【摘要】:我们建立计量模型如下其中,被解释变量shareit为第i个电视频道第t年在全国的收视份额,i=1,2,…下面我们列出公式4-1中所含变量的定义及其描述统计量。
上述6年数据的变量较少,没有得到稳定且具有显著性的影响因素,在实证模型Ⅱ中我们将品牌健康指数、新闻节目质量、综艺节目质量和电视剧节目质量四个指标加入解释变量中,由于数据来源的限制,只能利用3年的完整数据进行回归。
我们建立计量模型如下
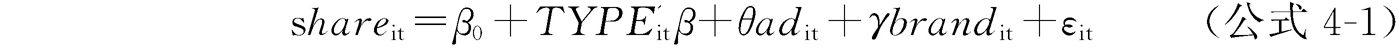
其中,被解释变量shareit为第i个电视频道第t年在全国的收视份额,i=1,2,…,N, t=1,2,…,T。ad是各电视频道的广告时长,brand代表卫视的品牌指数。TYPE是一个由各种类型的节目占节目总数之比重所构成的列向量,TYPE’是它的转置矩阵,β是与向量TYPE所包含各变量对应的系数构成的列向量。ε是随机误差项。在我们的样本中,频道数为45个(N=45),时间跨度为2010—2012年(T=3),所以我们的样本容量为135。(https://www.daowen.com)
我们把电视的节目类型分为15种,但其中有5种节目类型的数量极少,中位数为0,所以我们舍弃这5种节目类型,向量TYPE 中包含的变量个数为10。[1]我们的数据来自中国广视索福瑞和央视市场研究的调查数据。下面我们列出公式4-1中所含变量的定义及其描述统计量(见附表1)。新闻类节目比重(News)、综艺类节目比重(Variety)、电视剧比重(Drama)、专题类节目比重(Special)和生活类节目比重(life)这五个变量的均值都超过了5,这说明这5种节目类型是各个电视频道播出频率较高的。[2]
附表1 各变量描述统计量

免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。




