从6.3.1小节的自适应多核学习动作识别方法中,可以看到借助大量丰富且已标注的源域数据进行模型学习并将其迁移至目标域进行分类的策略是有效的。由于动作在语义上呈现多样性,Wang等人[63]提出多语义分组域适应的动作识别方法,将源域数据划分为多个与动作相关的语义组,通过权衡不同概念组,选择与目标域动作最相关的知识进行迁移。该方法使用多个关键字从互联网进行检索,分别在概念层和动作类别层获得带语义信息的源域图像组。由一个概念关键词检索得到的源域图像集合称为一个“概念特性组”,由一个动作类别关键词检索得到的图像集合称为一个“动作特性组”。通过联合优化图像组分类器与组权重,计算不同源域图像组与目标域之间的语义关性,给不同的源域图像组赋予不同的权重。同时充分利用目标域未标注视频来辅助学习目标域分类器,并引入两个正则项进一步增强目标域分类器的泛化能力。
1.多源域适应基本算法
将大量已标注互联网图像数据作为源域,少量未标注用户视频作为目标域。多源域适应的目标是通过权衡这两个域中的知识以习得目标域预测函数ft(·)。使用![]() ,(s=1,…,S)来表示S个源域数据,其中
,(s=1,…,S)来表示S个源域数据,其中![]() 是第s个源域的第i张图片且其标签为
是第s个源域的第i张图片且其标签为![]() 。Dt表示由未标注视频数据
。Dt表示由未标注视频数据![]() ,(1≤i≤Nt)组成的目标域,其中Nt表示目标域中视频的总数。对一个输入视频
,(1≤i≤Nt)组成的目标域,其中Nt表示目标域中视频的总数。对一个输入视频![]() 的动作类别标签计算为
的动作类别标签计算为
其中,![]() )是目标域分类器;
)是目标域分类器;![]() )是第s个源域分类器关于样本
)是第s个源域分类器关于样本![]() 的决策值;αs是第s个源域的权重。
的决策值;αs是第s个源域的权重。
多源域适应方法主要通过以下两个步骤学习目标域分类器。第一步,每个源域图像组上训练针对该图像组语义的预分类器(动作分类器);第二步,学习每个源域的权重,并依据权重将第一步习得的多个源域动作分类器进行融合以获得目标域分类器。在第一步中,S个源域分类器{f 1,…,f S}的优化问题定义为
其中,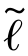 (·,·)为源域分类器f S在源域数据上的损失函数;
(·,·)为源域分类器f S在源域数据上的损失函数;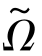 (·)为正则项。在第二步中,目标域分类器ft通过最小化如下目标函数得到
(·)为正则项。在第二步中,目标域分类器ft通过最小化如下目标函数得到
尽管传统的多源域适应方法期望通过从不同域获得知识以降低负迁移的风险,但相比于根据数据来源分配各源域权重,根据源域数据与目标域数据的语义相关性分配权重,将更有利于提高知识迁移的性能。源域中的某个样本集合与目标域越相关,该样本集合所对应的权重越大。因此,源域相关的样本中所包含的知识更容易被迁移到目标域,从而有效避免负迁移的发生。
2.多语义分组
定义与动作相关的概念集合C={C1,C2,…,CG},其中Ci表示第i个概念。使用43(G=43)个概念关键词,其包含了动作相关、物体相关以及场景相关的语义概念。由一个概念关键词检索得到的一组图像集称为概念特性组,表示动作的某一种语义概念。构建多组图像,表示多种与动作相关的语义概念。设![]() ,s∈{1,…,G}表示第s个概念特性图像组,其中
,s∈{1,…,G}表示第s个概念特性图像组,其中![]() 表示第s个概念特性组的第i幅图像;Ns为该组图像数量。对应于每s个概念特性组,使用对应图像集合学习其SVM分类器gs(·)。设
表示第s个概念特性组的第i幅图像;Ns为该组图像数量。对应于每s个概念特性组,使用对应图像集合学习其SVM分类器gs(·)。设![]() 为目标域动作视频,其中
为目标域动作视频,其中![]() 表示第i个目标域视频;Nt为视频数量。
表示第i个目标域视频;Nt为视频数量。
尽管概念特性组能够为提高对动作描述能力提供高层语义信息,但是在实际应用中它们仍然存在如下两个问题:①人工定义的概念在某种程度上存在主观性,并没有考虑到潜在的具有判别性的概念;②概念的个数人为设定,无法预知究竟定义多少概念才能够充分可靠地表示源域中的知识。由此,定义动作关键词(即动作类别),并通过其检索图像,构建动作特性组。Ne是一组动作特性组中图像的个数,一个动作关键词检索到的图像组表示为Xe=![]() ,其中
,其中![]() 为该图像集中第i幅图像。
为该图像集中第i幅图像。
概念特性图像组与事件特性图像组共同组成源域图像组。对于每类动作,使用与该类别对应的源域图像组学习多个组分类器。这些组分类器由G个概念特性组分类器和E个动作特性组分类器构成。下面介绍如何通过联合优化的学习框架,同时学习源域图像组分类器及其权重。
3.多语义分组域适应
设gs(·),s∈{1,…,G}为源域图像组分类器,多语义分组域适应算法的目标是通过联合学习框架,有机融合概念特性组分类器gs(·),s∈{1,…,G}与事件特性组分类器gs(·),s∈{G+1,…,S},学习目标域分类器。
对于目标域视频![]() ,目标域分类器
,目标域分类器![]() 可以定义为
可以定义为
其中,![]() 表示第s个源域图像组分类器;αs表示对应的组权重。
表示第s个源域图像组分类器;αs表示对应的组权重。
由于目标域没有任何标注数据,同时最小化定义在源域数据上的损失函数以及定义在目标域数据上的各正则项:
其中,λL、λD>0以及λP<0为权衡参数。
下面详细介绍式(6.16)中各项含义。
ΩC(ft)是使源域组分类器权重尽量稀疏的正则项,可以降低目标域分类器ft的复杂性,定义为
ΩL(ft)是目标域分类器ft在源域数据上的损失函数,定义为
ΩD(ft)是与标签无关的正则项,用于提高目标域分类器ft的泛化性能,定义为
ΩP(ft)是关于目标域分类器ft的伪损失函数,定义为
其中,![]() 为第i个目标域数据
为第i个目标域数据![]() 的伪标签,通过目标域分类器ft预测得到。尽管目标域没有任何标注数据,但仍然希望通过ΩP(ft)最大化伪标签不同的目标域数据与分割平面的距离。
的伪标签,通过目标域分类器ft预测得到。尽管目标域没有任何标注数据,但仍然希望通过ΩP(ft)最大化伪标签不同的目标域数据与分割平面的距离。
综上,式(6.16)定义的优化问题可以改写为
设![]()
![]() 以及
以及![]() (https://www.daowen.com)
(https://www.daowen.com)
式(6.21)简化为
本部分使用迭代算法来实现式(6.22)中的优化问题。定义![]() 为第m次迭代优化的标函数。第m次迭代使用的伪标签通过计算上一次迭代得到的目标分类器
为第m次迭代优化的标函数。第m次迭代使用的伪标签通过计算上一次迭代得到的目标分类器![]() 得到。多语义分组预适应算法主要包含两个阶段。在第一阶段,G个概念特性组分类器通过G个SVM分类器实现,E个事件特性组分类器则随机生成。在第二阶段,交替优化源域图像组分类器参数W和组权重A。具体迭代过程请见算法6.1。
得到。多语义分组预适应算法主要包含两个阶段。在第一阶段,G个概念特性组分类器通过G个SVM分类器实现,E个事件特性组分类器则随机生成。在第二阶段,交替优化源域图像组分类器参数W和组权重A。具体迭代过程请见算法6.1。
4.数据集
为验证多语义分组域适应在动作识别中的有效性,本部分采用3个公开动作识别数据集:Kodak[60]、YouTube[53]和CCV[64]。
Kodak数据库。这个数据库包含195个用户视频。每个用户视频都隶属6个事件类别(“birthday”“picnic”“parade”“show”“sports”和“wedding”)中的一类。
YouTube数据库。这个数据库包含从YouTube上下载的561个用户视频。这个数据库中所包含的事件类别与Kodak数据库相同。
CCV数据库。该数据库是由哥伦比亚大学发布的一个用户视频库。其中包含9 317个从YouTube上下载得到的用户视频。所有的9 317个视频被划分为包含4 659个视频的训练集和包含4 658个视频的测试集,每个视频隶属20种语义类别之一。由于本章研究的是对视频事件的标注,因此可以排除五类非事件类别(“playground”“bird”“beach”“cat”和“dog”)。为了便于关键字检索,将“wedding ceremony”“wedding reception”和“wedding dance”合并为“wedding”。最终,在13个事件类别的2 700个视频上测评不同的算法。这13个类别分别是:“baseball”“basketball”“biking”“birthday”“graduation”“iceskating”“picnic”“parade”“show”“skiing”“soccer”“swimming”和“wedding”。将这些视频数据集作为目标域。从每个视频中随机采样一帧作为关键帧,提取该关键帧的128维SIFT特征。
在构建源域图像组时,根据目标域动作类别,从互联网上搜集关于13类动作图像,包括“basketball”“baseball”“soccer”“iceskating”“biking”“swimming”“graduation”“birthday”“wedding”“skiing”“show”“parade”以及“picnic”。概念关键词来自与动作相关的人工定义语义,动作关键词即为动作类别。概念关键词被所有数据集共享,动作关键词因为各个数据集的类别空间不同而有所不同。表6.2中列出了实验中所使用到的所有关键词,其中列表示动作关键词,行表示概念关键词,第i行第j列表示第j类动作中是否使用了第i行概念关键词(“×”表示该关键字出现,空白表示该关键字未出现)。由每一个关键词互联网检索得到的前200张图像构成每个源域组图像。最终,5 942张图像构成概念特性组,1 647张图像构成动作特性组。对于每张图像,提取其128维SIFT特征表示。
5.性能分析
1)实验设置
在实验中,使用视觉词袋来表示图像和视频特征。通过K-means算法将图像和视频关键帧中抽取出的SIFT特征聚类成2 000个视觉单词。然后根据视觉单词,将每张图像或视频关键帧编码为2 000维特征向量。直接使用文献[64]中提供的5 000维特征向量作为CCV中的视频表示和文献[53]中提供的2 000维特征向量作为Kodak和YouTube中的视频表示。
在训练每个源域动作特性组分类器时,直接使用该组中的图像作为正样本,使用从其他组中随机抽取300张图像构成负样本。对于Kodak和YouTube,在训练和测试阶段均使用所有视频。对于CCV,将4 659个视频作为训练数据,所有视频作为测试数据。
2)对比方法
本部分将标准SVM方法(standard SVM,S_SVM)[65]、基于测地流核(geodesic flow kernel,GFK)的单源域迁移算法[66]、域适应SVM算法(domain adaptive SVM,DASVM)[67]、源域适应机器(domain adaptation machine,DAM)[55]、基于条件概率的多源域适应算法(conditional probability based multi-source domain adaptation,CPMDA)[68]以及多源域选择机器(domain selection machine,DSM)[69]作为对比方法。同时,为了验证动作特性图像组的有效性,设计了只使用概念特性图像组的算法,称其为GDA_sim。由于S_SVM只能处理单源域知识迁移问题,将所有图像组合并成一个源域来训练SVM分类器。对于DASVM和GFK,目标域分类器由源域图像和目标域视频关键帧训练得到。在CPMDA、DAM和DSM中,将G个概念特性组看作G个源域,并将所有动作特性组合并为第G+1个源域。在GDA_sim方法中,只使用G个概念特性图像组。所有方法均使用每个动作类别上的平均准确率(average precision,AP)和所有类别上的平均精度均值来评估。
表6.2 检索互联网图像所使用的关键词[63]
续表
3)结果分析
图6.7,图6.8和图6.9分别显示了CCV、Kodak和YouTube上所有方法在不同动作上的平均准确率。表6.3中同样显示了3个数据库上所有方法的MAP结果。从表6.3中可以看出,GDA_sim方法在3个数据库上的结果均优于其余六种方法(S_SVM,CPMDA,DASVM,DAM,DSM,GFK),表明根据语义来划分源域数据比根据来源划分数据更有效。GDA在3个数据库上均取得了最好的结果。这显示了联合学习组分类器与组权重有益于正迁移。
图6.7 不同方法在CCV上的平均准确率[63](见彩插)
图6.8 不同方法在Kodak上的平均准确率[63](见彩插)
图6.9 不同方法在YouTube上的平均准确率[63](见彩插)
表6.3 CCV、Kodak以及YouTube上不同方法的比较结果[63]
本部分还验证了优化函数中每一项的有效性。图6.10显示了当λL=0、λD=0以及λP=0时的不同结果。从图6.10中的结果可以发现当任何一个正则项从优化函数中移除以后,大部分事件的平均准确率会大大降低。而对于如“soccer”和“baseball”等动作类别,当λP 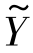 (AWTXt)T被移除以后准确率不减反增。这可能是由于伪标签的预测错误导致了λP
(AWTXt)T被移除以后准确率不减反增。这可能是由于伪标签的预测错误导致了λP 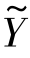 (AWTXt)T结果偏差。对于事件“basketball”和“wedding”,当λP
(AWTXt)T结果偏差。对于事件“basketball”和“wedding”,当λP 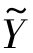 (AWTXt)T从目标函数中移除以后准确率却有所增加。原因可能在于互联网图像中存在噪声,使其表象特征或者语义特征与目标域视频不一致,由此导致了λP
(AWTXt)T从目标函数中移除以后准确率却有所增加。原因可能在于互联网图像中存在噪声,使其表象特征或者语义特征与目标域视频不一致,由此导致了λP 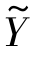 (AWTXt)T的表现变差。
(AWTXt)T的表现变差。
图6.10 不同正则项对迁移性能的影响[63](见彩插)
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





