Duan等人[53]提出自适应多核学习(adaptive multiple kernel learning,A-MKL)方法,借助大量已标注的Web视频(辅助域,也称源域)来指导用户视频(目标域)的识别。该方法旨在从一系列预学习的分类器和一个基于多核的扰动函数中自适应地学习目标域分类器,其中预学习的分类器可以看作是学习一个鲁棒的自适应目标域分类器的先验。
1.自适应支持向量机
在自适应支持向量机[54]中,目标域分类器f T(x)来源于由辅助域(也就是源域)数据训练的分类器f A(x)(也称为源域分类器)。具体地,目标域决策函数被定义为
其中,Δf(x)为扰动函数,反映了源域和目标域决策函数之间的差异。同时A-SVM也可以构建多个辅助域分类器,这些辅助域分类器平均融合得到f A(x)。域迁移支持向量机(domain transfer SVM,DTSVM)[55]在自适应支持向量机的基础上,采用最大平均差异[56]来度量源域与目标域之间的数据分布差异,并将最小化MMD与最优化目标域决策函数联合建模。MMD距离是辅助域DA的样本均值与目标域DT的样本均值在再生核希尔伯特空间H中的距离,定义为
其中,![]() 分别是辅助域和目标域的样本。k是由非线性特征映射函数φ(·)得到的核函数k,由k(xi,xj)=φ(xi)Tφ(xj)计算而得。可以定义包含N=nA+nT个元素的列向量s,其前nA个元素值设为1/nA,后nT个元素值设为-1/nT,由此,式(6.2)定义的MMD距离可以简化为
分别是辅助域和目标域的样本。k是由非线性特征映射函数φ(·)得到的核函数k,由k(xi,xj)=φ(xi)Tφ(xj)计算而得。可以定义包含N=nA+nT个元素的列向量s,其前nA个元素值设为1/nA,后nT个元素值设为-1/nT,由此,式(6.2)定义的MMD距离可以简化为
其中S=ssT∈RN×N,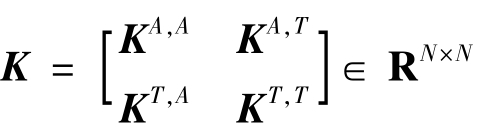 。这里的
。这里的![]() 是辅助域定义的核矩阵,
是辅助域定义的核矩阵,![]() 是目标域定义的核矩阵,
是目标域定义的核矩阵,![]() 是从辅助域到目标域跨域定义的核矩阵,
是从辅助域到目标域跨域定义的核矩阵,![]() 是从目标域到辅助域跨域定义的核矩阵。
是从目标域到辅助域跨域定义的核矩阵。
2.时空对齐金字塔匹配
金字塔匹配算法被广泛应用在许多计算机视觉任务中。该算法在不同域(例如空间域、时间域)中引入金字塔型分层,融合来自多个金字塔层级的信息以提升模型性能。传统的空间金字塔匹配及其时空扩展使用固定的块到块或体到体的匹配(也就是未对齐的时空匹配)。Duan等人[53]提出时空对齐的金字塔匹配[57]算法,将空间对齐的金字塔匹配(spatially aligned pyramid matching,SAPM)和时间对齐的金字塔匹配(temporally aligned pyramid matching,TAPM)联合扩展到时空域,使得不同空间和时间位置的时空体也能匹配。
首先,在不同层级将每个视频片段分割为8l个互不重叠的时空体,l=0,…,L-1,L为金字塔层数。并将每个时空体的大小设为原视频长度、宽度、时间维度的1/2l大小。然后,提取每个时空体的时空特征,包括梯度直方图(histograms of oriented gradient,HOG)和光流直方图(histograms of optical flow,HOF),并将它们拼接形成特征向量。同时,对每个视频片段采样图像帧并提取其SIFT(scale-invariant feature transform)特征[58]。接下来,需要计算每对时空体Vi(r)和Vj(c)之间的距离Drc,其中r,c=1,…,R,R是视频中时空体总数。使用推土机距离(earth mover′s distance,EMD)计算Drc,即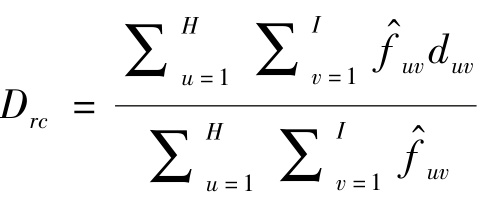 ,其中,H、I分别表示时空体Vi(r)和Vj(c)中的图像块的数量;duv是两个图像块之间的距离,
,其中,H、I分别表示时空体Vi(r)和Vj(c)中的图像块的数量;duv是两个图像块之间的距离,![]() 是通过求解线性规划问题得到的最优流。最后通过整型EMD的计算进一步整合来自不同时空体的信息,从而实现时空体的精准对齐。具体做法是使用线性规划问题中的标准单纯形法,求解一个包含表示时空体Vi(r)和Vj(c)之间唯一匹配的二进制解的流矩阵。详细优化过程可参考文献[61]。
是通过求解线性规划问题得到的最优流。最后通过整型EMD的计算进一步整合来自不同时空体的信息,从而实现时空体的精准对齐。具体做法是使用线性规划问题中的标准单纯形法,求解一个包含表示时空体Vi(r)和Vj(c)之间唯一匹配的二进制解的流矩阵。详细优化过程可参考文献[61]。
3.自适应多核学习
使用来自源域和目标域的训练数据为每层金字塔和每种局部特征训练一个独立的分类器,这样就可以得到一系列分类器。进一步平均融合这些分类器,获得关于时空特征的平均分类器![]() 和关于SIFT特征的平均分类器
和关于SIFT特征的平均分类器![]() 。这些分类器可以被视为预学习分类器
。这些分类器可以被视为预学习分类器![]() 。核函数k是多个基核的线性组合,即
。核函数k是多个基核的线性组合,即![]() ,其中,dm为线性组合系数。基核km是由非线性特征映射函数φm(·)计算而得,即km(xi,xj)=φm(xi)Tφm(xj)。将任意样本x的目标决策函数定义如下:
,其中,dm为线性组合系数。基核km是由非线性特征映射函数φm(·)计算而得,即km(xi,xj)=φm(xi)Tφm(xj)。将任意样本x的目标决策函数定义如下:
其中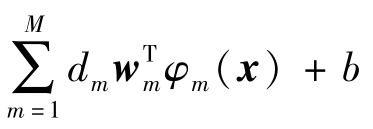 是带有偏置项b的扰动函数。
是带有偏置项b的扰动函数。
自适应多核学习的第一个优化目标是减小源域和目标域之间的数据分布差异。定义属于D={d∈RM|dT1=1,d≥0}的系数向量d=[d1,…,dM]T。式(6.3)可以改写为
其中h=[tr(K1S),…,tr(KMS)]T,并且Km=[φm(x)Tφm(x)]∈RN×N是定义在辅助域和目标域的样本上的第m个基核矩阵。自适应多核学习的第二个目标是最小化结构风险函数。
设(xi,yi)|n i=1为来自源域和目标与的已标注训练样本,则自适应多核学习的优化问题表示为
其中
其中β=[β1,…,βP]T且λ、C>0是正则参数。定义![]() 且
且![]()
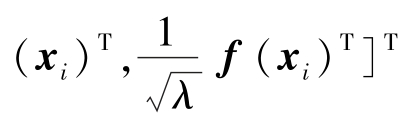 ,其中f(xi)=[f1(xi),…,fP(xi)]T。再定义
,其中f(xi)=[f1(xi),…,fP(xi)]T。再定义![]() ,那么式(6.7)中的优化问题就成为二次规划问题:(https://www.daowen.com)
,那么式(6.7)中的优化问题就成为二次规划问题:(https://www.daowen.com)
通过引入拉格朗日乘子α=[α1,…,αn]T,式(6.8)的对偶形式演变为(推导详见文献[59])
其中J(d)是关于d线性的,![]()
![]() 是根据两个域中有标签的训练数据定义的,并且
是根据两个域中有标签的训练数据定义的,并且![]()
![]() 。由于式(6.9)中优化问题的形式与含有核矩阵
。由于式(6.9)中优化问题的形式与含有核矩阵![]() 的支持向量机的对偶形式正好相同,所以该优化问题可以通过现成的支持向量机求解方式来解决,例如LIBSVM。
的支持向量机的对偶形式正好相同,所以该优化问题可以通过现成的支持向量机求解方式来解决,例如LIBSVM。
可以证明式(6.6)中的优化问题对于d、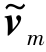 、b和ξi是联合凸优化,因此可以使用文献[59]中提出的迭代坐标下降过程来迭代更新α和d以获得全局最优解。在第t次迭代中,固定dt,则αt可以通过LIBSVM求解。固定αt,则dt的更新如下:
、b和ξi是联合凸优化,因此可以使用文献[59]中提出的迭代坐标下降过程来迭代更新α和d以获得全局最优解。在第t次迭代中,固定dt,则αt可以通过LIBSVM求解。固定αt,则dt的更新如下:
其中![]() 是更新方向,ηt是可以通过标准线性搜索获得的学习率。给定dt,则∇tG=hhTdt+θ∇tJ是式(6.6)中G的梯度,其中∇tJ是式(6.9)中J的梯度。
是更新方向,ηt是可以通过标准线性搜索获得的学习率。给定dt,则∇tG=hhTdt+θ∇tJ是式(6.6)中G的梯度,其中∇tJ是式(6.9)中J的梯度。![]() 是G的海森矩阵。因为hhT不是满秩的,所以把hhT替换为hhT+∈I以避免数值不稳定性,其中∈在实验中设为10-4。最终,自适应多核学习方法的目标决策函数式(6.4)可以写为
是G的海森矩阵。因为hhT不是满秩的,所以把hhT替换为hhT+∈I以避免数值不稳定性,其中∈在实验中设为10-4。最终,自适应多核学习方法的目标决策函数式(6.4)可以写为
4.数据集
实验的源域来自包含906个训练样本的YouTube视频。这些视频具有动作类别标注。目标域的视频由柯达用户视频基准数据集[60]中的部分用户视频和从YouTube网站收集的用户视频,共包含195个视频。实验中共定义了6类动作类别,分别是“婚礼”“生日”“野餐”“游行”“演出”和“运动”。为每个事件随机生成3个用户视频(总共18个视频)作为目标域中有标签的训练数据,目标域中剩下的视频作为测试数据。
对于数据集中的所有视频,提取局部时空特征[61]。具体地,分别提取72维HOG和90维HOF,然后将它们连接在一起,形成162维的特征向量。以每秒2帧的速度对每个视频片段进行采样,从每个视频片段中提取图像帧(平均每个视频有65帧)。对于每一帧,从显著区域提取128维SIFT特征,平均每个视频有1 385个ST特征和4 144个SIFT特征。然后,利用K-Means聚类构建可视化词汇表,分别对ST(spatial-temporal)特征数据和SIFT特征数据进行聚类,分别得到1 000个和2 500个聚类中心。
5.性能分析
为了验证自适应多核学习方法的有效性,将其与特征复制(feature replication,FR)[62]、自适应SVM[54]、域迁移SVM[55]和多核学习(multiple kernel learning,MKL)四种方法进行对比实验。对于上述所有方法,使用固定正则参数C=1来训练多个一对多分类器。使用非插值平均精度(average precision,AP)进行性能评估,而平均精度均值(mean average precision,MAP)是所有事件类别的AP均值。
用4个核函数来测试性能,它们分别是:高斯核函数(即K(i,j)=exp(-γD2(Vi,Vj))),拉普拉斯核函数(即![]() ),距离平方反比(inverse distance squared,IDS)核函数(即
),距离平方反比(inverse distance squared,IDS)核函数(即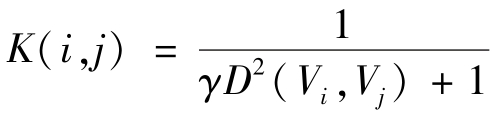 )和逆距离(inverse distance,ID)核函数(即
)和逆距离(inverse distance,ID)核函数(即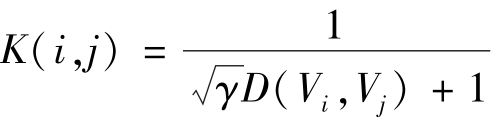 ),其中,D(Vi,Vj)为视频Vi与Vj之间的距离;γ为核参数。使用默认的核参数
),其中,D(Vi,Vj)为视频Vi与Vj之间的距离;γ为核参数。使用默认的核参数![]() ,其中A为所有训练样本之间距离平方的均值。
,其中A为所有训练样本之间距离平方的均值。
表6.1所示的是A-MKL、FR、A-SVM、MKL和DTSVM五种方法在下面三种情况的实验比较结果:①基于SIFT特征学习的分类器;②基于ST特征学习的分类器;③基于SIFT特征和ST特征学习的分类器。从表6.1中可以看到:
表6.1 三种情况下所有方法在5类动作种的MAP和标准差 单位:%
(1)在本实验中,在三种情况下A-SVM的MAP都是最差的,这可能是因为目标域中数量有限的已标注训练样本(例如,每个事件3个样本)不足以使A-SVM鲁棒地学习一个仅基于一个高斯核的自适应目标分类器。
(2)几乎在所有情况下,DTSVM在每个事件中的AP均值都优于MKL,说明模型迁移的有效性。
(3)A-MKL通过有效地融合多个预学习分类和多个基核并减少两个域之间数据分布的不匹配度,在三种情况下都达到了最佳MAP。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





