读者已经知道,编译器前端主要包括词法分析、语法分析、语义分析与IR生成。与词法分析、语法分析完全不同,从算法、构造工具等角度而言,语义分析与IR生成模块既没有比较成熟的通用算法,也没有自动生成工具,一般都是由手工编码构造的。因此,语义分析与IR生成模块可能也是编译器前端较复杂的模块,它涉及符号表设计、中间代码设计、类型系统等高级话题,本书将在后续章节中详细分析。
编译器的任务是把输入程序翻译为等价的目标程序,所谓“等价”指的就是语义相同,也就是说,尽管两个程序的语法结构与形式完全不同,但它们所表述的含义与运行的结果必定是相同的。从经典编译技术来说,语义分析与IR生成模块主要完成如下两项任务:
(1)对每个语法结构进行静态语义检查,检查符合语法结构的程序是否具有实际含义。
(2)如果静态语义正确,就进行程序的翻译,即生成等价的IR。
由于两者之间的界线可能是比较模糊的,通常,编译器会将它们组织在一遍中完成。
本书讨论的语义分析通常是指静态语义检查。所谓“静态语义检查”(static semantic check)就是指在编译阶段进行的语义错误检查,主要涉及如下几个方面:
(1)类型检查。例如,C语言中的“%”运算符的两个操作数类型只能是整型,否则语义分析必须有出错提示。再如,函数实参的类型必须与形参类型兼容等。
(2)语句相关性检查。例如,default、case只能出现在switch结构中。(https://www.daowen.com)
(3)一致性检查。例如,同一作用域内的变量不允许重名、枚举常量不能重名等。
实际上,由于程序设计语言的差异,静态语义也不尽相同。这里只是列举了一些C语言中较为常见的例子而己。实际上,在程序设计语言中,与静态语义对应的范畴就是动态语义。笔者有必要指出,动态语义检查(dynamic semantic check)并不能在编译阶段完成,因此,也不属于经典编译技术讨论的范畴。例如,当数组下标是一个变量时,数组访问越界就不是静态语义检查能够判断的。通常,动态语义检查都是在程序执行时进行的,需要在目标程序中加入相应的语义检查代码。由于动态语义检查需要耗费运行时资源,因此,C、Pascal等经典编译器都不进行动态语义检查。在动态语义检查方面,Delphi做得不错。当然,对于解释型或混合型的翻译程序而言,实现动态语义检查是相对容易的,例如,Java、C#、Visual Basic等。
最后简单介绍一下IR的相关话题。IR是输入源程序的一种内部表示形式,通常是由编译器设计者定义与使用的,对于编译器用户是透明不可见的。前端将输入源程序等价地翻译成IR,然后,再由后端各模块将IR翻译成目标代码,如图4-1所示。
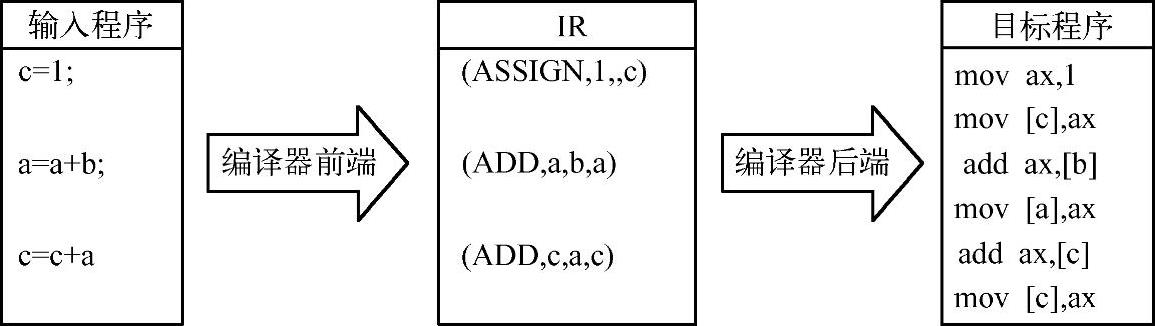
图4-1 中间表示形式
IR是由编译器设计者定义与使用的,根据源语言与目标语言的不同特点,设计者定义各种便于构造编译器的IR形式。关于IR形式的评价,从来就没有正确或错误之分,而只有适合或不适合。不过,无论使用哪种IR,设计者都必须遵循一个原则:IR要足以表达源语言的任何语义,否则,某些源语言的语义可能会在转换成IR的过程中丢失,语义等价的转换也就无从谈起了。
早期编译器设计中并没有使用IR,通常是将输入源程序直接转换为目标程序。虽然在编译效率方面,生成IR的编译器的确无法与直接生成目标代码形式的编译器媲美,但是前者的优点却是后者无法企及的。关于IR的更多内容将在第5章中详述。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。







