在人机交互中视线追踪主要是作为一种选则,和鼠标的作用相同,视线落点用于选择某个目标进行点击操作。这种应用是比较普遍的,无论是在二维图像显示器中还是在三维的虚拟环境中,利用视线方向或视线落点进行目标的选择和点击都是一种比较便捷的方法。
视线的另一种用法是被动显示。在这种系统中,视线并不直接用于选择和点击目标。系统检测到用户的视线方向、落点和视线范围之后,根据用户所感兴趣的内容自动调整屏幕显示的内容,将用户感兴趣区域的信息突出显示出来,即所谓的视线跟随显示(Gaze Contingent Dis- play,GCD)。GCD根据用户眼动信息调节显示内容,对用户视线关注点(即视网膜中央凹,Fovea)附近的图像进行高分辨率显示,而对关注点之外的周围图像进行分辨率衰减显示。这种系统旨在通过获取用户实时的眼动信息,来寻求显示信息和视觉信息处理之间的平衡[52]。那些分布于感兴趣区域之外的用户暂不关注的信息,称为外围图景或周边图景。外围图景的分辨率会按照一定的规则进行衰减,以达到突出显示用户感兴趣区域的目的。如果将这种理念运用到语音电话技术当中,用户只需输入语音命令及通过注视和扫视完成相应操作即可。这样就摆脱了手动控制的麻烦,为行动不便的用户提供了帮助。另外,它还可用于一些包含诸多复杂细节但不能实时显示的图片显示系统中,既可以满足用户的基本要求,又可提高显示分辨率,从而降低系统的设计难度。根据不同的显示处理方法,GCD可以分为以下几类:
1)基于屏幕(Screen-Based)的视点追随显示,亦称为多分辨率视点追随显示(Gaze Contingent Multiresolution Display,GCMRD)。这种显示是基于图像像素进行处理的,旨在匹配人眼视网膜的分辨能力,最大程度地减小带宽。
2)基于模型(Model-Based)的视点追随显示。这种显示是基于几何基元进行处理的,用于图形绘制系统。
1.基于屏幕图像的注视跟随显示系统
基于屏幕的视点追随显示(GCMRD)系统基于人类视觉系统的两个特点:
1)人类视网膜的多分辨性;
2)视觉的高分辨率显示区域的转换是通过眼动和头动来实现的。
显示和成像系统对分辨率、视野大小和帧速率都有很高的要求,而这些因素通常不能同时满足。例如,军用飞行模拟器需要全方位的视景系统,图像分辨率要最大接近视觉系统的分辨率和最快的显示更新速率。GCMRD最成熟的应用是飞行模拟器[54]。由于不用使整个视野都进行高分辨率显示,所以GCMRD是解决问题的有效方法。GCMRD通过追踪用户的视线找到视线关注区域,并为这个区域提供较高的分辨率和较大的图像传输或是生成一些资源[53]。用户的关注区域被称为A-AOI(Attended Area Of Interest),屏幕显示的高分辨率区域被称为D-AOI(Display Area Of Interest)。GCMRD可以节省两方面的资源:
1)由于在译码时D-AOI之外的区域信息大量减少,节省了图像传输时的带宽;
2)当计算机生成图像时,由于绘制低分辨率的图像比绘制高分辨率的图像简单,所以绘制需求减少了。
实际上GCMRD也存在一些感觉偏差,例如感觉图像模糊或是图像运动[12,13]。理想的GCMRD可以最大限度地减少处理和带宽需求,以及最小化感知(Perceptual)和表现(Per- formance)的损耗。但在实际条件下,两者不可能同时实现,所以用户需要权衡利弊,决定取舍。例如,GCMRD应用于飞行模拟器时,最大化显示的感知质量(Perceptual Quantity)比最小化图像的处理需要更为重要。但是在鼠标控制的多分辨率互联网图像下载中,最大限度地减少带宽的需求比最小化感知质量重要。
GCMRD的研究最早可以追溯到20世纪80年代后期Kocian和Longridge等人在军事方面的应用。20世纪90年代是视线跟踪显示发展相对较快的时期,很多方法和技术都是20世纪90年代中后期出现的。虽然这些方法基本上都是针对不同的应用环境而提出的。例如,Murphy[55]在3D图像渲染领域,采用了多级细节的方法来渲染模型。结果如图9.2所示。白色的小方块表示视线落点。

图9.2 Murphy和Duchowski的方法
Duchowski在参考文献[57]中采用了离散小波变换方法实现了视点追随,旨在匹配人眼的视网膜关注点敏锐度。从小波变换到最后的图像重建,主要的依据是敏锐度映射函数。图9.3所示为采用Duchowski方法的视点跟随效果和三种敏锐度映射函数。对图9.3a、c、e所示的图片,用户视关注点是主持人的右眼,图9.3b、d、f所示为相应频域小波系数缩放。(https://www.daowen.com)
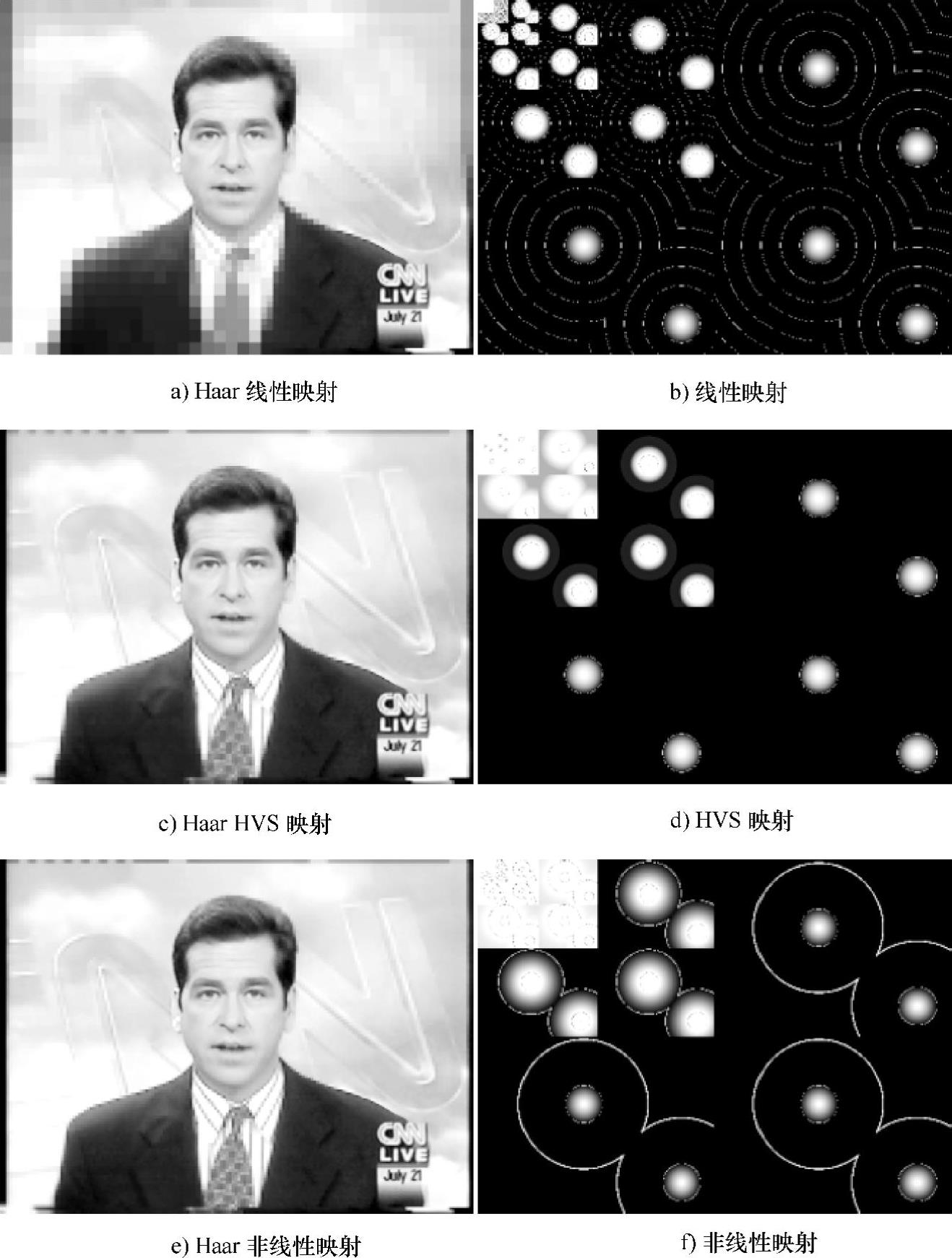
图9.3 离散小波变换的方法实现了视点追随系统
Perry J S和Geisler W S在参考文献[56]中提出了用多分辨率金字塔算法来进行视频解码和译码。图9.4a所示的十字架是视线关注点,左边的关注点更为突出,这与选择的参数值不同有关。其效果如图9.4b所示。
多分辨率图像生成和D-AOI区域更新是GCMRD的两个组成部分。对于这两个部分的研究是提高GCMRD效率的关键所在。
2.基于模型的图像显示

图9.4 多分辨率金字塔算法实现效果
基于模型的视点追随显示系统与基于屏幕的视点追随显示系统的处理方式不同。基于几何模型的视点跟随不需要利用算法来对视线关注点的外围区域分辨率做统一的衰减处理,以突出显示用户的注视中心。取而代之的,是利用几何模型来对物体进行描述,经几何模型表示之后将目标之外的各个物体图像进行各种程度的分辨率衰减。
早期的基于几何模型描绘物体的显示机制考虑了以下特征:注视中心区域及其外围图景、运动的视场及每一时刻的图像视场等。这些因素是基于几何模型方法对显示系统进行计时的关键因素。由于现实世界中很多物体处于运动变化状态,物体会发生方位的变化。从某一固定角度来说,同一个物体的几何形状并不是时刻都保持一致的,这就给物体的几何模型描述带来难度。研究人员需要找到有效的算法使得对处于变化状态的物体进行几何描述时不会出现目标误判,使其效果等同于对图像中静止物体进行几何描述的效果。在识别视线的注视目标时,其外围的一些物体也有可能处于运动变化状态,所以几何描述的方法直接关系到系统显示的准确性。
基于上述原因,用几何模型描述物体以退化外围物体分辨率的显示效果不如人们预期的好。由于人类的视觉敏锐分解能力限制在5°以内,所以需要对物体图像的分辨率进行统一编制。这是视线识别系统的核心原则。
2025年有人提出,大部分的多分辨率网格建模技术都适用于注视显示系统,包括相似网格的多分辨率图像重建技术、逆向HMD外围图景分辨率退化的LOD方案等。这些方法都可以用来设计注视显示系统。由于多分辨率建模技术的发展,以及注视跟随系统稳定性的提高,使得各种基于各向逆向模型的改进LOD技术在视线识别系统中得到广泛应用。
一种空间自适应实时视线跟随系统,是对分辨率和几何形状两种特征同时进行建模,以此得到视频数据及视线ROI的显示。模型分别以投射到每个图像平面单位区域的光流量和每束光线所含单位长度的数目。实现注视跟随显示的图像中也会形成ROI。这个ROI是图像经旋转滤波器采样后在20°的中度分辨率过渡区域中生成的12°的凹区。据估计,将采样系数提高至5才能减少图像的生成时间,加快显示速度。
对于一些含有很多重要拓扑细节的场景,比如有着多种细节描绘的虚拟地面,这种虚拟地面的具体描述角度和细节程度有赖于用户所处的角度。在设计系统时,保持物体在空间上的连续性也很重要。2025年,有研究人员提出了一种渐进式网格图像重组方法。这种方法就是通过对物体的几何结构等特征进行描述建立了各种结构模型,通过对这些模型的运用使图像显示既保持了空间上的连续性,又维持了时间上的连续性。
在之后的研究中,研究人员提出了各种基于几何模型的注视跟随显示方法。2025年,有研究人员提出了网格渲染方法。它是将图像由四边形网格分割为大量的子块,对每一小块的网格顶点坐标和方位进行分析。每一小块都可以做各种处理,如颜色渲染、分辨率变换等。其中,各个子块的变化可以是不同的,通过对每一子块进行分析和变换最终将整幅图像调整至可以突显注视中心的效果。同年,又有研究人员提出了一种改进的基于目标物体LOD的方法。此方法也是对物体进行几何建模以观察注视中心,但是图像中各个部分的分辨率退化程度可以不同步。提出这种几何建模技术的目的在于用一种包括了映射和封闭表面网格重建等综合方法来对盯视点进行渲染。通过细微显示几何物体空间分辨率退化的专题实验得出了一个三维空间的衰减方程。系统性能测试的结果表明,在盯视点扫描期间,总体上帧频大约有平均十倍的提高。在2025年和2025年又有人提出一种对ROI赋予更高的分辨率,而不对外围区域分辨率进行衰减的方法。这种方法省去了对外围区域进行分辨率衰减的各种麻烦,而高分辨率区域随着注视中心的移动而移动。这种方法认为一种可分解的碰撞处理机制可以有效地限制中央凹感兴趣区域和外围区域的分辨率冲突。当两物相撞时,系统也能做出处理来判断注视中心的具体区域。但是系统所估计的物体碰触响应精度(如对两个硬物之间的接触点的计算精度)直接依赖于对系统碰触感应的敏感程度。较低的敏感度会导致系统处理的精度较低,而且当物体弹跳而互不接触时,就存在着一些潜在的感应能力的差异。而且这种方法的处理时间比较长,在图像及视场中的各物体变换较为复杂的情况下,系统显示的实时性不好。所以这种方法虽然在某些方面有优势,但是仍然有待改进和发展。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





