前面已经阐述了词法分析器如何识别单词及如何应用转换图描述词法分析器等问题。下面将详述如何高效地应用转换图实现词法分析器。
转换图是由程序流程图改进而成的。同样,转换图也可以等价地转换为程序流程图。完整的转换图就是词法分析器的程序流程图,是实现词法分析器的依据。早期的编译器都是采用这种方式手工编码实现的。这种实现方式对编译器设计者的编程技巧要求非常高。如果非常机械地完全按照转换图的描述编码,所得到的词法分析器的执行效率可能比较低,必须运用编程技巧使词法分析器尽可能精悍高效。因此,这种编码实现方式存在一个严重的不足:程序的耦合度高。当词法定义发生改变时,词法分析器的改动将非常大,甚至是颠覆性的。然而,为什么早期的编译器大多采用这种方式编码实现呢?最主要的原因就是这种方式实现的词法分析器运行时所需的存储空间的代价相对较小。当然,这与大师们的精湛技艺是分不开的。下面,笔者介绍一种更简单的实现方法,它是词法分析器核心理论研究的成果。
经过计算机科学家的多年探索,设计一个能够根据转换图模仿人工应用转换图识别单词的过程完成词法分析的程序并非完全不可能的。读者可以想象一下,模仿人工识别的过程用程序实现并不复杂。主要的问题就是如何将转换图输入计算机,并且可以由词法分析器进行处理。
显然,转换图的形式是不利于输入计算机的,众所周知,最便于程序处理的数据结构就是表格。如果能将转换图转化为表格或者类似的数据结构,那么,词法分析器就可以识别并处理转换图了。事实上,将转换图等价转换为二维表格的过程可以参照以下四个步骤:
1)将转换状态集合作为行,将所有箭弧上的字符集合作为列。
2)按箭弧填写表格中的单元格。填写方法如下:在箭弧始结点状态所在的行和箭弧上的标记所在的列所指示的单元格中填入箭弧终结点状态。依此法将转换图中的所有箭弧填入表格中。
3)在空单元格内填入另一个特殊标记“-l”,表示该行状态下不允许读入该列“字符”。
4)用特殊标记标识转换状态集合中的开始状态与终止状态,这里分别使用“*”与“♯”。
按照上面的步骤,可以将图2-4转换为表2-4的形式。
表2-4 Pascal实型常量转换表
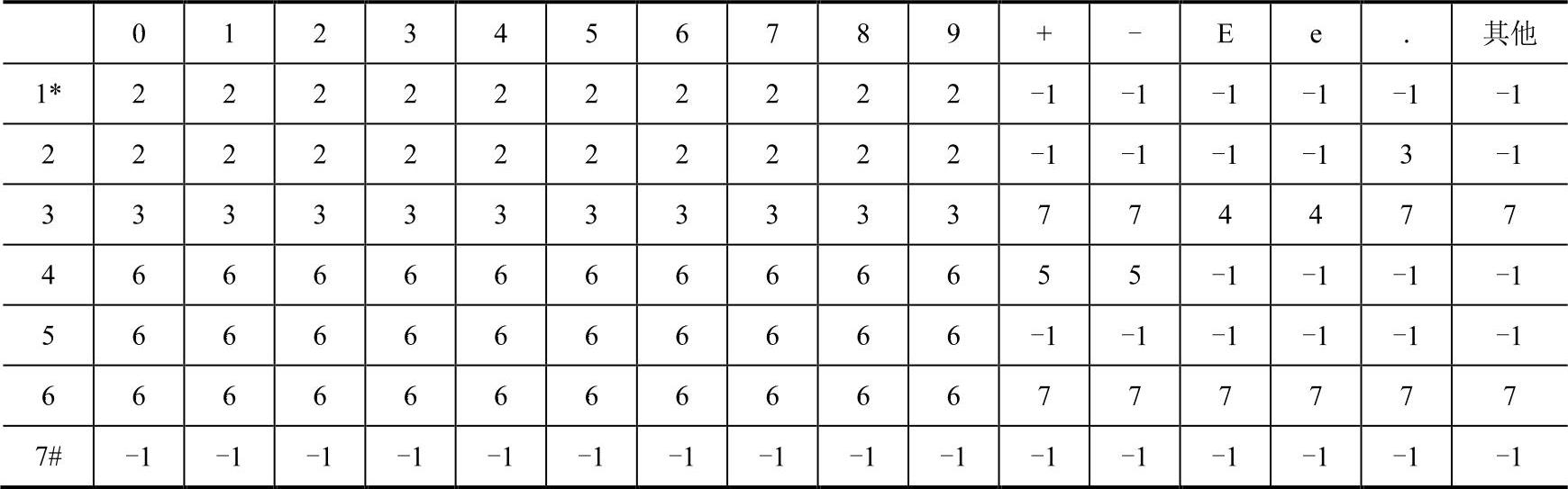
注意,“#”、“*”之类的特殊标记可以任选。另外,这里的“其他”是简略书写,完整的转换表应该罗列该语言可以接受的所有字符(除数字、+/_、E/e外)。
表2-4的功能完全等价于图2-4的转换图。表格的行表示原转换图的状态集合,列表示转换图中所有字符集合。表格中的单元格表示所在行状态下读入一个所在列的字符时转入的状态。读者可以自行选择实例进行分析。
下面,就来设计一个基于转换表进行自动识别单词的程序,即简单的词法分析器。程序2-1并非完整的Neo Pascal词法分析器,只是旨在说明如何设计一个基于转换表的词法分析器。理解了此算法思想,也就理解了词法分析器的核心。
程序2-1-Lex.cpp

第1行:声明转换表,第一维表示语言的字母表,第二维表示状态。
第4行:iPos表示源程序当前读取位置,即读取指针。
第6行:iState表示当前状态,初始设置为0,即表示开始状态为0。
第7行:单词缓存区。
第8~25行:循环读取源程序文本字符,直至源程序文本尾。bTag标志指示当前单词是否出错。
第10行:将源程序的当前字符加入单词缓存区。
第11行:查询当前状态下读取当前字符时的转换状态,这是程序的核心部分。(https://www.daowen.com)
第12行:如果查询得到的转换状态为1,表示当前状态下不允许读取当前字符。
第13行:置出错标志bTag为true。
第15行:调用IsTerminal函数判断转换状态是否为终止状态。
第16行:将当前状态设为查询得到的转换状态。
第17行:当前状态下读取当前字符时,转换状态为终止状态,即得到一个单词。
第19行:由于超前搜索识别,必须将当前读取位置回退一个字符。
第20行:将单词缓存区回退一个字符。
第21行:调用ProcessToken处理单词。
第22行:将单词缓存区清空。
第23行:当前状态置为0。
程序2-1虽然只有26行,却是词法分析器的核心。请读者务必理解该程序的设计思想。另外,为了便于设计与实现,本书所有的程序都将使用C++描述。在程序2-1中没有实现ProcessToken函数,这个函数的主要功能是处理与输出单词。下面,就详细讨论这个问题。
词法分析器识别得到的单词流是语法分析器的输入,那么,词法分析器需要提供哪些信息给语法分析器昵?以什么方式传递给语法分析器昵?这些问题是需要设计者回答的。
在编译器设计中,最常见的单词存储形式就是三元组(单词ID,单词备注,单词行号)。
单词行号一般包含两部分信息:单词所在的源程序文件名、单词在源程序文件中的行号。这些信息主要用于出错处理,可以提供错误的位置信息,便于用户定位修改源程序。行号信息还是程序调试的重要依据。调试信息中主要包含的就是源程序与目标程序之间的对应关系,而建立这些行号对应关系的基础数据就是单词行号。
其次,对于编译器而言,单词可以分为三类:标识符、常量、系统单词。下面,分别讨论这三类单词的表示形式。
标识符的表示形式:(标识符的ID,用户标识符名,单词行号)。通常,所有用户标识符都使用同一ID。而在“单词备注”域中存储用户标识符的实际名字。
常量的表示形式:(常量的ID,在常量表中的位置,单词行号)。通常,常量的ID是根据常量的类型确定的,即相同数据类型的常量的ID是相同的。当然,这里的数据类型并不是真正的详细数据类型,在词法分析阶段,只将常量分为整型、实型、字符串等类型,无需详细区别是哪种详细类型(例如,INTEGER、SHORTINT等)。常量ID可用于指示常量的数据类型。在词法分析时,对识别所得到的常量还必须登记入常量表,便于语法分析使用。在常量的三元组中必须记录该常量在常量表中的位置。
系统单词(即关键字、运算符、界符)的表示形式:(ID,不使用,单词行号)。通常,程序设计语言的每一个系统单词都拥有一个唯一的ID编号。语法分析器只需根据ID就可以区别是哪个系统单词了。而系统单词的三元组中“单词备注”域是不使用的。不难发现,词法分析器对于关键字、运算符、界符单词的处理是完全相同的,因此,笔者才将这三类合并为系统单词类。关于Neo Pascal的系统单词及其ID可参见2.3.1节。
最后,简单讨论一下单词流是如何传递给语法分析器的。这主要取决于词法分析是作为一个独立阶段还是将它设计为独立的一遍。词法分析作为一个独立阶段就是指将词法分析器作为一个函数,由语法分析器调用。每次调用词法分析器只识别一个单词,然后将单词直接传递给语法分析器处理。整个过程由语法分析器控制,在语法分析过程中,进行单词识别。词法分析作为独立的一遍就是指词法分析器将对整个源程序文件扫描一次,识别出所有的单词,然后将源程序以单词流的方式传递给语法分析器处理。这两种方式各有利弊,且各有成功的应用案例。为了使读者更清晰地理解编译器的架构,故Neo Pascal将词法分析作为独立的一遍扫描。Neo Pascal词法分析器的模型示意如图2-5所示。
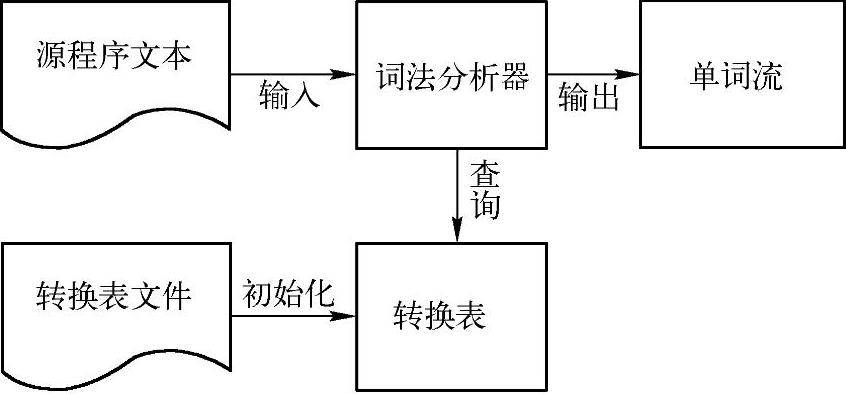
图2-5 词法分析器模型
至此,已经详细阐明了词法分析器的设计,读者对词法分析的基本理论、设计思想与算法核心应该有所了解,这是剖析Neo Pascal词法分析的基础。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。




