本节的标题是C语言及C++语言,而不是单一的一种语言,是因为本书有些程序的书写包含了这两种语法。对于考试答题来说,C++不因为它是C语言的升级版就能取代C。C和C++是各有所长的,我们从两者中挑选出来对考研答卷有利的部分,组合起来应用。下面具体介绍针对考研数据结构的C和C++语言基础。
1.数据类型
对于基本的数据类型,如整型int、long、…(考研中涉及处理整数的题目,如果没有特别要求用int足够了)等,字符型char,浮点型float、double、…(对于处理小数的问题,在题目没有特殊要求的情况下用float就足够了)等。这些大家都了解,就不再具体讲解了,这里主要讲解的是结构型和指针型。
(1)结构型
结构型可以理解为用户用已有数据类型(int,char,float…)为原料制作的数据类型。其实我们常用的数组也是用户自己制作的数据类型。数组是由多个相同数据类型的变量组合起来的,例如:inta[maxSize];//maxSize是已经定义的常量
该语句就定义了一个数组,名字为a,就是将maxSize个整型变量连续地摆在一起,其中各整型变量之间的位置关系通过数组下标来反映。如果想制作一个数组,第一个变量是整型变量,第二个变量是字符型变量,第三个变量是浮点型变量,该怎么办呢?这时就用到结构体了。结构体就是系统提供给程序员制作新的数据类型的一种机制,即可以用系统已经有的不同的基本数据类型或用户定义的结构型,组合成用户需要的复杂数据类型。
例如,上面提到的要制作一个由不同类型的变量组成的数组可以进行如下构造:

上面的语句制造了一个新的数据类型,即TypeA型。语句intb[3];定义了一个数组,名字为b,由3个整型分量组成。而语句TypeA a;同样可以认为定义了一个数组,名字为a,只不过组成a数组的3个分量是不同类型的。对于数组b,b[0]、b[1]、b[2]分别代表数组中第一、第二、第三个元素的值。而对于结构体a,a.a、a.b、a.c分别对应于结构体变量a中第一、第二、第三个元素的值,两者十分相似。
再看语句TypeAa[3];,它定义了一个数组,由3个TypeA型的元素组成。前边已经定义TypeA为结构型,它含有3个分量(其实应该叫作结构体的成员,这里为了类比,将它叫作分量),因此a数组中的每个元素都是结构型且每个元素都有3个分量,可以把它类比成一个二维数组。例如,intb[3][3];定义了一个名字为b的二维数组。二维数组可以看成其数组元素是一维数组的一维数组,如果把b看成一个一维数组,其中的每个数组元素都有3个分量,与a数组不同的地方在于,b中每个元素的3个分量是相同类型的,而a数组中每个元素的3个分量是不同数据类型的。从b数组取第一个元素的第一个分量的值的写法为b[0][0],对应到a数组则为a[0].a。
结构体与数组类比关系可以通过图1-1来形象地说明。
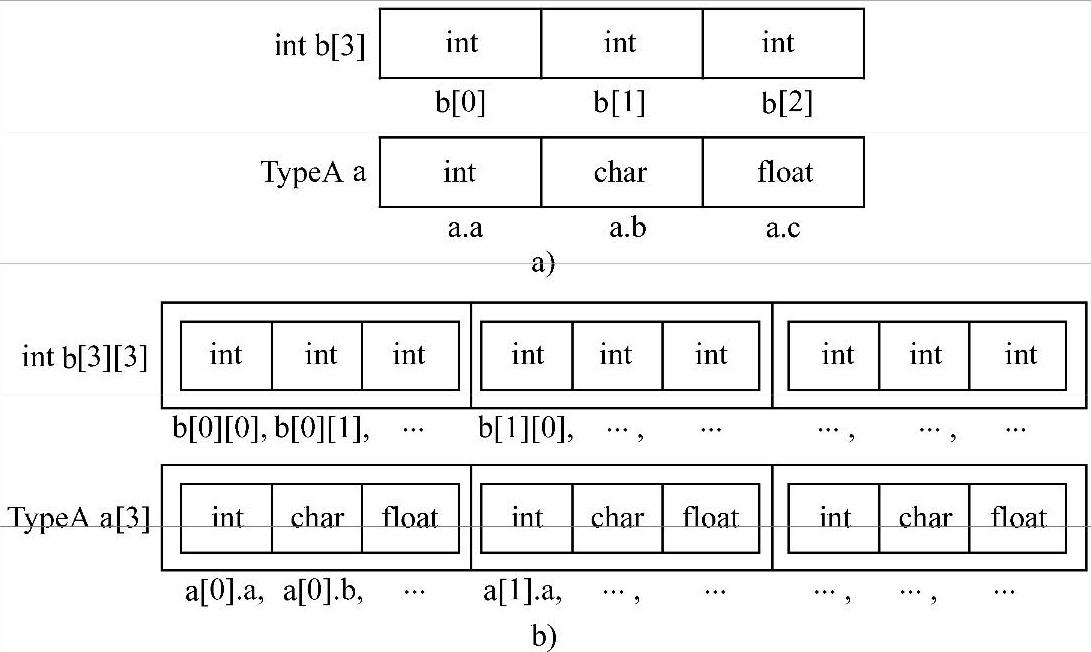
图1-1 结构体与数组的类比
a)结构体和一维数组的类比 b)数组和结构体数组的类比
(2)指针型
指针型和结构型一样,是比较难理解的部分。对于其他类型的变量,变量里所装的是数据元素的内容,而指针型变量里装的是变量的地址,通过它可以找出这个变量在内存中的位置,就像一个指示方向的指针,指出了某个变量的位置,因此叫作指针型。
指针型的定义方法对每种数据类型都有特定的写法,有专门指向int型变量的指针,也有专门指向char型变量的指针等。对于每种变量,指针的定义方法有相似的规则,例如以下语句:
int*a; //对比一下定义int型变量的语句:int a;
char*b; //对比一下定义char型变量的语句:char b;
float*c; //对比一下定义float型变量的语句:float c;
TypeA*d; //对比一下定义TypeA型变量的语句:TypeA d;
上面4句分别定义了指向整型变量的指针a、指向字符型变量的指针b、指向浮点型变量的指针c和指向TypeA型变量的指针d。与之前所讲述的其他变量的定义相对比,指针型变量的定义只是在变量名之前多出一个“*”而已。
如果a是个指针型变量,且它已经指向了一个变量b,则a中存放变量b所在的地址。*a就是取变量b的内容(x=*a;等价于x=b;),&b就是取变量b的地址,语句a=&b;就是将变量b的地址存于a中,即大家常说的指针a指向b。
指针型在考研中用得最多的就是和结构型结合起来构造结点(如链表的结点、二叉树的结点等)。下面具体讲解常用结点的构造,这里的“构造”可以理解成先定义一个结点的结构类型,然后用这个结构型制作一个结点。这样说虽不太严谨,但便于理解。
(3)结点的构造
要构造一种结点,必须先定义结点的结构类型。下面介绍链表结点和二叉树结点结构型的定义方法。
1)链表结点的定义。
链表的结点有两个域:一个是数据域,用来存放数据;另一个是指针域,用来存放下一个结点的位置,如图1-2所示。
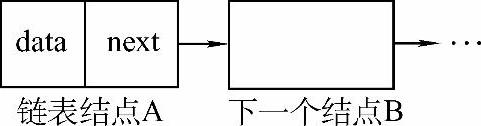
图1-2 链表结点
链表结点的结构型定义如下:

上面这个结构型的名字为Node,因为组成此结构体的成员中有一个是指向和自己类型相同的变量的指针,内部要用自己来定义这个指针,所以写成struct Node*next;。这里指出,凡是结构型(假设名为a)内部有这样的指针型(假设名为b),即b是用来存放和a类型相同的结构体变量地址的指针型(如图1-2中结点A的指针next,next所指的结点B与结点A是属于同一结构型的),则在定义a的typedefstruct语句之后都要加上a这个结构型的名字,如上述结构体定义中黑体的Node。与之前定义的结构型TypeA相比较,会发现这里的结构型Node在定义方法上的不同。
有的参考书中把上述链表结点结构体定义写成如下形式:

可以发现,有一个“node”和一个“Node”,即结构体定义中的上下两个名称不同。其实对于考研来说,这样写除了增加记忆负担之外,没有其他好处,所以希望考生在定义结点结构型的时候,将上下名称写成一致,并且如果结构体内没有指向自己类型的指针,也可以把黑体的Node加上,这样更方便记忆,虽然写出来样子比较难看,但不至于被扣分。
2)二叉树结点的定义。
在链表结点结构型的基础上,再加上一个指向自己同一类型变量的指针域,即二叉树结点结构型,例如:

在考研的数据结构中,只需要熟练掌握以上两种结点(链表、二叉树)的定义方法,其他的结点都是由这两种衍生而来的(其实二叉树结点的定义也是由链表结点的定义衍生而来的,二叉树结点只不过比链表结点多了一个指针而已),无须特意地去记忆。
说明:对于结构型,用来实现构造结点的语法有很多不同的表述,没必要全部掌握。上面讲到的那些语法用来构造结点已经足够用了,建议大家熟练掌握,其他的写法可暂时不予理睬。有些语法对考试来说既复杂又没有意义,例如,上面二叉树结点的定义有些参考书中写成:
可以看到在最后又多了个*btnode,其实在定义一个结点指针p的时候,BTNode*p;等价于btnode p;。对于定义结点指针,BTNode*p;这种写法是顺理成章的,因为它继承了之前int*a;、char*b;、char*c;和TypeA*d;这些指针定义的一般规律,使我们记忆起来非常方便,不必再加个btnodep;来增加记忆负担。因此在考研中我们不采取这种方法,对于上面的结构体定义,删去*btnode,统一一个BTNode就可以解决所有问题。
通过以上的讲解,知道了链表结点和二叉树结点的定义方法。结构型定义好之后,就要用它来制作新结点了。
以二叉树结点为例,有以下两种写法:
①BTNode BT;
②BTNode *BT;
BT=(BTNode*)malloc(sizeof(BTNode)); //此句要熟练掌握
①中只用一句就制作了一个结点,而②中需要两句,比①要烦琐,但是考研中用得最多的是②。②的执行过程:先定义一个结点的指针BT,然后用函数malloc()来申请一个结点的内存空间,最后让指针BT指向这片内存空间,这样就完成了一个结点的制作。②中的第二句就是用系统已有的函数malloc()申请新结点所需内存空间的方法。考研数据结构中所有类型结点的内存分配都可用函数malloc()来完成,模式固定,容易记忆。
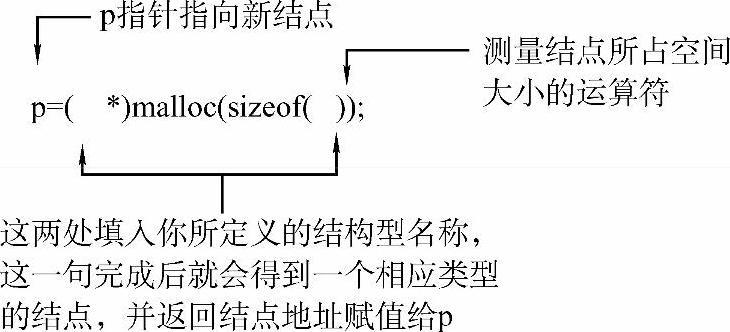
图1-3 结点空间申请函数
图1-3所示为利用空间申请函数申请一个结点空间,并用一个指针(图中为p)指向这个空间的标准模板。考生需要将这个模板背下来,以后制作一个新结点的时候,只要把结点结构型的名称填入图1-3括号中的空白处即可。
说明:除此之外,还有一个动态申请数组空间的方法,相对于上面提到的一次申请一个结点,这种方法可以认为是一次申请一组结点,语法如下(假设申请的数组内元素为int型,长度为n,当然这里的int型可以换成任何数据类型,包括自己构造的结构型):
int *p;
p=(int *)malloc(n * sizeof(int));
这样就申请了一个由指针p所指的(p指向数组中第一个元素的地址)、元素为int型的、长度为n的动态数组。取元素的时候和一般的数组(静态数组)一样,如取第二个元素,则可写成p[1]。
可以看到申请数组空间(或者说一组结点)的方法同上面申请一个结点的方法的不同之处仅在于,sizeof运算符前要乘以n。sizeof是运算符,不是函数,但是在考研时你完全可以把它当作一个以数据类型为参数,返回值为所传入数据类型所占存储空间大小的函数来理解。
②句中的BT是个指针型变量,用它来存储刚制作好的结点的地址。因BT是变量,虽然现在BT指向了刚生成的结点,但是在以后必要的时候BT可以离开这个结点转而指向其他结点。而①则不行,①中的BT就是某个结点的名字,一旦定义好,它就不能脱离这个结点了。从这里就看到②比①更灵活,因此②用得多,并且②完全可以取代①(②中BT的值不改变就相当于①)。
对于①和②中的BT取分量的操作也是不同的。对于①,如果想取其data域的值赋给x,则应该写成x=BT.data;,而对于②,则应该写成x=BT->data;。一般来说,用结构体变量直接取分量,其操作用“.”;用指向结构体变量的指针来取分量,其操作用“->”。(https://www.daowen.com)
这里再扩展一点,前边提到,如果p是指针(假设已经指向x),*p就是取这个变量的值,a=*p;等价于a=x;,那么对于②中的BT指针,如何用“.”来取其data值呢?类比p,*BT就是BT指向的变量,因此可以写成(*BT).data;((*BT).data;与BT->data是等价的)。注意,对于初学者来说,*BT外边最好用括号括起来,不要写成*BT.data,因为你有可能不清楚运算符的优先级,在不知道运算符优先级和结合性的情况下,最好依照自己所期望的运算顺序加上括号。有可能这个括号加上是多余的,但是为了减少错误,这种做法是有必要的。对于刚才那句,我们所期望的运算顺序是先算*BT,即用“*”先将BT变成它所指的变量,然后再用“.”取分量值,因此写成(*BT).data。再例如,这样一个表达式a*b/c,假设你不知道在这个表达式中先算乘再算除,而你所期望的运算顺序是先算乘再算除,为了减少错误,最好把它写成(a*b)/c,即便这里的括号是多余的。
说明:对于上述两种结点结构体定义的写法,有些同学可能会说还有更简便的形式,写法如下。
链表结点:

二叉树结点:

这种写法虽然简单,但是在一些纯C编译器中是通不过的,如果你所报考的目标学校严格要求用纯C语言来写程序,则不能这样写结构体定义。
(4)关于typedef和#define
1)typedef。
在一些教材中,变量定义语句中会出现一些你从来没见过的数据类型,如类似于ElemtypeA;的变量定义语句,要说明这个问题,先来说明一下typedef的用法。typedef可以理解为给现有的数据类型起一个新名字,如typedef struct{…}TypeA;即给“struct{…}”起了一个名字TypeA,就好比你制作了计算机中的整型,给它起了个名字为int,如果再想给int型起个新名字A,就可以写typedefintA;。这样定义一个整型变量x的时候,Ax;就等价于intx;。在考研中,typedef用得最多的地方就在结构型的定义过程中,如上述二叉树结点的结构体定义,其他的地方几乎不用。新定义的结构型没有名字,因此用typedef给它起个名字是有必要的。但是对于已有的数据类型,如int、float等已经有了简洁的名字,还有必要给它起个新名字吗?有必要,但不是在考研数据结构中。
2)#define。
除了陌生的数据类型以外,还有一些陌生的东西,比如在一个函数中会出现return ERROR;、return OK;之类的语句。其实,ERROR和OK就是两个常量,作为函数的返回值来提示用户函数操作结果,这样做的初衷是想把0、1这种常作为函数返回标记的数字定义成ERROR和OK,以达到比起数字来更人性化、更容易理解的目的,但结果却适得其反,让新手们更困惑了。#define对于考研数据结构可以说没有什么贡献,我们只要认得它就行。例如,#define maxSize 50这句,即定义了常量maxSize(此时x=50;等价于x=maxSize;)。在写程序答题的时候,如果你要定义一个数组,如int A[maxSize];加上一句注释“/*maxSize为已经定义的常量,其值为50*/”即可。
说明:本书的作用在很大程度上是做了一个翻译的角色,站在学生的角度把课本上用过于专业化的术语描述的事情用通俗易懂的语言表达出来。
2.函数
说明:只要是算法设计题,就要用到函数,所以有必要介绍使用函数的一些注意事项。
(1)被传入函数的参数是否会改变

上面定义的函数需要一个整型变量作为参数,并且在自己的函数体中将参数做自增1的运算。执行完以下程序段之后a的值是多少呢?
a=0; //①
f(a); //②
有些同学可能以为a等于1。这个答案是错误的,可以这样理解,对于函数f(),在调用它的时候,括号里的变量a和①中的变量a并不是同一个变量。在执行②的时候,变量a只是把自己的值赋给了一个在f()的定义过程中已经定义好的整型变量,假设为x,即②的执行过程拆开看来是这样两句:x=a;和++x;,因此a的值在执行完①、②两句之后不变。
如果要想让a依照f()函数体中的操作来改变,应该怎么写呢?这时就要用到函数参数的引用型定义(这种语法是C++中的,C中没有,C中是靠传入变量地址的方法来实现的,写起来比较麻烦且容易出错,因此这里采用C++的语法),其函数定义方法如下:

这样就相当于a取代了x的位置,函数f()就是在对a本身进行操作,执行完①、②两句后,a的值由0变为1。
上面讲到的是针对普通变量的引用型,如果传入的变量是指针型变量,并且在函数体内要对传入的指针进行改变,则需写成如下形式:

执行完上述函数后,指针x的值自增1。
说明:这种写法很多同学不太熟悉,但是它在树与图的算法中应用广泛,在之后的章节中考生要注意观察其与一般引用型变量的书写差别。
上面是单个变量作为函数参数的情况。如果一个数组作为函数的参数,该怎么写呢?传入的数组是不是也为引用型呢?对于数组作为函数的参数,考研数据结构中常见的有两种情况,即一维和二维数组。
一维数组作为参数的函数定义方法如下:

对于第一个参数位置上的数组的定义,只需写出中括号即可,不需要限定数组长度(不需要写成f(int x[5],intn)),即便传入的数组真的长度为5;对于第二个参数n,是写数组作为参数的函数的习惯,用来说明将来要传进函数加工的数组元素的个数,并不是指数组的总长度。
二维数组作为参数的函数定义方法如下:
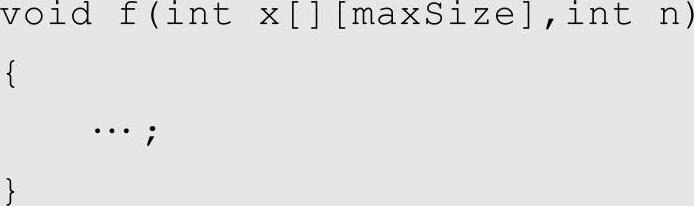
如果函数的参数是二维数组,则数组的第一个中括号内也不需要写数组长度,而第二个中括号内必须写上数组长度(假设maxSize是已经定义的常量)。这里需要注意,所传入的数组第二维长度也得是maxSize,否则出错。例如:

要注意的是,将数组作为参数传入函数,函数就是对传入的数组本身进行操作,即如果函数体内涉及改变数组数据的操作,则传入的数组中的数据就会依照函数的操作来改变。因此,对于数组来说,没有引用型和非引用型之分,可以理解为只要数组作为参数,就都是引用型的。
说明:其实上一段话说得一点儿都不准确,工作中如果这么理解多半会出事,但是用来应对考研数据结构足够了,且容易理解。具体错在哪里了?有兴趣的同学可以去查查关于数组作为参数传入函数的到底是什么的相关资料。工作有工作的方法,应对考试有应对考试的方法,这一点大家要注意。
(2)关于参数引用型的其他例子
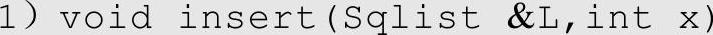

讲解:L是个结构体类型(Sqlist型),data[]数组是它的一个分量,属于Sqlist的一部分,data改变就是L自身改变,使用函数insert()的目的是在data[]数组中插入元素,使data[]数组内容改变,L也随之改变,因此传入L要用引用型。
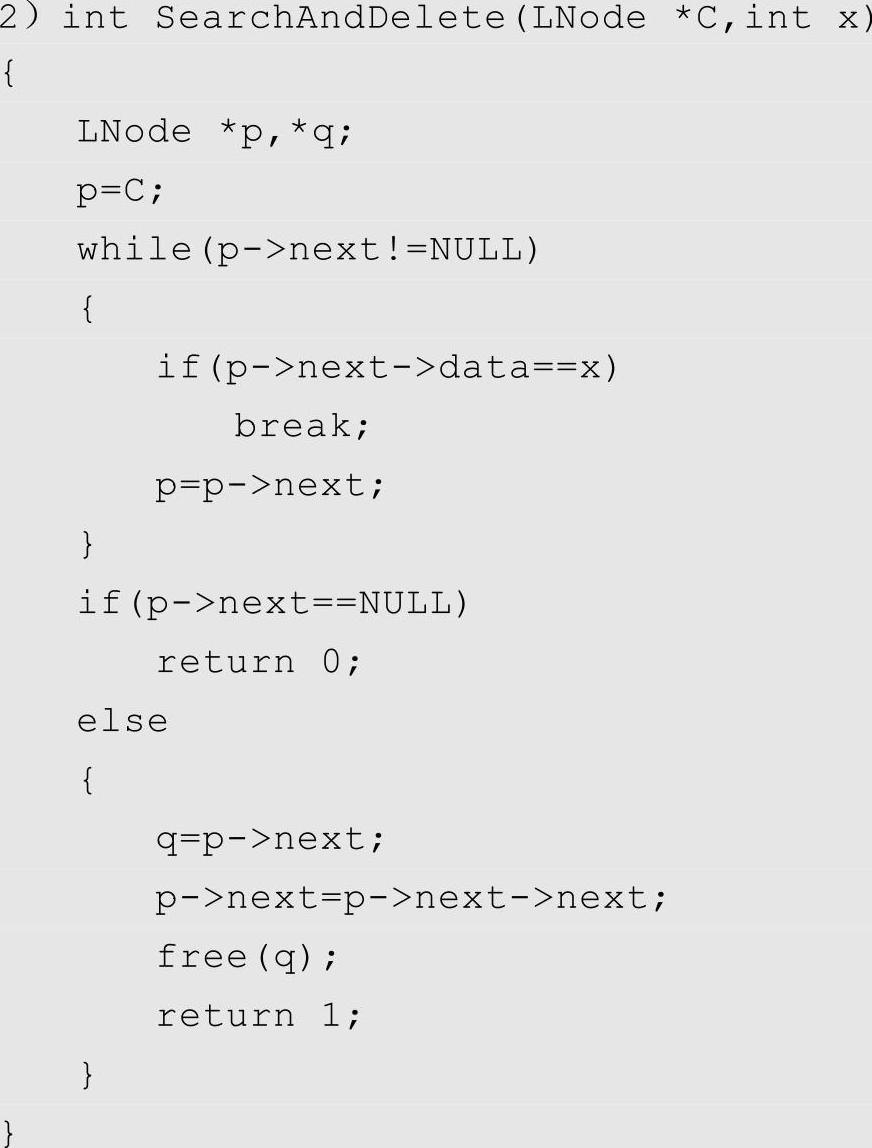
讲解:C是一指向一个链表表头的指针,注意仅仅是个指针,和1)中的L不一样,它不代表整个链表,函数SearchAndDelete()可能删除被操作的链表中的除C所指结点(头结点不含链表元素信息)以外的所有结点,导致链表相关指针改变,但是C指针自己不变,因此这里传入C的时候不需要用引用型。
很多同学对这里的疑问在于,误认为C的地位等同于1)中L的地位,1)中传入的是L这个结构体类型变量整体,L的任何一部分改变都可以看作L自身的改变,需要引用型;而C只是指向一个链表表头的指针,整个链表无法像L一样作为整体传入函数中,C自身不需要改变,改变的是当前被操作链表的其他部分,因此C不用引用型,在函数中也看不到似C自身改变的直接操作语句。


讲解:明白了第二个例子,这个就容易理解了,将A、B两个链表合并(merge)成一个,此时肯定需要得到一个指向结果链表的指针,就是参数C。C指针在传入时可能是一个空指针,经过函数操作之后它指向结果链表表头结点,显然C自身发生了改变需要用引用型;很容易找到使C发生改变的直接操作语句C=A;,A、B两指针显然没有改变的必要,因此它们不需要用引用型。
(3)有返回值的函数
定义一个函数:

在这个定义中可以看到,有一个int在函数名的前边,这个int是指函数返回值是int型。如果没有返回值,则定义函数的时候用void,前边讲过的函数中已经有所体现。返回值常常用来作为判断函数执行状态(完成还是出错)的标记,或者是一个计算的结果。这里顺便用一个具体例子再说明一下#define和typedef在函数定义中的应用以及在考研中这种方法到底可不可取,一些教材中出现过类似于下面这样的函数:
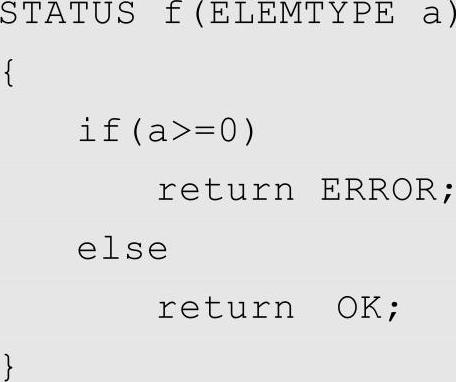
对于一些跨考的同学来说,遇见这个函数就麻烦了,不清楚STATUS、ELEMTYPE、ERROR、OK指的是什么,其实函数的编写者在离这个函数很远的地方已事先写了下述语句:

因此函数f()可以还原为:

上面这种写法就清楚多了。之所以有如上写法,原因有两个:一个是自己另起的类型名或者常量名都有实际的意义,STATUS代表状态,OK代表程序执行成功,ERROR代表出错,这样代码写得就更人性化;另一个是在一个大工程中,对于其中的一个变量,在整个工程中都已经用int型定义过了,但是工程如果要求修改,将所有int型换成long型,如果事先给int型起个新名字为ELEMTYPE,则在整个工程中凡是类似于intx;的语句都写成ELEMTYPE x;,此时只需将typedef int ELEMTYPE这一句中的int换成long即可实现全局的数据类型替换,这就是typedef的意义所在(#define也能达到类似的目的)。显然,上述这些对考研答卷的实际意义并不大。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。




