通常,推导过程是研究语法分析过程的重要依据。为了便于描述,可以使用一些图形化方式描述推导过程。其中,语法树(syntax tree)是最重要的方式之一。它是推导的图形描述形式,有助于理解一个句子语法结构的层次,简称语法层次。语法层次这个概念在有些书籍上被替换成了优先级,确实如此,在表达式文法中的语法层次就是运算符的优先级。但是,由于作为一门实际程序设计语言的文法不仅包含了表达式,还包含了许多其他的语法结构,这些语法结构之间是可能存在一定的层次关系的,故笔者认为语法层次的说法比优先级更为精准。
与数据结构课程中的树结构类似,语法树也是一棵根在上、枝叶在下的倒长树,语法树的根结点是文法的开始符号。随着推导的展开,当某个非终结符被它的某个候选式替换时,将候选式的所有符号以此非终结符的子结点形式表示。在构建语法树的过程中的任何时刻,将所有的叶结点自左至右排列起来就表示此文法的一个句型。当推导过程完成后,将所有的叶结点自左至右排列起来就表示此文法的一个句子。
例3-5 用语法树描述例3-4的最右推导过程。
构造语法树步骤:
1)文法开始符为E,将E构造为语法树的根。
2)第一步推导将E替换为候选式E opl T,将这三个符号作为E的子结点。
3)第二步推导将T替换为候选式F,将符号F作为T的子结点。
4)第三步推导将F替换为候选式(E),将这三个符号作为F的子结点。
5)依次按照每一步推导构造语法树(如图3-1所示),直至结束。
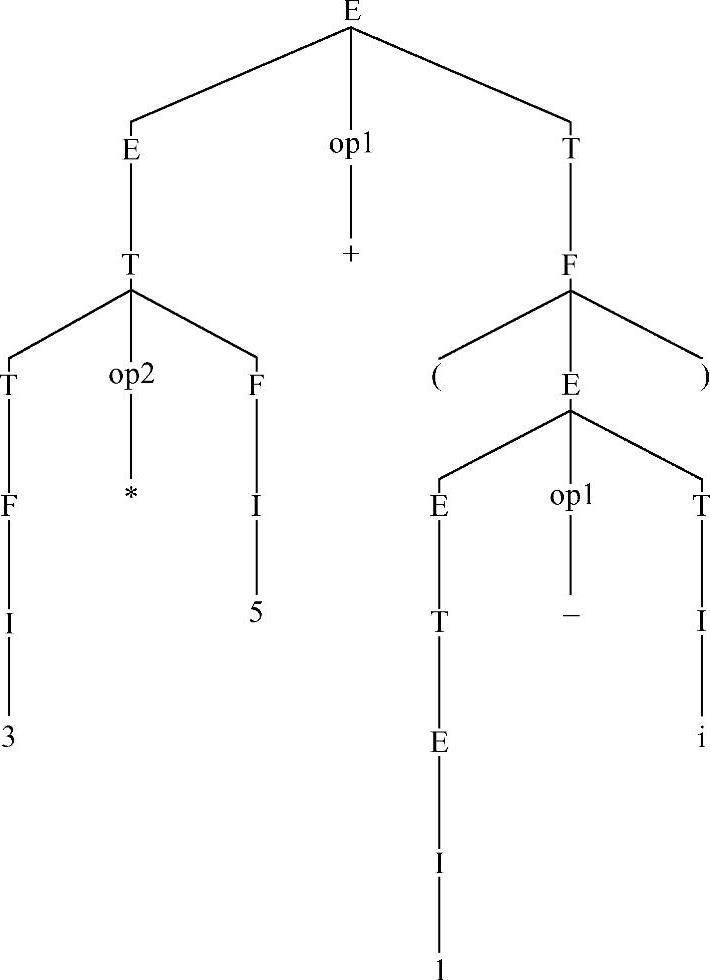
图3-1 3*5+(1-i)的语法树
6)最终,语法树所有叶结点自左至右排列就是3*5+(1-i),表明3*5+(1-i)是文法的句子。
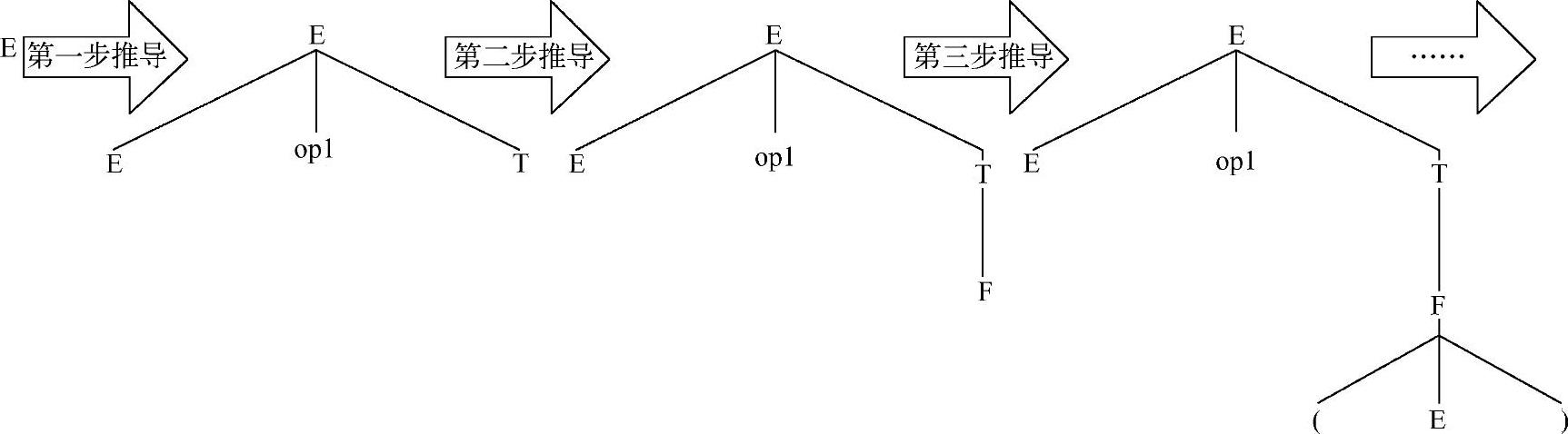
详细的构造过程如图3-2所示。
 (https://www.daowen.com)
(https://www.daowen.com)
图3-2 构造语法树示意图
同样,读者可以尝试依据例j-j的最左推导过程构造语法树,一定会发现得到的语法树与图3-1完全相同。语法树可以表示一个句型或句子的种种可能的不同推导过程,当然包括最左(最右)推导。语法树的步步成长和推导的步步展开之间是完全一致的。
语法树不但描述了推导过程,还说明了句子的语法层次,这对于理解句子的语义是至关重要的。下面,笔者对图3-1的语法树作深入讨论。读者不难发现语法树的叶子分布在树的不同层次上。实际上,深度越深的叶子的语法层次就越高,这是什么原因呢?这与语法树的构造顺序有关。熟悉数据结构的读者不难理解手工依据推导过程构造语法树与树的深度优先遍历比较类似。然而,文法3-3的表达式文法中的语法层次也就是运算符的优先级。在图3-1中,根据语法层次,先计算l-i,再计算3*5,最后计算两者的和。这个语法层次(即优先级)完全符合运算习惯。
语法树是一种语法层次的描述,在语法分析阶段是非常重要的。经典编译理论认为语法树是编译器的必不可少的输出,许多实际编译器的语法分析阶段的主要任务之一就是构建语法树。当然,实际编译器并不一定需要构造显式的语法树。隐式语法树是现代编译技术提出的观点,在基于推导方式的语法分析器中尤为常见,并在一定程度上得到了发展。这主要是由于推导的过程就是一次树的深度遍历过程,所以并不一定需要显式构建语法树。
那么,对于一个文法而言,语法树与一个句型或句子的推导之间是否存在一一对应关系呢?事实上,在大多数情况下,语法树与一个句型或句子的推导是一一对应的。不过,也确实存在例外,请参考下例分析。
例3-6 已知文法如下:
【文法3-4】
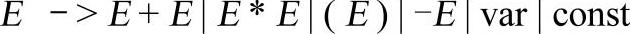
句子3+4*6存在两个不同的最左推导及语法图,如图3-3所示。
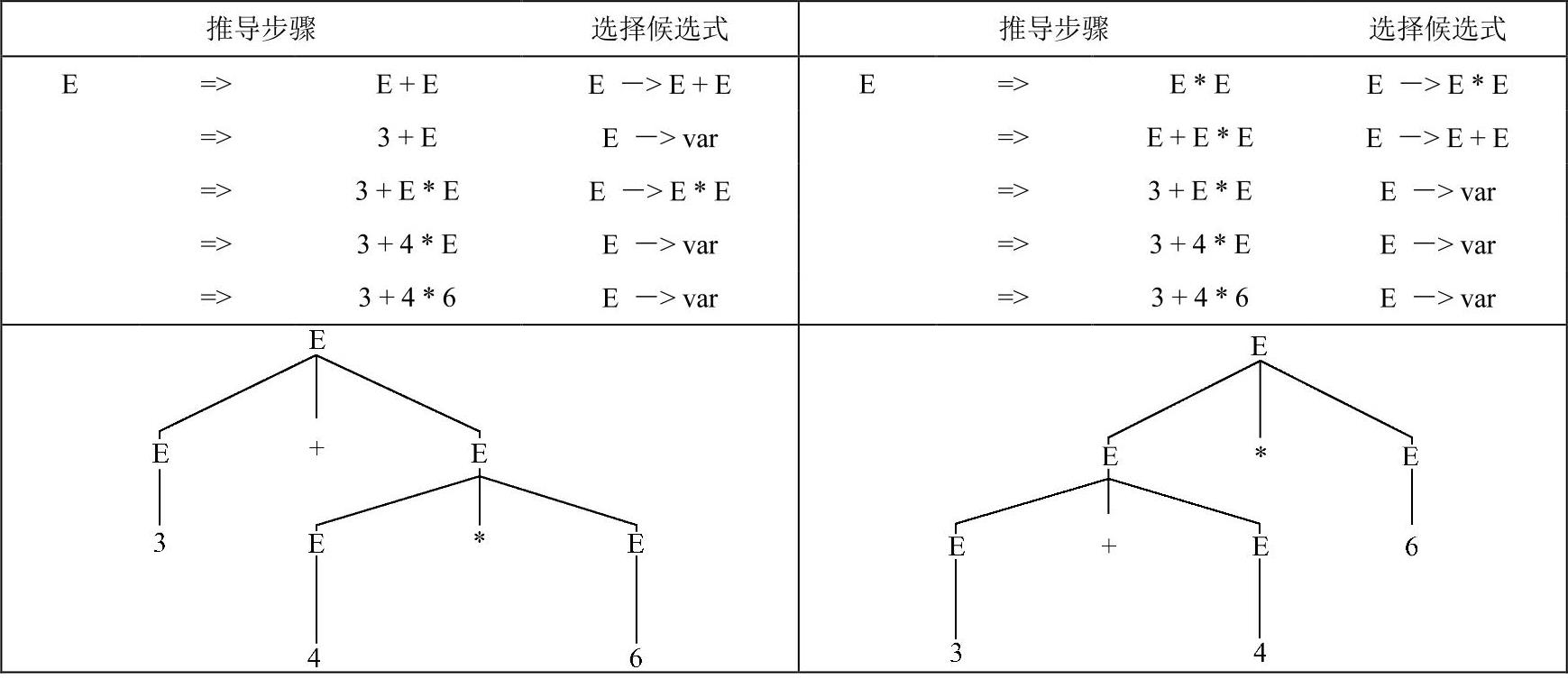
图3-3 二义性文法推导
注意,读者千万不要将本例的推导与例3-3、例3-4的推导混淆。虽然本例表面上与例3-3、例3-4非常相似,都是不同的推导步骤推出了相同的句子,但是,读者一定要深入理解其本质。例3-3、例3-4是由于推导过程中选择不同的非终结符替换所致的。例3-3是最左推导,即每次替换最左的非终结符,而例3-4是最右推导,即每次替换最右的非终结符。由于最左或最右推导所构造的语法树是相同的,也就是说最左或最右推导并不影响句子的语法层次。然而,本例的两个推导都是最左推导,只是由于选择了不同的产生式推导所致。不难看出本例所产生的语法树是不同的,也就是说,本例的两个推导的语法层次结构也是不同的。左图中乘号的语法层次高于加号(表达式文法中的语法层次指的就是运算符优先级),这是符合表达式的运算习惯的。而右图中加号的语法层次高于乘号,显然不符合运算习惯。右图把表达式3+4*6看成(3+41)*6,这是完全错误的。
这种给定文法G,如果任何基于文法的G的句子存在两棵或两棵以上的语法树,称G是存在二义性(ambiguous)的,或称为二义文法。二义性问题的产生并不是推导的错误,而是文法本身的问题。这类文法的语言就像自然语言一样存在二义性,二义性是计算机所不能理解与处理的。严格地说,任何程序设计语言原则上是不允许存在任何二义性的。但这并不是绝对的。在程序设计语言文法中,典型的二义性例子就是IF-ELSE结构,大多数程序设计语言都存在IF ELSE语句的二义性问题,所以编译器设计者作了ELSE就近匹配的约定以解决二义性问题。在3。3节中将详述IF ELSE语句的二义性及其解决方法。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






