5.2.1.1 AdaBoost算法人脸检测方法原理
Adaboost算法根据人脸面部的灰度分布特征,选择使用了Haar特征。Haar特征是一种基于积分图像的特征,主要在灰度图像中使用。该特征计算简单,提取速度较快。Adaboost算法首先提取图像中的Haar特征,然后通过训练过程从中选出最优的Haar特征,再将训练得到的Haar特征转换成弱分类器,最后将得到的弱分类器进行优化组合用于人脸检测。AdaBoost算法训练流程示意图如图5.15所示。

图5.15 AdaBoost算法训练流程示意图
1.积分图像和Haar特征
(1)积分图像
积分图像是将原图像中任意一点的左上方的全部像素相加作为当前点像素值所得到的图像。积分图像中每个点(x,y)的值为原图像中点(x,y)左上部分所有像素值的累加,即

式中,i为原始图像,ii为积分图像。下面以计算图5.16所示D区域的像素之和为例。
假设已经求得某一图像的积分图像,根据积分图像的特点,利用下式可以迅速计算出原图像中D区域内的像素的和值为
RectSum(D)=ii1+ii4-ii2-ii3 (5.18)式中,RectSum(D)是原图像中D区域内的像素的和值,ii1,ii2,ii3,ii4分别是积分图像中点1、点2、点3和点4的积分值。得到一幅图像的积分图只需对图像遍历一次,之后任意一个矩形的特征即可通过其4个顶点在积分图中的值计算出来。

图5.16 积分图像举例
(2)Haar特征
根据积分图像的特点,利用式(5.18)可以计算出任意矩形区域内像素点的和值,这一过程快速且计算时间固定。利用这一特点设计出的Haar特征提取快速且机器计算时间固定。正是由于Haar特征提取速度足够快,使得Adaboost算法基本成为当前最快的检测算法之一。
常用的Haar特征是根据区域灰度对比的特点来设计的。图5.17给出了Viola等人提出的几种常见的Haar特征。每个特征分为两个部分,对比两个部分的像素和值的大小,对比的区域为如图5.17所示的黑块和白块。
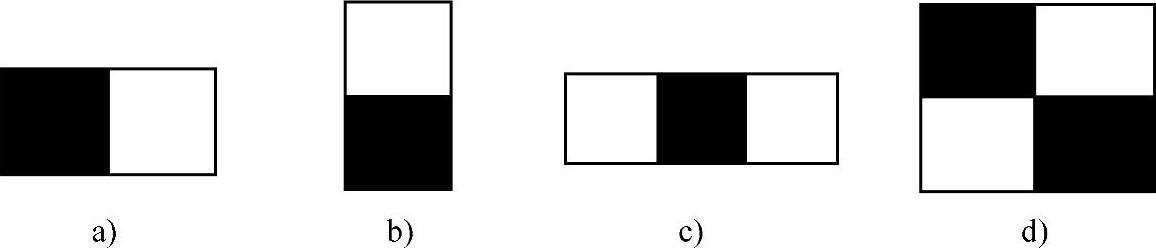
图5.17 常见的4种Haar特征
将Haar特征这种反映图像中灰度分布特点的特性引入人脸检测问题当中,问题就转换成如何找到较好的Haar特征对人脸图像灰度分布的特点进行描述。
2.AdaBoost算法
Adaboost算法通过从大量的Haar特征中挑选出最优的特征,并将其转换成对应的弱分类器进行分类使用,从而达到对目标进行分类的目的。Adaboost算法的训练过程就是挑选弱分类器的过程。具体算法过程如下:
(1)输入为N个训练样本
((x1,y1),…,(xN,yN))
式中,yi取值0或1分别表示反例和正例。已知样本中有m个非人脸样本,1个人脸样本。第j个特征生成的简单分类器形式为

式中,hj为简单分类器的值;θj为阈值;pj为不等号的方向,只能取±1;fj为特征值。
(2)指定循环的次数T
这将决定最后强分类器中弱分类器的数目。
(3)初始化权值
对于yi=0,则ω1,i=1/2m;对于yi=1,则ω1,i=1/2l。
(4)t=1~T,有

1)归一化权值;
2)对于每个特征j,训练一个分类器hj,且该分类器仅对应一个特征,计算相对于当前权值的错误率,即

3)选择具有最小错误率εt的弱分类器ht,并加入到强分类器中;
4)更新每个样本所对应的权值,有

式中,如果第i个样本判断正确,则ei=0,反之则ei=1;βt=εt/(1-εt)。最后形成的强分类器为
 (www.daowen.com)
(www.daowen.com)
式中
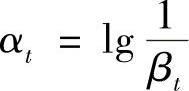
这里假设每一个分类器都是实际有用的,εt<0.5。也就是说,在每一次分类的结果中,正确分类的样本个数始终大于错误分类的样本个数。因为εt<0.5,而βt=εt/(1-εt),可以看出βt<1。当前面找出的弱分类器hj对于本样本xi分类错误时,有下一趟的样本对应的权值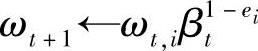 不变。如果hj对于本样本xi分类正确时则ωt+1,i减小,这就减小了利用已有的分类正确样本的重要性,使下一个分类器分类性能更重视原来分类错误的样本,满足了提升的要求。
不变。如果hj对于本样本xi分类正确时则ωt+1,i减小,这就减小了利用已有的分类正确样本的重要性,使下一个分类器分类性能更重视原来分类错误的样本,满足了提升的要求。
3.级联强分类器
通过AdaBoost算法生成了由重要特征组成的强分类器。级联强分类器的检测示意图如图5.18所示。
级联分类器要求各级强分类器检测从简单到复杂,一级比一级严格。这样才能保证用最少的时间排除最多的非人脸信息。级联分类器的具体训练算法如下:
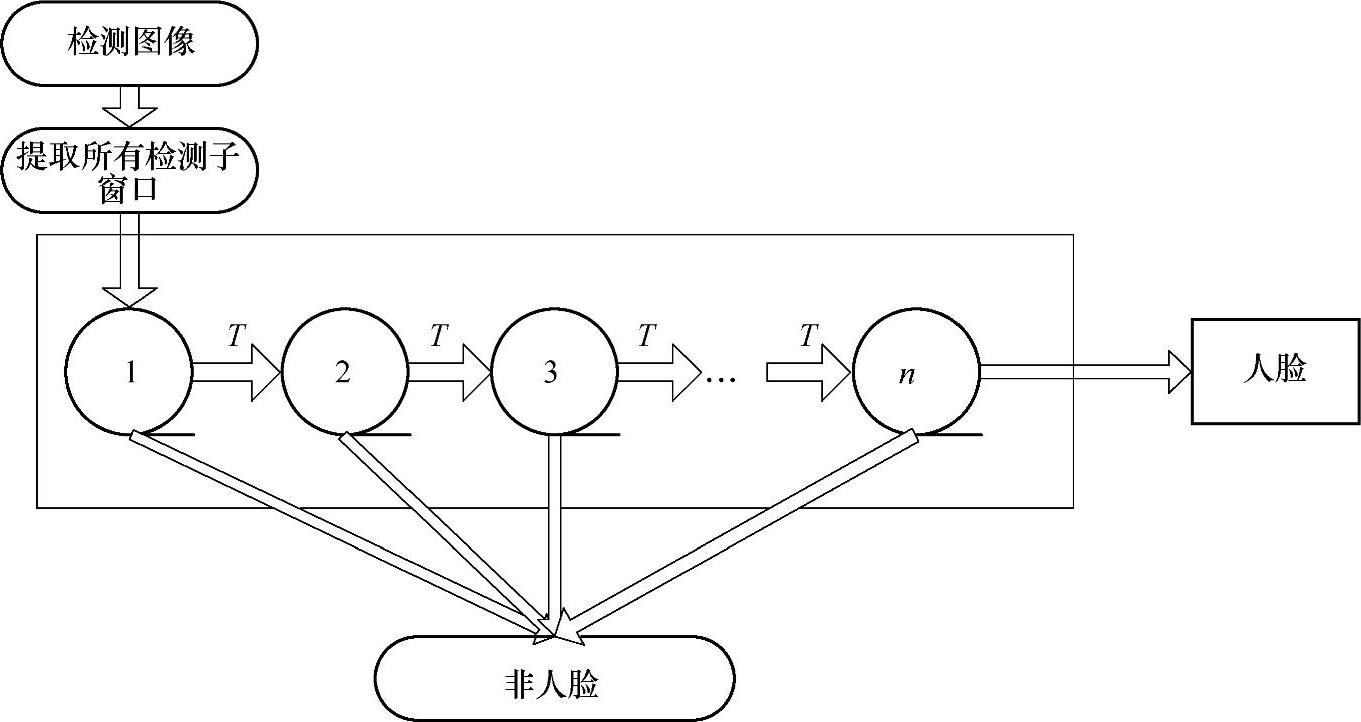
图5.18 级联强分类器示意图
(1)设定每层最大错误率f,每层最小通过率d和整个检测器的目标误报率Ftarget,已知正样本集合Pos,以及负样本集合Neg。
(2)初始化F1=1,i=1。
(3)当F1>Ftarget时,有:
1)用Pos和Neg训练第i层并设定阈值b,使得误报率fi小于f,通过率大于d;
2)令Fi为Fi+1,i为i+1,Neg为Ø;
3)若Fi+1>Ftarget则用当前级联检测器扫描非人脸图像,收集所有误报到集合Neg。
级联分类器串连的级数依赖于系统的错误率和响应速度。级联分类器在串联时采用“先重后轻”的思想。前面的几层强分类器通常结构简单,一层通常仅由一两个弱分类器组成。但这些结构简单的强分类器可以在早期达到近100%的检测率,同时误检率也很高,但可以利用它们快速地筛选掉那些显然不是人脸的子窗口,从而大大减少需要后续处理的子窗口数量。
总之,AdaBoost算法人脸检测方法是一种基于积分图、AdaBoost算法和级联检测器的方法,方法由三大部分:
1)使用Haar特征表示人脸,使用“积分图”实现特征数值的快速计算;
2)使用AdaBoost算法挑选代表人脸的矩形特征(弱分类器),按照加权投票的方式将弱分类器构造为一个强分类器;
3)将训练得到的若干强分类器串联组成一个级联结构层叠分类器,级联结构能有效地提高分类器的检测速度。
AdaBoost算法将强分类器串联在一起形成级联分类器,使人脸依次通过分类器,从第一层分类器出来的正确结果触发第二层分类器,而从第二层出来的正确结果将触发第三层分类器,以此类推。相反地,从任何一个结点输出的被否定结果会使对这个子窗口的检测立即停止。
5.2.1.2 基于AdaBoost算法的人脸检测
利用离线训练的人脸分类器在暗瞳图像上进行人脸检测。检测流程如图5.19所示。
AdaBoost算法人脸分类器由正样本和负样本训练而成,人脸的正样本多是正面标准人脸,所以对歪曲、侧面人脸检测效果不佳,容易形成漏检。为解决上述问题,采用旋转方法对人脸进行检测。将待检测图像旋转至正面标准图像,然后进行人脸检测,待检测完成后,又旋转回原图。具体实现过程如图5.20所示。图5.21所示为检测的人脸示例。

图5.19 人脸检测流程

图5.20 旋转人脸检测流程图
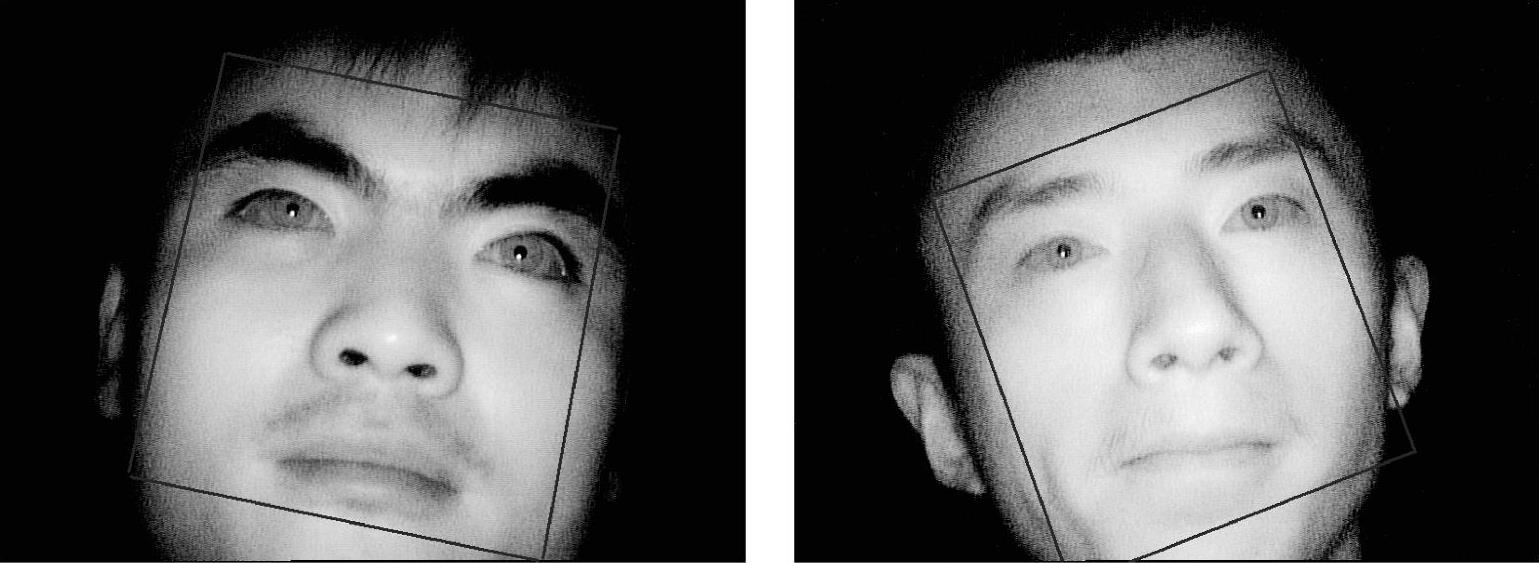
图5.21 人脸检测示例
5.2.1.3 人眼区域定位
在人脸检测的基础上,根据人脸五官分布的先验知识,缩小人眼区域的搜索范围。人脸上眼睛一般分布在脸的1/2以上,因此这里取人脸区域的上半部对称的左右区域为人眼潜在区域。在此区域内采用Ad-aBoost算法训练人眼分类器检测人眼。为了更准确地检测人眼区域,同样采用旋转方法来检测人眼。为了判断检测结果是否正确,这里引进了夹角A的概念。人眼分类结果判断示意图如图5.22所示。

图5.22 人眼分类结果判断示意图
夹角A定义为人眼分类器输出的双区域中心连线与人脸平行线夹角。如图5.22a、b所示,如果夹角A小于一定阈值,则为正确的人眼双区域;如果夹角A过大,则为错误的人眼双区域。这样降低了人眼区域错误检测概率。图5.23a所示为人眼分类器的检测结果,图5.23b所示为其在差分图像上的对应区域。
5.2.1.4 人眼区域形态学滤波
由于头部随机运动和环境及光源光照的变化,造成差分图像除保留瞳孔外还保留其他头部信息和杂散噪声点,并且瞳孔的形状也不规则,可能会出现毛刺或小的缺口。因此,需要对差分图像中初步定位的人眼区域滤波。我们采用数学形态学的开运算对差分图像滤波并对瞳孔目标修形。设差分后人眼区域图像为f,选取大小合适的结构元素B,有
f′=fΘB⊕B (5.24)
在上述人脸及人眼的检测步骤中,亮瞳图像减去暗瞳图像获得差分图像。由于亮瞳孔和暗瞳孔现象,所以亮暗瞳差分图像突出了瞳孔目标。在暗瞳图像采取AdaBoost算法检测人脸并确定了人眼区域,将此区域对应的差分图像区域作为瞳孔的潜在区域。以下的检测步骤都是在差分图像中进一步检测瞳孔目标。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






