1.对抗部分域适应
Cao等人[3]提出了对抗部分域适应(partial adversarial domain adaptation,PADA)方法,通过学习源域各个类别的权重,降低属于外部类别的源域样本的权重,避免类别空间不一致导致的负迁移问题;并通过对齐属于共享类别的源域和目标域样本,提高域适应的性能。
该方法基于对抗迁移的思想,对反向传播域适应方法(本书第4章4.4.2小节中介绍)进行了改进,使其适应于部分域适应的场景。与反向传播域适应方法相同,对抗部分域适应方法通过特征提取器与域分类器的对抗训练学习域不变的特征表示,从而使源域分类器适应于目标域任务。在此基础上,针对部分域适应的场景,提出了源域样本的加权策略,用于降低属于外部类别的源域样本在迁移过程中的权重,并将利用加权后的源域样本进行后续域不变的特征表示学习。
1)模型结构
对抗部分域适应方法包括3个模块:特征提取器F、分类器C和域分类器D。特征提取器F用于提取输入样本xi的特征表示fi=F(xi;θf)∈RD,其中θf是特征提取器的参数。分类器C的输入是样本xi的特征表示fi,输出是样本xi在源域类别空间Ys上的类别概率分布![]() ,其中θy是分类器C的参数。域分类器D用于区分样本xi是来自源域还是来自目标域,其输入是源域或目标域样本xi的特征表示fi,输出是xi的域标签di=D(fi;θd),其中θd是域分类器D的参数。
,其中θy是分类器C的参数。域分类器D用于区分样本xi是来自源域还是来自目标域,其输入是源域或目标域样本xi的特征表示fi,输出是xi的域标签di=D(fi;θd),其中θd是域分类器D的参数。
图5.2为对抗部分域适应方法的框架。该框架与反向传播域适应方法相似,包含两个分支:①分类分支通过最小化分类损失Ly学习判别性特征表示;②对抗分支通过梯度反转层实现特征提取器F与域分类器D的对抗训练以学习域不变的特征表示,相应损失为对抗损失Ld。该框架的详情请见本书第4章4.4.2小节中介绍的反向传播域适应方法。基于该框架,对抗部分域适应方法采用源域类别的加权策略,学习源域样本的权重γ,并用加权后的源域样本对分类损失Ly和对抗损失Ld进行调整。下面将详细介绍源域类别的加权策略。
图5.2 对抗部分域适应方法的框架[3]
2)源域类别加权
给定样本xi,分类器C预测其在源域类别空间Ys上的类别概率分布y^i,即样本xi属于源域各个类别的概率。因为源域外部类别集合与目标域共享类别集合的交集为空,目标域样本与属于外部类别的源域样本通常不相似,所以将目标域样本预测为外部类别的概率很小。但由于源域和目标域之间存在域偏移,源域分类器对目标域样本的分类结果不够准确,可能会错误地将目标域样本分配到外部类别。因此,可以采用对所有目标域样本的平均预测结果对源域类别进行加权。源域类别在域适应过程中的权重γ计算如下:
其中,γ是![]() 维向量,γ的第k维元素γk表示第k个源域类别在域适应过程中的权重。实际上,γk反映了所有目标域样本被预测为第k个源域类别的平均概率,γk越小,表明第k个源域类别是外部类别的概率越大,在域适应过程中应当降低属于第k个类别的源域样本的权重。根据权重γ的定义,我们有
维向量,γ的第k维元素γk表示第k个源域类别在域适应过程中的权重。实际上,γk反映了所有目标域样本被预测为第k个源域类别的平均概率,γk越小,表明第k个源域类别是外部类别的概率越大,在域适应过程中应当降低属于第k个类别的源域样本的权重。根据权重γ的定义,我们有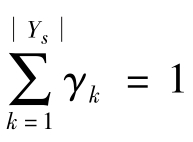 。最后,通过
。最后,通过![]() 对源域类别的权重γ进行归一化。
对源域类别的权重γ进行归一化。
3)损失函数
根据源域类别的权重γ,采用加权后的源域样本与目标域样本学习域不变的特征表示。总体目标函数为
其中,![]() 是源域样本
是源域样本![]() 的所属类别
的所属类别![]() 的权重,λ是分类损失Ly和对抗损失Ld的平衡系数。式(5.2)右边的第一项是分类损失,第二项和第三项是对抗损失。通过对抗训练,优化网络参数θf、θy以及θd,其优化目标为
的权重,λ是分类损失Ly和对抗损失Ld的平衡系数。式(5.2)右边的第一项是分类损失,第二项和第三项是对抗损失。通过对抗训练,优化网络参数θf、θy以及θd,其优化目标为
通过交替迭代进行式(5.3)和式(5.4)定义的优化目标,减少源域和目标域之间的域偏移,从而使源域上训练的分类器C适应于目标域任务。
2.选择对抗部分域适应
与对抗部分域适应方法相同,选择对抗部分域适应方法[4]同样基于对抗迁移的思想。不同之处在于,选择对抗部分域适应方法采用了多个域分类器用于源域和目标域各个类别的对齐,使得属于同一个类别的源域和目标域样本对齐。根据样本的类别概率分布得到每个域分类器的权重,称之为样本级别的权重。此外,根据所有目标域样本在源域分类器上的平均类别概率分布,设计了类别级别的权重,对源域的所有类别进行加权,从而提高属于共享类别的源域样本的权重、降低属于外部类别的源域样本的权重。
1)模型结构
选择对抗部分域适应方法包括3个模块:特征提取器F、分类器C和域分类器D。特征提取器F用于提取输入样本xi的特征表示fi=F(xi;θf)∈RD,其中θf是特征提取器的参数。分类器C的输入是样本xi的特征表示fi,输出是样本xi在源域类别空间Ys上的类别概率分布![]() ,表示为
,表示为![]() 的第k维元素
的第k维元素![]() 表示样本xi属于第k类的概率,
表示样本xi属于第k类的概率,![]() 是分类器C的参数。域分类器D包括由
是分类器C的参数。域分类器D包括由![]() 个类别相关的域分类器,表示为
个类别相关的域分类器,表示为![]() 。第k个域分类器Dk负责对齐属于第k个类别的源域样本和目标域样本,其输入是源域或目标域样本xi的特征表示fi,输出是xi的域标签
。第k个域分类器Dk负责对齐属于第k个类别的源域样本和目标域样本,其输入是源域或目标域样本xi的特征表示fi,输出是xi的域标签![]()
![]() ,其中
,其中![]() 是域分类器Dk的参数。图5.3为选择对抗部分域适应方法的框架图。
是域分类器Dk的参数。图5.3为选择对抗部分域适应方法的框架图。
2)源域加权
分类器C预测的样本xi的类别概率分布y^i描述了将样本xi分配到源域各个类别的概率。可以将样本xi预测为第k类的概率作为第k个域分类器Dk的权重,从而在对齐源域和目标域样本的过程中考虑到类别信息。因此,域分类器的目标函数为
其中,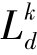 表示根据样本xi及其域标签di计算的交叉熵损失;
表示根据样本xi及其域标签di计算的交叉熵损失;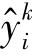 为
为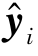 的第k维元素,表示分类器C预测的样本xi分配到第k类的概率。
的第k维元素,表示分类器C预测的样本xi分配到第k类的概率。
除了上述样本级别的加权之外,选择对抗部分域适应方法还使用了类别级别的加权策略,以进一步降低属于外部类别的源域样本在域适应过程中的权重。类别级别的加权策略与对抗部分域适应方法中的源域类别加权策略相同,即采用由源域分类器预测的所有目标域样本的平均概率分布作为各个源域类别的权重。第k个源域类别的权重γk计算如下:
图5.3 选择对抗部分域适应方法的框架图[4]
其中,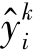 是分类器C预测的目标域样本
是分类器C预测的目标域样本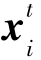 属于第k类的概率。
属于第k类的概率。
结合类别级别的权重,式(5.5)定义的域分类器的优化目标函数可以改写为
3)熵最小化及总体目标函数
上述样本级别的权重和类别级别的权重均依赖于分类器C预测的样本的类别概率分布。由于目标域缺乏标注信息,目标域样本的预测性能较低。因此,采用熵最小化原理进一步优化分类器C,以提升其在目标域上的分类结果。具体地,通过最小化目标域样本类别概率分布的熵,鼓励类别之间的低密度分离,对应的损失函数为
其中,H(·)是条件熵损失函数,定义为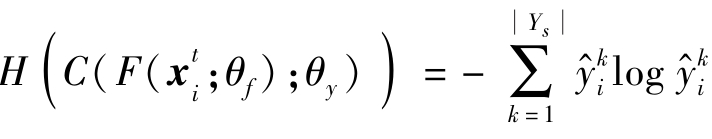 。
。
选择对抗部分域适应的总体目标函数为
通过对抗训练的方式,优化选择对抗部分域适应的网络参数θf、θy以及![]() 。优化目标如下:
。优化目标如下:
通过交替迭代优化式(5.10)和式(5.11),特征提取器F能够提取具有判别性的域不变的特征表示,从而使分类器C适应于目标域任务。
3.重要性加权对抗部分域适应
Zhang等人[5]提出的重要性加权部分域适应方法,使用域分类器学得的域信息对源域样本进行加权。该方法基于对抗迁移的思想,采用双域分类器的结构,第一个域分类器通过衡量源域样本与目标域的相关性,对源域样本进行加权;第二个域分类器用于对齐加权后的源域样本和目标域样本,学习域不变的特征表示。此外,不同于对抗部分域适应方法与选择对抗部分域适应方法对源域和目标域采用一个公共的特征提取器,重要性加权部分域适应方法分别学习源域特征提取器和目标域特征提取器,使习得的样本特征包含更多的域特定信息。
1)网络结构
图5.4所示重要性加权对抗部分域适应包括5个模块:源域特征提取器Fs、目标域特征提取器Ft、分类器C、域分类器D和域分类器D0。源域特征提取器Fs和目标域特征提取器Ft分别用于提取源域和目标域样本的特征表示。分类器C用于预测样本的类别概率分布。域分类器D用于学习源域样本的权重。域分类器D0用于对齐加权后的源域样本和目标域样本。图5.4为重要性加权对抗部分域适应方法的框架图。
图5.4 重要性加权对抗部分域适应方法[5]
该方法采用两阶段的训练方式。首先,根据源域样本![]() 及其类别标签
及其类别标签![]() ,优化源域特征提取器Fs和分类器C,学习具有判别性的特征表示,优化目标为
,优化源域特征提取器Fs和分类器C,学习具有判别性的特征表示,优化目标为
其中,L(·)为交叉熵损失。然后,固定源域特征提取器Fs,用其参数初始化目标域特征提取器Ft。再通过域对抗学习优化目标域特征提取器Ft和域分类器D。(www.daowen.com)
在不考虑源域和目标域类别空间不同的情况下,域分类器致力于将源域和目标域区分开,目标域特征提取器致力于提取与源域相似的目标域样本的特征,从而混淆域分类器使其无法区分源域样本和目标域样本。因此,目标域特征提取器Ft和域分类器D的优化目标为
其中,域分类器D是一个二分类器。所有源域样本的域标签为1,所有目标域样本的域标签为0。给定源域特征提取器Fs,对于任意目标域特征提取器Ft,最优的域分类器D为
其中,z=Fs(x)或者z=Ft(x)表示源域或目标域样本经过相应特征提取器后的特征表示。ps(z)表示源域特征提取器Fs学得的源域特征分布,pt(z)表示目标域特征提取器Ft学得的目标域特征分布。
2)源域样本加权
式(5.13)定义了在不考虑类别空间不同的情况下的优化目标。针对部分域适应,在源域和目标域类别空间不同的情况下,重要性加权对抗域适应方法提出了基于域分类器D的源域样本加权策略。假设域分类器D收敛到了最优值D∗,域分类器的输出值反映了样本来自源域的可能性。对于源域样本![]() ,其特征表示为
,其特征表示为![]() 。当D∗(zs)≈1时,由于目标域中没有属于外部类别的样本,样本
。当D∗(zs)≈1时,由于目标域中没有属于外部类别的样本,样本![]() 很可能来自源域中的外部类别,应该降低该样本在域适应过程中的权重。当D∗(zs)≈0时,样本
很可能来自源域中的外部类别,应该降低该样本在域适应过程中的权重。当D∗(zs)≈0时,样本![]() 可能来自源域的共享类别,应该提升其权重。因此,源域样本的权重应该与域分类器D的输出值成反比,定义为
可能来自源域的共享类别,应该提升其权重。因此,源域样本的权重应该与域分类器D的输出值成反比,定义为
由于源域样本的权重是相对的,因此按照如下方式对权重进行归一化:
从而使得![]() 。为了更好地学习域不变的特征表示,引入域分类器D0,用于对齐加权后的源域样本和目标域样本。
。为了更好地学习域不变的特征表示,引入域分类器D0,用于对齐加权后的源域样本和目标域样本。
根据源域样本的权重,在类别空间不同的情况下,目标域特征提取器Ft和域分类器D0的优化目标为
其中,w(zs)作为D的函数独立于D0,可以看作一个常数。
3)总体目标函数
重要性加权对抗部分域适应方法的总体优化目标为
其中,![]() 表示信息熵最小化约束。重要性加权对抗部分域适应方法通过下列方式迭代优化:首先,按照式(5.18)优化Fs和C。然后,固定Fs和C,通过式(5.19)和式(5.20)迭代优化D、D0和Ft。最终,通过目标域特征提取器Ft和分类器C完成对目标域样本的分类。
表示信息熵最小化约束。重要性加权对抗部分域适应方法通过下列方式迭代优化:首先,按照式(5.18)优化Fs和C。然后,固定Fs和C,通过式(5.19)和式(5.20)迭代优化D、D0和Ft。最终,通过目标域特征提取器Ft和分类器C完成对目标域样本的分类。
4.域对抗强化学习部分域适应
不同于上述部分域适应方法通过利用域信息或者类别概率分布信息对源域数据在样本层面进行挑选,Chen等人[6]用序列动作建模样本的挑选过程,在集合层面对源域数据进行挑选,以便学得全局优化的挑选策略。基于这一思想,他们提出了域对抗强化学习部分域适应方法,将源域数据的挑选建模为马尔可夫决策过程,采用强化学习自动学习源域数据的挑选策略,同时结合域对抗学习根据挑选出的源域数据与目标域数据学习域不变的特征表示,从而减少源域和目标域在共享类别上的特征分布差异。此外,该方法采用基于域对抗学习的奖励函数,通过度量源域样本与目标域的相关性,指导基于强化学习的源域数据挑选。
1)模型结构
图5.5为域对抗强化学习部分域适应方法的框架图,该方法由深度强化学习和域对抗学习组成。深度强化学习用于学习属于共享类别的源域样本的挑选策略。域对抗学习用于学习域不变的特征表示,为强化学习中的智能体提供奖励值。
图5.5 域对抗强化学习部分域适应方法的框架图[6]
采用深度强化学习网络估计动作-值函数。该函数输入是当前的状态,输出是执行各个动作的奖励,包括即时奖励和未来奖励,称之为Q值。对于一次挑选,智能体从当前候选集合(待挑选样本构成的集合)中选择最大Q值对应的样本移出并加入已选中集合。执行该动作的即时奖励值由域对抗学习提供。该奖励和下一时刻的状态被送入深度强化学习网络进行下一次挑选并更新挑选策略。经过多次挑选,域对抗学习使用已选中集合中的源域样本和目标域样本,学习域不变的特征表示。
2)深度强化学习
定义一个由待挑选源域样本构成的候选集合Dc。从源域随机采样的样本集合作为Dc的初始化。定义一个由智能体挑选出的源域样本组成的已选中集合De,该集合被初始化为空集。智能体的状态由当前候选集合Dc中所有样本的特征向量拼接而成。在初始时刻,智能体状态表示为![]() ,其中
,其中![]() 表示特征提取器F提取的源域样本
表示特征提取器F提取的源域样本![]() 的特征表示;Nc表示候选集合Dc包含源域样本的数量。智能体的动作定义为从候选集合Dc中选出一个对应样本并加入已选中集合De中。智能体的动作数等于候选集合的样本数。设t时刻的智能体状态为st,则其执行的动作为
的特征表示;Nc表示候选集合Dc包含源域样本的数量。智能体的动作定义为从候选集合Dc中选出一个对应样本并加入已选中集合De中。智能体的动作数等于候选集合的样本数。设t时刻的智能体状态为st,则其执行的动作为
其中,Q(st,a)表示在状态st下各个动作的Q值,由深度强化学习网络来学习。该网络的目标函数为
其中,V(st)是Q(st,at)的目标值,定义为
其中,第一项Rt是智能体执行动作at的即时奖励,第二项是由深度强化学习网络估计的下一状态下能够取得的最大奖励,即执行动作at的未来奖励。
当执行动作at时,智能体将候选集合中的源域样本x移出并加入已选中集合De中,获得的即时奖励Rt为
其中,φ(·)是度量源域样本与目标域相关性的函数,将在下面的在域对抗学习部分详细介绍。源域样本x与目标域的相关性越大,φ(x)的值就越大。当φ(x)大于阈值τ,智能体获得+1的奖励,否则奖励为-1。这样设计的奖励能够鼓励智能体学会挑选出与目标域相关性高的样本。当奖励为-1时,智能体到达终止状态,停止对当前候选集的选择,并开始对下一个候选集的选择。
3)域对抗学习
域对抗学习由特征提取器F、域分类器D和分类器C构成。域分类器致力于正确分类源域样本与目标域样本,特征提取器致力于生成域不变的特征使得域分类器无法区分源域样本与目标域样本。域分类器D的输入是已选中集合De中的源域样本或者目标域样本,输出是K+1维的向量,其前K维表示输入样本的类别概率分布,第K+1维表示输入样本的域标签。
给定从源域分布p(x)采样的源域样本![]() 及其类别标签
及其类别标签![]() ,从目标域分布q(x)采样的目标域样本
,从目标域分布q(x)采样的目标域样本![]() 。域分类器D和特征提取器F的对抗训练过程如下。
。域分类器D和特征提取器F的对抗训练过程如下。
固定特征提取器F,域分类器D致力于将源域样本正确分类到K个源域类别中,并将目标域样本分类为来自目标域,其对抗损失定义为
其中,H(·,·)是交叉熵损失。源域样本![]() 的标签
的标签![]() 是K+1维的向量。前K维是源域样本类别标签的一位有效编码。第K+1维为0,表示样本来源于源域。目标域样本
是K+1维的向量。前K维是源域样本类别标签的一位有效编码。第K+1维为0,表示样本来源于源域。目标域样本![]() 的标签
的标签![]() 的第K+1维为1,表示样本来源于目标域,其余为0。
的第K+1维为1,表示样本来源于目标域,其余为0。
固定域分类器D,特征提取器F致力于混淆域分类器D,使其将目标域样本分到K个源域类别中,并将源域样本预测为来自目标域,其对抗损失定义为
其中,源域样本![]() 的标签
的标签![]() 的第K+1维为1,其余为0。目标域样本
的第K+1维为1,其余为0。目标域样本![]() 的标签
的标签![]() 的第K+1维为0,前K维是分类器C预测的目标域样本伪标签的一位有效编码。
的第K+1维为0,前K维是分类器C预测的目标域样本伪标签的一位有效编码。
分类器C通过最小化源域风险来保持特征的判别性,其分类损失为
其中,![]() 是源域样本
是源域样本![]() 的标签。
的标签。![]() 是指示函数,当
是指示函数,当![]() 时为1,否则为0。
时为1,否则为0。
域对抗学习的整体目标函数定义为
根据域分类器和分类器的输出,源域样本与目标域的相关性度量函数φ(·)定义为
其中,![]() 是样本级别的相关性,是域分类器预测的源域样本
是样本级别的相关性,是域分类器预测的源域样本![]() 属于目标域的概率,即域分类器的第K+1维输出。
属于目标域的概率,即域分类器的第K+1维输出。![]() 是类别级别的相关性,表示第
是类别级别的相关性,表示第![]() 个源域类别的权重,是分类器C将所有目标域样本预测为第
个源域类别的权重,是分类器C将所有目标域样本预测为第![]() 类的平均概率。
类的平均概率。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





