2017年Hoffman等人[21]提出一个两阶段语义分割方法。第一阶段通过图像转换模型F,将源域S中的图像转换为与目标域T中图像表观相似的图像;第二阶段使用第一阶段转换后的源域F(S)中的图像训练自适应分割网络M。其中,F(S)具有和S相同的标注LS。两个网络可以采用顺序学习的方式进行训练,如图8.6(a)所示。在顺序学习中,一旦学习得到图像转换模型F,它就固定了,不能通过自适应分割网络M的反馈来进一步调整其参数。为了解决这一问题,Li等人[22]于2019年提出了双向学习框架,用于无监督域适应语义分割,如图8.6(b)所示。该框架交替优化图像转换网络F和分割自适应网络M,以减少源域和目标域之间的域偏移,最终整个网络形成闭环学习。
图8.6 域适应语义分割中的顺序学习与双向学习[22]
(a)顺序学习;(b)双向学习
1.双向学习
前向方向(即F→M)的学习类似于图8.6(a)中的顺序学习。首先使用源域S和目标域T的图像数据训练图像转换模型F,获得转换后的源域S′=F(S),S′具有和S相同的像素级类别标签LS。然后利用S′和LS来训练自适应分割模型M,其相应的损失函数表示为
其中,Ladv是域对抗损失,用来衡量S′和T在自适应分割模型中习得的特征表示分布之间的距离。Lseg是语义分割损失。λadv是平衡系数。
后向方向(即M→F)的学习是为了让更新过的自适应分割模型M能反过来促进图像转换模型F的进一步调整。训练图像转换模型F的损失函数表示为
式中,F-1旨在将目标域图像转换为与源域图像表观相似的图像。T′=F-1(T)是转换后的目标域。生成对抗损失LGAN使得S′和T、S和T′之间的分布差异减少。重构损失Lrecon使得S′和T′分别经过F-1和F后能重新变换回S和T,也就是使得F-1和F在改变图像表观的同时能够保持图像结构信息不变。感知损失Lper保持了S和S′、T和T′之间的语义一致性,这又意味着,一旦学得了理想的自适应分割模型M,即使S和S′之间(或T和T′之间)存在域偏移,S和S′(或T和T′)也应该具有相同的分割结果。λGAN和λrecon是平衡参数。
2.自监督学习
在前向方向中,对目标域中图像进行像素级类别预测后,可以获得较高可信度的部分像素点的伪标签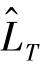 。根据这些伪标签,相应的像素就可以通过分割损失直接与源域数据S对齐。式(8.6)中训练自适应分割模型M的损失函数可以改写为
。根据这些伪标签,相应的像素就可以通过分割损失直接与源域数据S对齐。式(8.6)中训练自适应分割模型M的损失函数可以改写为
其中,Tssl⊂T是具有伪标签的目标域像素点构成的集合。图8.7解释了自监督学习的原理。在步骤一中,当第一次学习自适应分割模型M时,由于源域和目标域的域偏移较大,Tssl是空的,S和T之间的域偏移可以通过式(8.6)中的损失LM1来减小。这一过程对应图8.7(a)。在步骤二中,在目标域数据T中选取与S对齐的像素点以构造子集Tssl,Tssl通过式(8.8)中的的损失LM2来进一步减小域偏移,从而减少了目标域T中需要与源域S对齐的像素点个数。这一过程对应于图8.7(b)。然后通过重复步骤二将未与源域对齐的目标域像素点向源域对齐。
图8.7 双向学习域适应语义分割中的自监督学习过程[22](见彩插)(https://www.daowen.com)
(a)步骤一;(b)步骤二
注:图中的点表示像素点
3.网络结构和损失函数
图8.8为双向学习的域适应语义分割方法的整体网络结构和损失函数。
图8.8 双向学习的域适应语义分割方法的整体网络结构和损失函数[22]
当学习图像转换模型F时,生成对抗损失LGAN和重构损失Lrecon分别定义为
其中,IS和IT分别是来自源域S和目标域T中的图像,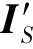 是源域图像IS经过图像转换网络F得到的转换图像,
是源域图像IS经过图像转换网络F得到的转换图像,![]() 是L1范数。DF是域分类器。对于重构损失Lrecon来说,L1范数是为了保持IS与F-1(
是L1范数。DF是域分类器。对于重构损失Lrecon来说,L1范数是为了保持IS与F-1(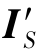 )之间的循环一致性,即使得
)之间的循环一致性,即使得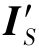 经过F-1后还能变回IS(这里仅列出了两项损失的正向表示,LGAN(S,T′)和Lrecon(T,F(T′))也可以同样定义)。感知损失Lper将图像转换模型和自适应分割模型连接起来,约束IS与
经过F-1后还能变回IS(这里仅列出了两项损失的正向表示,LGAN(S,T′)和Lrecon(T,F(T′))也可以同样定义)。感知损失Lper将图像转换模型和自适应分割模型连接起来,约束IS与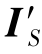 、IS与F-1(
、IS与F-1(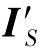 )的语义一致性,定义为
)的语义一致性,定义为
根据对称性可得到Lper(M(T),M(T′))的定义。
在学习自适应分割模型M时,域对抗损失Ladv定义为
对于源域图像IS,分割损失Lseg采用交叉熵损失,定义为
其中,H和W分别是输出像素级分类概率图的高度和宽度;lS是源域图像IS对应的像素级标签图,![]() 表示像素(h,w)的类别标签,C是类别个数,PS是自适应分割模型输出的像素级分类概率图,定义为
表示像素(h,w)的类别标签,C是类别个数,PS是自适应分割模型输出的像素级分类概率图,定义为![]() ,
,![]() 表示像素(h,w)属于类别c的概率。对于目标域图像IT,首先需要为其生成像素级伪标签图
表示像素(h,w)属于类别c的概率。对于目标域图像IT,首先需要为其生成像素级伪标签图![]() 。具体采用最大概率阈值(max probability threshold,MPT)方法选择具有较高置信度的像素。根据自适应分割模型输出的M(IT),
。具体采用最大概率阈值(max probability threshold,MPT)方法选择具有较高置信度的像素。根据自适应分割模型输出的M(IT),![]() 可由
可由![]() 计算得到。由此,对于目标域图像IT,其分割损失Lseg定义为
计算得到。由此,对于目标域图像IT,其分割损失Lseg定义为
其中,![]() 是分割自适应网络M输出的目标域图像IT中像素(h,w)处的类别概率;
是分割自适应网络M输出的目标域图像IT中像素(h,w)处的类别概率;![]() 表示IT中像素(h,w)处的掩码,若像素(h,w)处的预测类别标签得分大于阈值,
表示IT中像素(h,w)处的掩码,若像素(h,w)处的预测类别标签得分大于阈值,![]() 为1,否则为0。
为1,否则为0。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。







