HyperStudy导向式架构由Study setup、DOE study、Approximation、Optimization study和Stochastic study五个模块构成,如图8-1所示。每完成一步,流程树将使用绿色的勾号标识,并引导用户进入下一步,当模块内所有步骤前均打上绿色勾号时,表明该模块的研究工作完成。
HyperStudy界面中各模块的功能及工作流程描述如下。
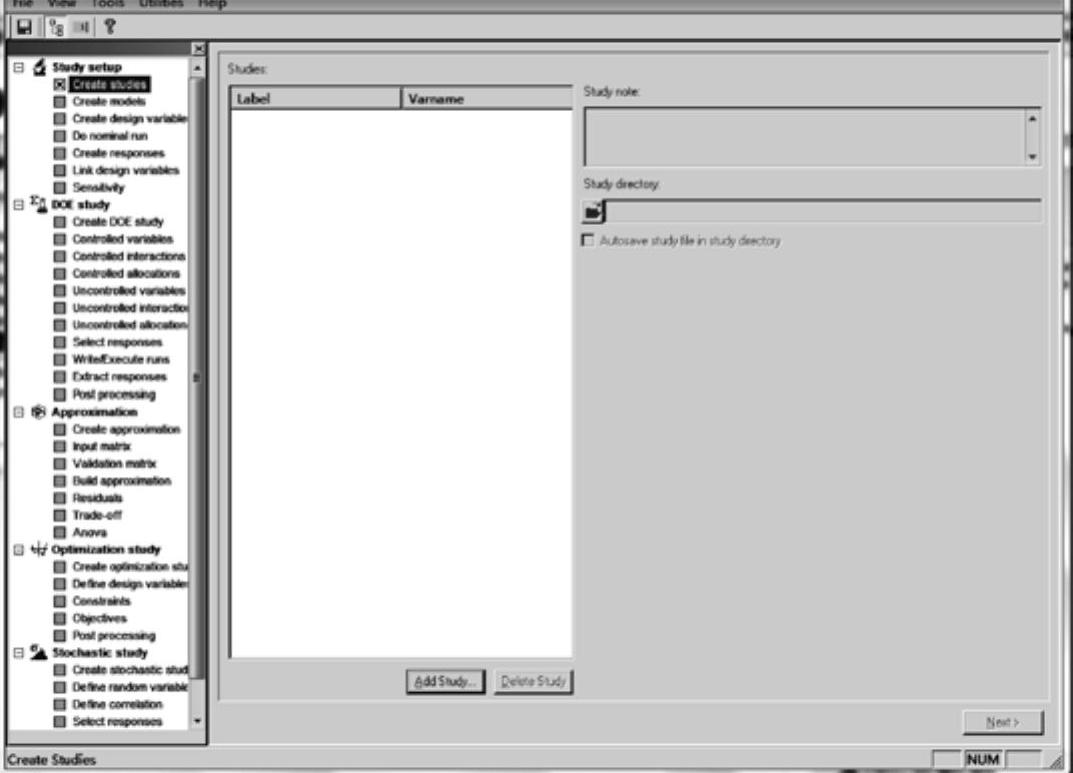
图8-1 HyperStudy用户界面及导向式架构
1.定义模型
Study setup模块用于定义研究的模型,DOE study、Optimization study与Stochastic study模块的研究均建立在该模块定义的模型之上。因此,不管后续的研究类型是什么,首先需要完成模型定义。Study setup模块由以下步骤组成。
● Create studies:创建研究任务。
● Create models:创建研究模型。
● Create design variables:创建设计变量。
● Do nominal run:进行模型的初始计算。
● Create responses:根据初始计算结果创建响应。
● Link design variables:建立设计变量间关系式。
● Sensitivity:定义响应的灵敏度,这些灵敏度(一般为解析灵敏度)将取代HyperStudy使用有限差分方法计算的灵敏度,进行系统优化研究(如SQP优化算法)。
图8-2描述了Study setup模块的工作流程。
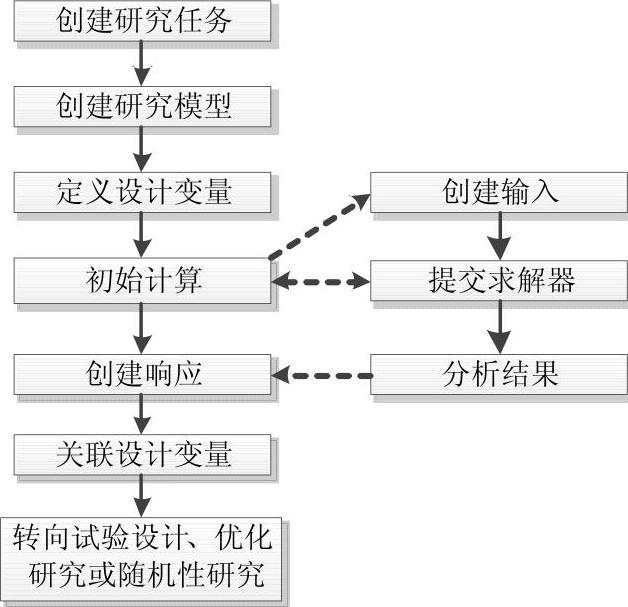
图8-2 Study setup模块的工作流程
在HyperStudy中,多体系统模型设置可通过以下两种方法实现。
(1)Template:使用HyperStudy模板文件。使用HyperStudy的Create Template工具根据ASCII格式的模型文件创建模板文件,然后Templex工具使用设计变量替换模板文件中的数值,并保存为求解器输入文件。
(2)MotionView:使用MotionView MDL数据文件,此时HyperStudy必须从MotionView界面启动,并且在研究过程中MotionView要保持打开状态。通过MDL模型树查找并定义设计变量。MotionView使用设计变量替换MDL模型中的数值并输出求解器输入文件,这里支持的求解器有MotionSolve、Adams、Simpack、DADS、Abaqus、NASTRAN等。图8-3描述了使用Template和MotionView方式创建研究模型的流程。表8-1描述了MotionView MDL数据文件中可用于定义设计变量的参数。
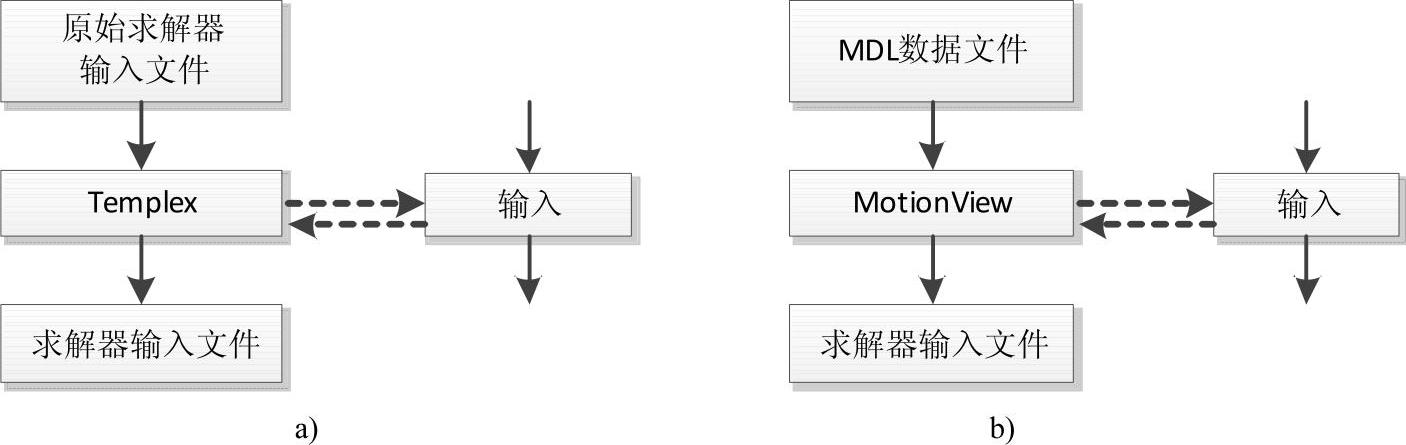
图8-3 求解器输入文件创建流程
a)使用Template b)使用MotionView
表8-1 MotionView MDL数据文件中可用于定义设计变量的参数
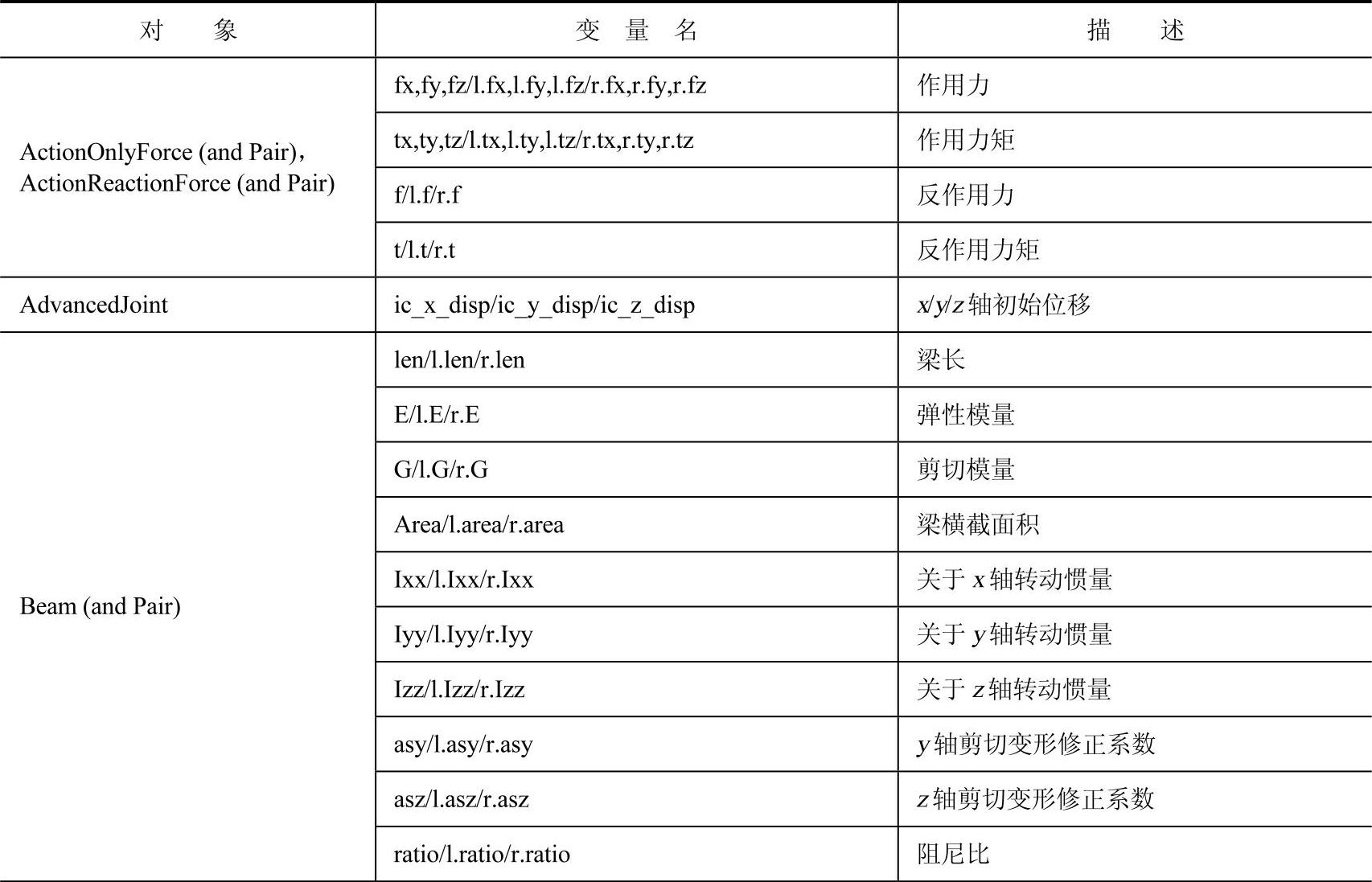
(续)
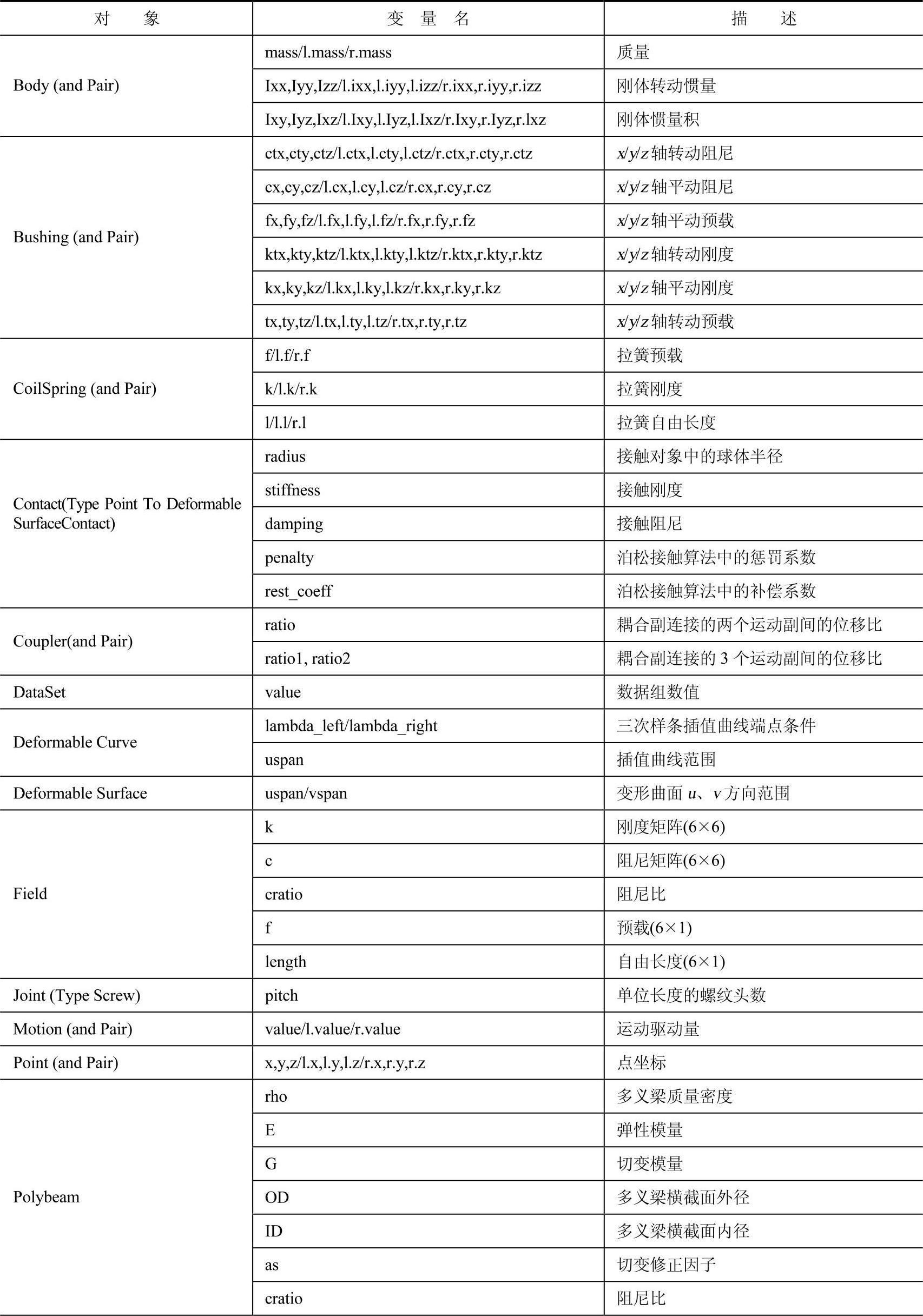
(续)

注:表中l.表示成对对象中,左侧对象的参数。
2.DOE研究
DOE study模块用于模型设计变量间相互作用及设计变量对系统性能影响的研究。该模块由以下步骤组成。
● Create DOE study:创建DOE研究模型。
● Controlled variables:定义可控设计变量。
● Controlled interactions:定义是否计算可控设计变量间的交互作用。
● Controlled allocations:定义可控设计变量的试验设计矩阵。
● Uncontrolled variables:定义不可控设计变量。
● Uncontrolled interactions:定义是否计算不可控设计变量间的交互作用。
● Uncontrolled allocations:定义不可控设计变量的试验设计矩阵。
● Select responses:选择响应。(https://www.daowen.com)
● Write/Execute runs:试验设计计算。
● Extract responses:提取响应结果。
● Post processing:试验设计后处理。
图8-4描述了使用求解器进行试验设计的工作流程。
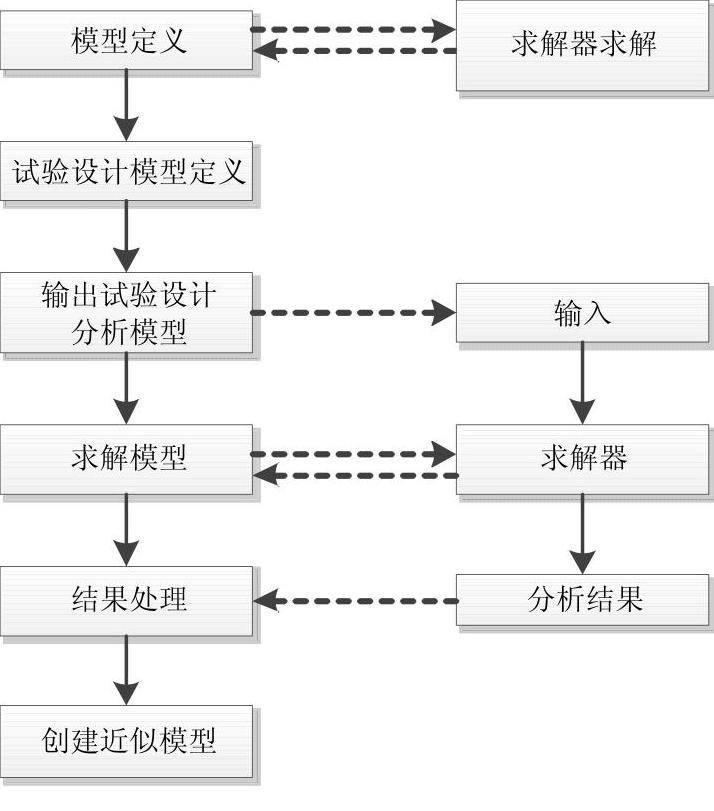
图8-4 HyperStudy试验设计的工作流程
3.近似模型
近似模型可根据DOE和随机性研究结果创建。该模块由以下步骤组成。
● Create approximation:创建近似模型的数学模型。
● Input matrix:导入设计矩阵及相关结果。
● Validation matrix:导入验证矩阵及相关结果。
● Build approximation:构建近似模型。
● Residuals:残差对比。
● Trade-off:查看近似结果并进行参数调整。
● Anova:方差分析。
4.优化研究
Optimization study模块可通过精确的求解器分析或近似响应面进行优化研究。该模块由以下步骤组成。
● Create optimization study:创建优化研究模型。
● Define design variables:定义设计变量。
● Constraints:定义约束。
● Objectives:定义目标函数。
● Post processing:优化结果后处理。
图8-5描述了HyperStudy优化研究的工作流程。
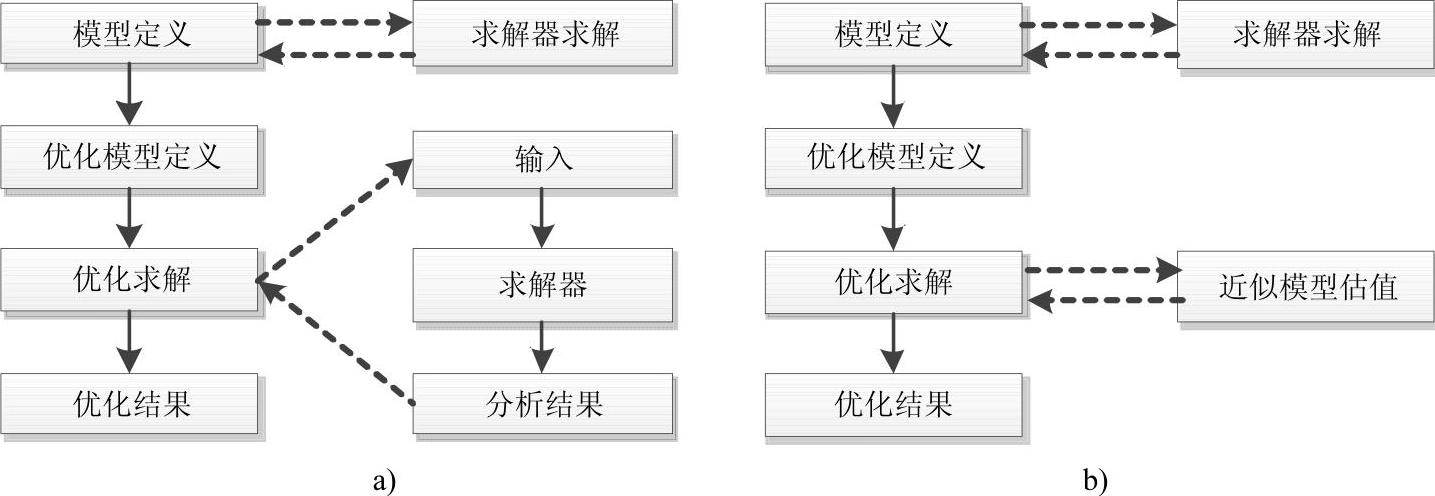
图8-5 HyperStudy优化研究的工作流程
a)使用求解器 b)使用近似响应面
5.随机性研究
Stochastic study模块可通过精确的求解器分析或近似响应面进行优化研究。该模块由以下步骤组成。
● Create stochastic study:创建随机性研究模型。
● Define random variables:定义随机变量。
● Define correlation:定义随机变量间的相互关系。
● Select responses:选择响应。
● Write/Execute runs:求解模型。
● Post processing:随机性研究结果后处理。
图8-6描述了HyperStudy随机性研究的工作流程。
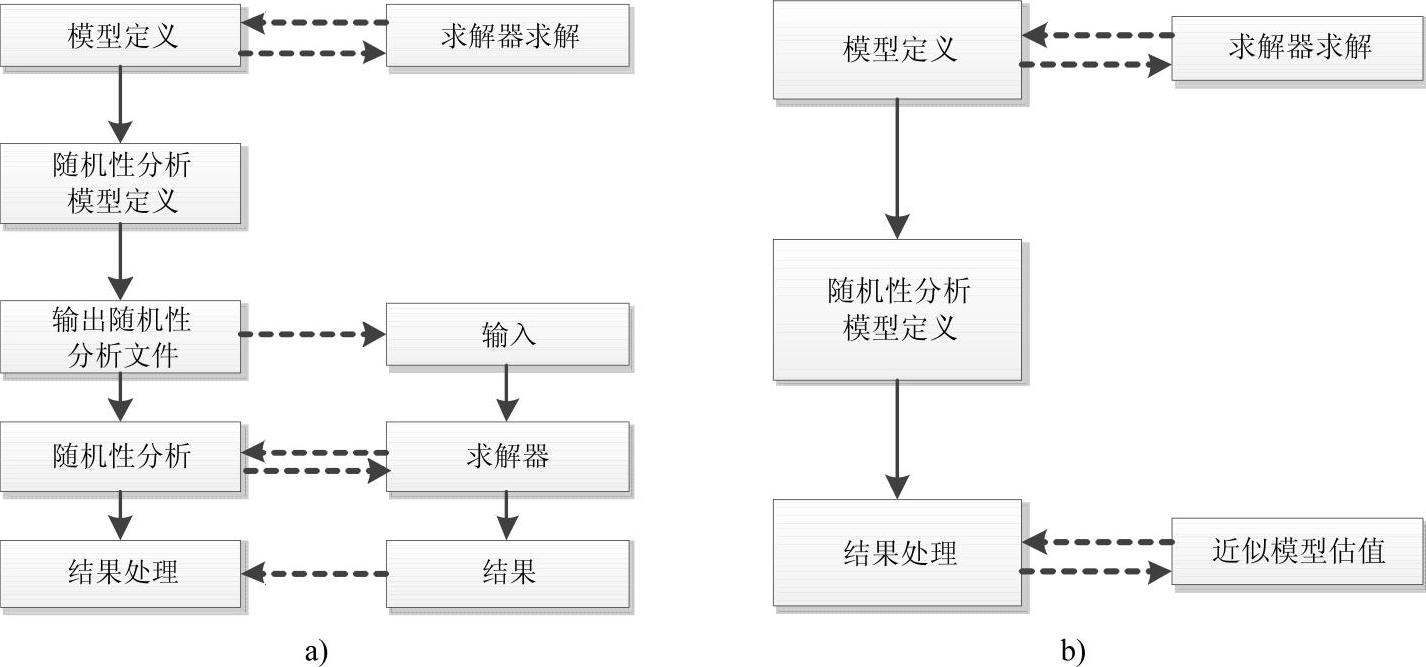
图8-6 HyperStudy随机性研究的工作流程
a)使用求解器 b)使用近似响应面
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。



