递、引用传递(也就是Pascal中俗称的“变参”)。(www.daowen.com)
4.类型信息表
类型系统是程序设计语言的一个研究课题。在编译技术中,更多讨论的是类型系统的实现及其与编译器设计的关系。
类型可能是高级程序设计语言与汇编语言的最主要区别之一。类型的出现确实使得程序设计语言更加丰富多彩,同时也大大提高了程序设计语言的易用性。但是类型也向程序设计语言及其编译器的设计提出了新的挑战。与变量、常量、过程、函数等其他语法元素相比,类型可能是最为复杂的。本章只涉及类型系统中关于类型描述的问题。后续的章节中,还将从其他角度详细讲述类型系统。
类型描述,简而言之,就是设计一种数据结构用于描述程序设计语言的类型。在编译器设计中,由于类型描述最终体现在符号表结构中,因此,有必要在符号表设计中加以考虑。与变量、常量等不同,类型的复杂之处在于其种类繁多且组合灵活。虽然语言本身提供的基本类型(原子类型)有限,但是类型的复合却使其变得异常复杂。例如:
【声明4-5】
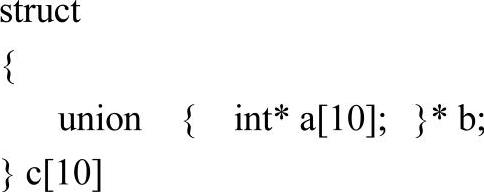
声明4-5并不算太复杂,但编译器试图准确无误地描述c变量的类型却也不是非常容易的。从程序设计语言设计的角度来说,对于具有实际语义的类型复合,通常是不作太多限制的,只是不同的语言对类型复合的描述形式可能不尽相同。例如,Pascal中规定形参列表中的类型只能是基本类型或用户自定义类型,却不能是匿名类型,而C语言中则相对宽松得多。
虽然类型复合比较复杂,但是任何复杂的类型复合的语义是确定唯一的。在语义可能存在二义性时,编译器就必须设法回避。例如,在C语言中,经常会借助于括号来区别指向函数的指针和返回指针的函数。
不同编译器的类型描述可能存在一定的差异,但它们的内核却是惊人地相似,都是使用类型链的形式加以描述的。其基本思想就是以一种线性结构来精准地描述类型的修饰关系,这是一个非常有效且灵活的描述形式。当然,类型链并不是唯一的描述形式。在早期C语言编译器中,出现过位串形式的类型描述。不过,这个方式存在一定的局限,它不足以描述任意形式的类型复合,也不能用于描述数组等类型。
类型链就是按照语义层次将复合形式的类型逐一分解成单一的类型结点,并将这些类型结点依次链接形成一个线性结构。这里,读者必须注意两点:第一,类型链是按语义层次展开的,也就是说,类型链表元素的顺序不同,其描述的类型是不同的。第二,不同程序设计语言的类型表示形式差别较大,C语言是前缀形式,而Pascal则是后缀形式。因此,编译器设计者应该根据源语言的特点确定类型语义的层次。例如,int*a[10]的语义是声明一个含有10个元素的数组,数组元素的基类型是指向整型的指针,所以类型链的描述为“数组一>指针一>整型”。
不同编译器类型链的实现方式可能差异较大,实际上,这个问题的核心就是讨论线性结构的存储形式。关于这个问题,读者可以参考数据结构教材,本书不再赘述。Neo Pascal的类型链是采用了一种类似于顺序线性表的形式,也就是类型信息表。下面,笔者将详细分析类型信息表的表项结构。
【声明4-6】

m_szName:类型名。与变量声明不同,C、Pascal等语言都支持匿名类型。一般而言,即使是匿名类型,系统也会为其自动分配一个唯一的名字。
m_eDataType:数据类型。是一个枚举类型的字段,用于描述该表项的类型标识。取值如下所示:

这里有必要作两点说明:
(1)T_NONE与C语言中的void是不同的,void是C语言提供的一种特殊数据类型,而T_NONE仅用于标识该表项未被使用而已。
(2)T_LONG8是一个特殊的数据类型,表示8字节的有符号整型。由于一些经典程序设计语言的标准都是在16位、32位机时代形成的,包括Pascal在内的许多语言都是不支持8字节整型的。不过,大多数通用机的编译器内部都是支持8字节整型的。这是由于许多程序设计语言的整型都存在有、无符号之分。编译器在处理无符号整型值与有符号整型值进行比较类运算时,必须将无符号整型值转换为等值的有符号整型值。这是因为汇编比较指令要求两个操作数的符号类型是相同的,可以同为有符号数或同为无符号数,但不允许一个有符号数与一个无符号数进行比较。这种情况下,就必须进行强制类型转换。显然,将有符号整型转成无符号整型是不可能的,因此,只能将无符号整型转换为有符号整型。但是,就正整数而言,无符号整型的表示范围要远大于有符号整型。例如,4字节的无符号整型最大能表示的值为4 294 967 295,而4字节的有符号整型最大能表示的值为2 147 483 647。为了不影响运算结果,编译器通常将两者同时转换成8字节的有符号整型进行比较。
m_iLink:指向下一个类型结点的指针,即为下一个类型结点的下标。不过,如果当前表项为枚举类型时,由于枚举类型无法继续进行类型复合,所以m_iLink就复用作为指向枚举常量列表的指针。Neo Pascal有一张全局符号表用于存储枚举常量值。稍后,笔者将详细举例说明。在Pascal中,枚举常量的名字与普通标识符类似,是共享同一个名字空间(命名空间)的。例如,声明代码如下:
VARa:(al,a2,a3);a2:INTEGER;
编译器通常会提示a2标识符己被使用。
m_FieldInfo:记录类型字段列表。前面读者已经对Pascal记录类型有了简单了解。实际上,Pascal的记录类型并不复杂,只是对于大多数读者而言,更习惯使用C语言的结构、联合类型而已。
m_ArrayInfo:数组类型的维度列表。对于数组类型而言,编译器在类型信息表中详细记录数组的维度及其上、下限。与C语言不同,Pascal允许用户定义数组的上、下限。关于数组类型的维度描述,通常还有一种比较常见的形式,那就是不使用列表描述多维数组,而是将多维数组视作多个一维数组的复合,也就是说,将使用n个类型结点来描述一个n维数组。
m_eBaseType:基本类型。使用类型链描述类型几乎是公认的,但是对于类型链长度问题的观点却并不一致。类型链的长度也就是指类型结点的细化程度。一般而言,笔者并不支持极短的类型链形式,因为这种形式失去了构造类型链的意义,但也不表示过长的类型链是绝对占优的。在设计符号表时,应尽可能保证类型链中每个结点的基本类型都可以独立描述。不能满足此条件的表项,可拆分成两个或多个表项,并以类型链形式钩链。
m_szContent:备注。
m_iState:处理状态。这是一个非常重要的标志字段。下面,笔者通过一个C语言的实例来说明m_iState字段的作用,如表4-1所示。
表4-1 递归声明的实例

表面上看,A列的声明并没有什么错误。可上机调试后,读者会发现,C语言并不允许这样的声明形式。由于结构aa的a3字段的类型是aa本身,因此,也将这种声明形式称为“递归声明”。实际上,包括C、Pascal等绝大多数程序设计语言都不支持递归声明。因为编译器无法准确计算这种类型的变量所需的存储空间大小,那么,也就无法进行存储空间的分配了。解决这个问题的方法并不复杂,编译器在处理一个类型时,只需在类型信息表中作一个标记,标识该类型是否已经构造完毕。如果类型没有构造完毕,则不允许对其引用。例如,编译器分析到aa a3时,发现aa类型本身并没有完成构造,这时编译器会给出错误提示。不过,语义子程序无法根据类型信息表判断类型是否己构造完成,因此笔者在类型信息表项中增加了m_iState字段,就是用于标识该类型信息是否已完成构造。只有当语义子程序完成整个类型分析后,才将m_iState置为1,否则为0。然而,B列的声明形式却是特例。在C语言的结构中,允许声明指向本身的指针字段。由于指针字段占用的存储空间大小是由目标机决定的,与具体指向的类型无关,因此,这种声明并不会影响编译器的存储分配。虽然不同的程序设计语言对这种声明的支持不尽相同,但是这种声明形式却是常见的。在Pascal语言中,不允许像C语言那样直接在结构体内声明,但支持形如C列的声明。在这种情况下,编译器通常会作特殊处理。以C列声明为例,在分析aa=^Node时,实际上,Node类型名是未知的,按编译器一贯的处理方式,这时应该给予无效类型名提示。不过,在处理指针类型(变量)声明时,编译器并不会立即判断基类型是否己声明,而通常是在事后某一特定时刻进行判断。如果编译器无法从后续声明中发现Node类型的声明,则依然会报告出错信息。
m_iSize:占用存储空间的大小。在编译过程中,编译器必须能准确计算该类型变量所需存储空间的大小,以便进行存储分配。因此,这个字段在存储分配及目标代码生成中具有极其重要的意义。
下面再来谈谈记录类型字段列表、数组类型的维度列表的结构。
记录类型字段列表并不是全局符号表。通常,一个记录类型结点有一张独立的记录类型字段列表,这与枚举类型信息表是不同的。声明形式如下:
【声明4-7】


m_iLink:字段类型指针。字段的类型可能是非常复杂的,因此,字段类型与变量类型的描述形式是完全一致的。
m_iSize:字段占用的字节数。
m_szVarFieldFlag:可变部分的标志字段名。先来看一个简单的例子,如图4-3所示。
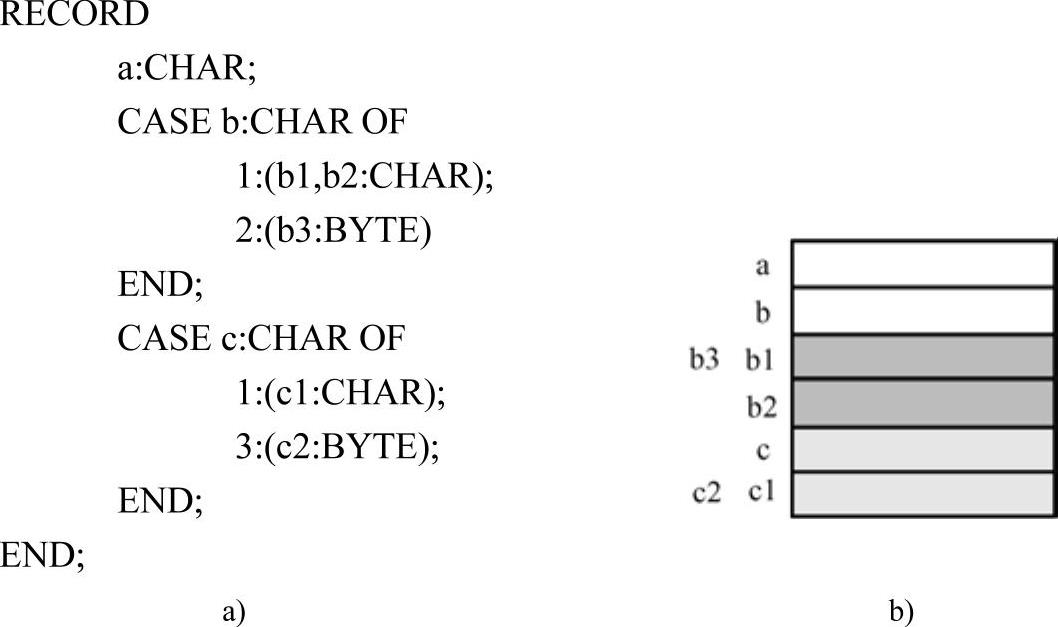
图4-3 可变字段存储分配示意图
a)代码 b)存储分配情况
这里,暂且将CASE结构后的字段称为“可变部分的标志字段”,它也是一个独立的字段。从存储分配的情况来分析,实际上,编译器将一组CASE结构视为一个共用体进行分配。不同CASE结构之间是独立分配存储空间的,并不是共用的。CASE标号之间的字段组共用同一片存储区域,例如,(bl,b2)与(b3)就是共用一片存储区域。而字段组内的字段分量则不共用存储区域,例如,bl与b2都是独立分配存储空间的。CASE标号仅用于标识字段组,也就是说,一组CASE结构内的标号相同的字段组成一个字段组。然而,CASE标号本身却没有实际意义,将上例中的标号“3:”改成“4:”是没有区别的。从编译器的角度而言,并不关注CASE标志字段与标号本身。编译器只需要对记录类型中的字段组进行标识,并且记录哪些字段组可以共用同一片存储区域即可。在记录类型信息表中,就是使用m_szVarFieldFlag字段来标识哪些字段隶属于同一个可变部分。在Neo Pascal中,存储的就是CASE标志字段的名字,如上例中的b、c。
m_szVarFieldConst:可变字段的标号。在Neo Pascal中,该字段存储的就是CASE标号的值,m_szVarFieldFlag、m_szVarFieldConst都相同的记录集就表示一个字段组,字段组内部的分量是不共用存储区域的。
m_iState:处理状态。将在后续章节中详细讨论。
m_iOffset:字段偏移量。即字段首地址相对于记录首地址的字节偏移量。
下面,再来看看数组类型的维度列表。数组类型的维度列表就是用于描述数组维度的上限、下限信息的辅助符号表。与记录类型字段列表类似,它也不是全局符号表,一个数组类型有一张独立的维度列表。与字段列表的结构相比,维度列表要简单得多,只有上限、下限两个字段信息。声明形式如下:
【声明4-8】

5.枚举信息表
在介绍类型信息表时,已经提到了枚举信息表。枚举信息表主要用于存储枚举类型的枚举常量信息。与C语言相比,Pascal的枚举类型简单一些。因此,Neo Pascal的枚举信息表结构也比较简单。此处不再详细给出其声明形式,请读者自行参考Neo Pascal源代码。
6.标号信息表
标号信息表主要用于存储输入源程序的标号信息。虽然Pascal创始人Wirth教授并不提倡使用goto语句,甚至在其结构化程序设计思想中也竭力反对goto语句,不过,Pascal语言仍然提供goto及标号机制。Pascal规定标号使用前必须进行声明,这与C语言是不同的。当然,值得注意的是,标号信息表中不仅包含用户声明的标号,还需要包含编译器自动生成的临时标号。声明形式如下:
【声明4-9】

m_szName:标号名。
m_bDef:是否己定义。在Pascal中,如果用户声明了一个标号,那么,该标号在过程、函数体内的位置定义点的个数必须小于或等于1。也就是说,Pascal允许声明的标号没有具体的位置定义点,当然,这种标号是不允许被goto语句使用的。在分析源程序的过程中,发现一个标号的位置定义点时,将标号信息表中对应的表项的m_bDef字段置true,以免重复。
m_bUse:是否已使用。标号的使用是根据源程序而定的。Pascal语言允许用户声明了一个标号后却不使用。对于未使用的标号,通常,编译器会在分析过程中予以标识,便于后端优化处理。当源程序中goto语句使用了一个标号后,编译器则将标号信息表中对应的表项的m_bUse字段置true,表示该标号已被使用。
至此,已经分析了Neo Pascal的符号表结构。符号表的结构对于理解编译器的设计具有极其深远的意义。因此,笔者认为有必要通过完整的实例分析Neo Pascal的符号表系统,希望读者能结合下一小节的实例深刻理解符号表的设计思想。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。







