通常,设计一个完整的词法分析器需要考虑三个部分:输入源程序字符流、按照词法定义识别单词、输出单词流。本节将围绕这三个部分讨论词法分析器的设计与实现。
首先讨论如何输入源程序字符流。读者或许认为源程序字符流输入无非就是将源程序读入内存的过程,这应该是非常简单的,这个想法不无道理。在2GB内存成为标准配置的今天,将源程序文件完全读入内存确实并非难事。不过,在早期硬件条件相对较差时,就不允许编译器将源程序文件完全读入内存了。许多编译器设计者必须考虑如何让编译器在极为有限的内存中完成编译工作,同时,还要尽可能将有限的内存留给符号表使用。因此,初始化时不可能将源程序文件完全读入内存。那么,是不是每次都是直接从外存读取数据呢?众所周知,内、外存数据交换是有代价的,尤其是外存访问速率较低时,频繁的内、外存数据交换可能耗时较长。由此,设计者必须在时间与空间之间作出抉择。通常的解决方法就是设置一个内存缓冲区,每次以数据块为单位读取源程序文本存入内存缓冲区中,以备识别程序处理。这样,编译器设计者就必须考虑数据块的大小以及缓冲区的访问策略等问题。不过,在今天看来,无论是内存容量还是操作系统支持,笔者认为详细讨论此类话题的实际意义已经不大了。
前面,笔者简单引入了缓冲区的概念。下面,将切入正题,重点讨论单词的识别。
实际上,识别单词就是一种特殊的子串搜索过程。关于字符串子串搜索算法原理与实现,读者应该并不陌生。或许有些读者还会联想到经典的KMP模式匹配算法。那么,词法分析器到底是使用哪种算法的呢?要回答这个问题,就必须理解词法分析器与传统子串搜索算法的区别:
(1)起始位置是己知的。在词法分析器搜索一个单词之前,子串在父串中的起始位置是己知的。单词的起始位置就是上一个单词结束时搜索指针的位置加上其后的无关字符个数。无关字符应视具体的实现语言而定。例如,C语言中的不是出现在字符、字符串常量中的空格、回车、Tab等都视为无关字符。然而,Python的语句行前部的空格、Tab对于程序语义是有影响的,因此,就不能视为无关字符。对于有编译预处理器的编译器而言,剔除无关字符可以由编译预处理器完成。不过,编译预处理器并不能将源程序文件中的所有无关字符一概剔除,必须保证单词与单词之间存在必要的分割字符。例如,“int a:”中的无关字符是不能在编译预处理时剔除的,因为其中的空格对于词法分析是有实际意义的。
如图2-1所示,根据超前搜索识别的原则,当搜索指针移动到“e”后面一个字符时,发现单词“while”识别完成并将其提交。对于C语言而言,本例中的两个空格是无关字符,故搜索指针直接跳过这两个空格即可。当搜索指针移动到“f”时,由于“f”不是无关字符,那么,下一个待识别单词的起始位置就是“f”的位序。搜索指针从起始位置开始识别单词。假设将“(”字符替换为“@”,显然“@”不是任何有效的C语言单词的起始字符。同时,也不是C语言规定的无关字符,因此,并不能跃过“@”继续识别,只能中断分析并提示出错。
 (https://www.daowen.com)
(https://www.daowen.com)
图2-1 词法分析器起始位置
(2)子串是未知的。在开始识别一个单词之前,编译器是无法预知下一个单词的种类及其形式的。因此,词法分析器不可能像传统子串搜索算法那样给定子串,更不可能像KMP算法那样预先分析处理子串。
现在可以设计一个识别标识符的小程序。不同的程序设计语言关于标识符的词法定义是不尽相同的,例如,C语言规定标识符可以是以字母、下画线开头后跟字母、下画线、数字的任意组合。而Pascal语言规定标识符可以是以字母开头后跟字母、数字的任意组合。由于在识别单词前,待识别单词的起始位置是已知的,因此,不必过多考虑。这个小程序的设计应该是非常容易的。下面,以Pascal语言为例,给出简单的设计流程,如图2-2所示。
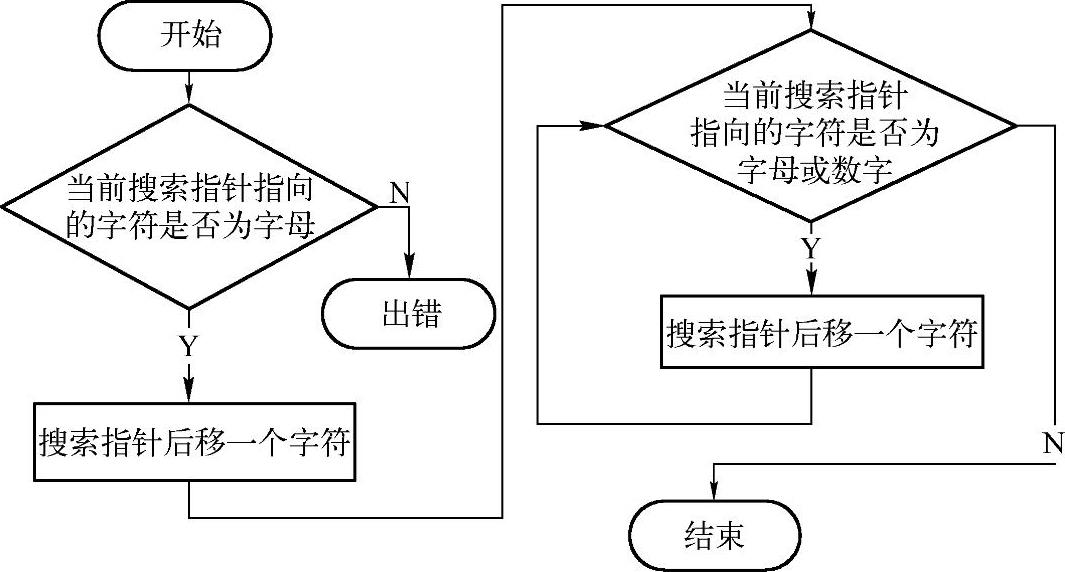
图2-2 识别Pascal标识符的程序流程图
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。




