1.反向传播域适应方法
Ganin和Lempitsky[40]于2015年首次将生成对抗思想用于深度神经网络域适应迁移,提出反向传播域适应方法来学习源域和目标域数据的特征表示。该特征表示同时具有域不变性和判别性,有利于模型从源域迁移至目标域。
反向传播域适应方法包括3个模块:特征提取器、分类器和域分类器。特征提取器学习输入样本(源域或目标域)的特征表示。分类器预测输入样本的类别标签,该类别标签由具体分类任务决定。域分类器是核心模块,预测输入样本的域标签,即判断样本属于源域还是目标域。为了优化这3个模块,Ganin等人设计了用于训练分类器的分类损失和用于训练域分类器的域对抗损失。通过最小化分类损失,特征提取器生成的特征表示具有判别性。通过最大化域对抗损失,域分类器无法区分源域样本和目标域样本,因此特征表示具有域不变性。为了进行端到端的训练,在梯度反向传播过程中,采用梯度反转层(gradient reversal layer,GRL)将域分类器参数的梯度乘以负标量进行反转。
反向传播域适应方法具有很强的扩展性,可以嵌入任何面向不同任务的神经网络。在嵌入时只需要增加几个标准网络层和一个梯度反转层,使其适应于具体任务。在多个图像分类任务上,反向传播域适应方法均取得了很好的效果。
1)模型结构
图4.15为反向传播对抗域适应方法框架。对于输入样本x,预测其类别标签y∈Ys以及域标签d∈{0,1}。对于源域样本![]() ,其类别标签为
,其类别标签为![]() ,其域标签为
,其域标签为![]() 。对于目标域样本
。对于目标域样本![]() ,其域标签为
,其域标签为![]() 。从输入到输出的映射过程可分解为三个部分:①将样本x输入至特征提取器F,得到其特征向量f=F(x;θf)∈RD。F由多个前向传播层组成,其参数为θf;②将特征向量f输入分类器C,得到其类别标签y。C由多个前向传播层组成,参数为θy;③将特征向量f输入域分类器D,得到其域标签d。D由多个前向传播层组成,参数为θd。
。从输入到输出的映射过程可分解为三个部分:①将样本x输入至特征提取器F,得到其特征向量f=F(x;θf)∈RD。F由多个前向传播层组成,其参数为θf;②将特征向量f输入分类器C,得到其类别标签y。C由多个前向传播层组成,参数为θy;③将特征向量f输入域分类器D,得到其域标签d。D由多个前向传播层组成,参数为θd。
在模型训练阶段,对于源域数据,设计分类损失来优化特征提取器F和分类器C,从而保证特征f具有判别性。为了使F和C能有效迁移至目标域,必须保证特征f需具有域不变性,即特征分布![]() 和
和![]() 相似,其中S(x)和T(x)分别表示源域和目标域数据的边缘分布。由于特征f是高维的、且两个域的特征分布在训练过程中不断变化,估计S(f)和T(f)之间的差异并不容易。当域分类器被优化到能够区分不同域的特征分布时,可以通过训练域分类器的损失来估计分布S(f)和分布T(f)之间的差异。当该损失达到最大时,域分类器无法区分源域样本和目标域样本,此时S(f)和T(f)之间的差异最小(即源域和目标域的特征分布趋同)。
相似,其中S(x)和T(x)分别表示源域和目标域数据的边缘分布。由于特征f是高维的、且两个域的特征分布在训练过程中不断变化,估计S(f)和T(f)之间的差异并不容易。当域分类器被优化到能够区分不同域的特征分布时,可以通过训练域分类器的损失来估计分布S(f)和分布T(f)之间的差异。当该损失达到最大时,域分类器无法区分源域样本和目标域样本,此时S(f)和T(f)之间的差异最小(即源域和目标域的特征分布趋同)。
图4.15 反向传播对抗域适应方法框架[40]
由此,反向传播对抗域适应方法的目标函数定义为
其中,θf、θy、θd分别为特征提取器、分类器和域分类器的参数。Ly是源域数据的分类损失,用于优化特征提取器和分类器。Ld是域对抗损失,用于域分类器和特征提取器的对抗优化。![]() 和
和![]() 分别表示第i个样本的分类损失和域对抗损失;λ为平衡系数。采用极大极小策略学习最优的
分别表示第i个样本的分类损失和域对抗损失;λ为平衡系数。采用极大极小策略学习最优的![]() ,即
,即
式(4.64)表明,当域分类器达到最优(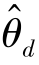 )时,通过最小化目标函数E,可以得到最优分类器(
)时,通过最小化目标函数E,可以得到最优分类器(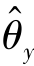 )和最优特征提取器(
)和最优特征提取器(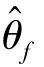 ),此时分类损失Ly最小且域对抗损失Ld最大。式(4.65)表明,当分类器达到最优(
),此时分类损失Ly最小且域对抗损失Ld最大。式(4.65)表明,当分类器达到最优(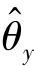 )和特征提取器达到最优(
)和特征提取器达到最优(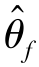 )时,通过最大化目标函数E,可以得到最优域分类器(
)时,通过最大化目标函数E,可以得到最优域分类器(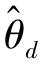 ),此时域对抗损失Ld最小。
),此时域对抗损失Ld最小。
2)反向传播优化
式(4.64)和式(4.65)定义的优化问题具体可以表示为
其中,μ为学习率。式(4.66)~式(4.68)表示的更新过程类似于前向传播网络(包含特征提取器F、分类器C和域分类器D)的随机梯度下降更新。区别在于式(4.66)中增加了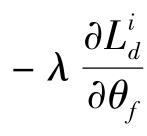 这一项。这一项使得特征提取器达到最优
这一项。这一项使得特征提取器达到最优![]() 时,域对抗损失达到最大,进而保证最优特征提取器学习的特征f具有域不变性。为了实现
时,域对抗损失达到最大,进而保证最优特征提取器学习的特征f具有域不变性。为了实现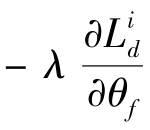 ,设计梯度反转层,将其嵌入特征提取器和域分类器之间。在网络前向传播过程中,梯度反转层不起任何作用。在网络反向传播中,梯度反转层将下层网络损失
,设计梯度反转层,将其嵌入特征提取器和域分类器之间。在网络前向传播过程中,梯度反转层不起任何作用。在网络反向传播中,梯度反转层将下层网络损失![]() 对上层网络参数θf的偏导
对上层网络参数θf的偏导![]() 乘以-λ得到
乘以-λ得到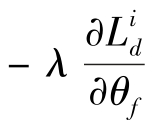 ,并将其传递到上层。
,并将其传递到上层。
在测试阶段,通过特征提取器F和分类器C,对目标域样本进行分类,即![]() ;θf);θy)。
;θf);θy)。
2.对抗判别域适应方法
在反向传播域适应方法首次将对抗思想引入域适应之后,基于对抗学习的域适应引起了人们的更多关注。Tzeng等[41]人提出了对抗域适应的通用框架,并基于此框架,提出了对抗判别域适应方法(adversarial discriminative domain adaptation,ADDA)。不同于反向传播域适应方法中源域和目标域的特征提取器是共享的,对抗判别域适应方法分别构建源域和目标域的特征提取器,并分阶段地进行特征的判别性学习和域不变性学习。在训练阶段,首先使用源域数据训练源域特征提取器和分类器,然后以对抗方式训练目标域特征提取器与域分类器。训练得到的目标域特征提取器能够将目标域样本映射到源域特征表示空间。在测试阶段,通过源域分类器和目标域特征提取器完成对目标域样本的分类。
1)对抗域适应通用框架
假设Xs为从源域数据分布ps(x,y)采样的源域样本,Ys为Xs的类别标签,Xt为从目标域数据分布pt(x)采样的目标域样本,对抗域适应的目标是学习目标域特征提取器Ft和目标域分类器Ct,用于目标域样本的分类。由于目标域数据缺乏标注,无法直接训练目标域分类器,因此,通常在源域上学习源域特征提取器Fs和源域分类器Cs,然后通过微调Fs和Cs使其适用于目标域任务。
对抗域适应方法通过对源域特征提取器Fs和目标域特征提取器Ft的学习过程进行约束,最小化源域特征分布Fs(Xs)和目标域特征分布Ft(Xt)之间的距离。当Fs(Xs)=Ft(Xt)时,源域分类器Cs可以直接用于目标域样本分类,不需要学习目标域分类器Ct。Fs(Xs)和Ft(Xt)之间的差异最小化通过特征提取器与域分类器D的对抗学习来实现。域分类器D的作用是判断输入样本是来自源域还是来自目标域,其目标是将源域样本和目标域样本正确分类。训练D的损失函数为
其中,源域样本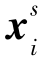 的域标签是0,目标域样本
的域标签是0,目标域样本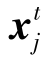 的域标签是1。在对抗学习过程中,特征提取器Fs和Ft负责学习使得源域样本和目标域样本不可区分的特征表示。换而言之,使用该特征表示,域分类器无法正确区分源域和目标域样本。训练Fs和Ft的损失函数表示为Lf(Fs,Ft,D)。因此,训练域分类器和特征提取器的优化目标为
的域标签是1。在对抗学习过程中,特征提取器Fs和Ft负责学习使得源域样本和目标域样本不可区分的特征表示。换而言之,使用该特征表示,域分类器无法正确区分源域和目标域样本。训练Fs和Ft的损失函数表示为Lf(Fs,Ft,D)。因此,训练域分类器和特征提取器的优化目标为
其中,ψ(Fs,Ft)为对源域特征提取器Fs和目标域特征提取器Ft的约束条件。
源域分类器Cs采用交叉熵损失训练,其优化目标为
其中,K=|Ys|表示源域数据的类别总数。
下面介绍对抗域适应通用框架的三个重要方面:基础模型选择、特征提取器优化、域对抗损失设计。
基础模型选择:对抗域适应方法通常采用的基础模型有判别式模型和生成式模型。判别式模型[32-33,40]是指学习具有判别性的特征空间,并减少源域和目标域样本在该空间的分布差异,使得源域分类器能够适应于目标域。生成式模型[42]是指通过生成对抗网络,生成与目标域样本相似的源域样本,进而将源域的监督信息迁移到目标域。
特征提取器优化:用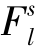 和
和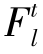 分别表示源域特征提取器Fs和目标域特征提取器Ft的第l层参数,l∈{1,2,…,n},则特征提取器的优化约束ψ(Fs,Ft)定义为
分别表示源域特征提取器Fs和目标域特征提取器Ft的第l层参数,l∈{1,2,…,n},则特征提取器的优化约束ψ(Fs,Ft)定义为
还可以对特征提取器的每层训练施加约束,一种常见的约束形式是强制Fs和Ft的对应网络层参数相等,即
式(4.75)约束可以通过在卷积神经网络中共享参数实现。在许多对抗域适应方法中[40,43],约束源域和目标域特征提取器的所有层均满足等式(4.75)定义的对等约束,即对称变换。学习对称变换可以减少模型参数量。但是,由于使用同一个网络处理来自两个不同域的样本,其优化过程不易实现,并且不易学到域特定信息。另一种约束方式是对Fs和Ft的部分层施加对等约束。这种部分对等约束允许源域和目标域特征提取器在共享部分网络参数的情况下,学习各自域的特定参数,能够捕捉到各自的域特定信息。一些域适应方法[32-33]均采用了这种约束,有效提高了模型的域适应性能。
域对抗损失设计:训练域分类器的对抗损失通常采用式(4.70)定义的对抗损失Ld(Fs,Ft,D)。对于不同的任务,Lf(Fs,Ft,D)的具体形式有所不同。比如,反向传播域适应方法通过梯度反转层对训练域分类器的损失乘以一个负标量来优化特征提取器,表示为Lf(Fs,Ft,D)=-Ld(Fs,Ft,D)。该优化采用极大极小策略,使域分类器很快收敛,最终导致梯度消失。Tzeng等人[43]提出了域混淆对抗损失来训练特征提取器,目标是让特征提取器学到的特征能够混淆域分类器,使其将目标域样本分类为来自源域、将源域样本分类为来自目标域。该域混淆对抗损失定义为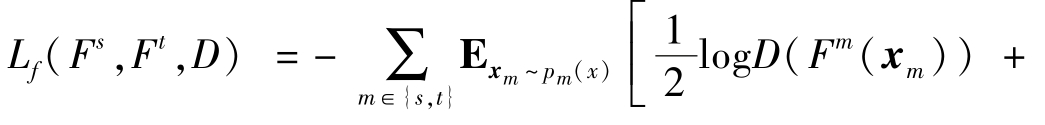
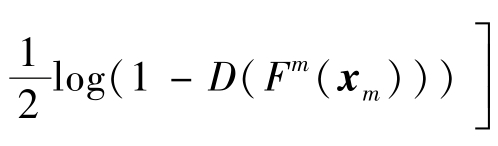 。
。
2)对抗判别域适应网络
基于上述对抗域适应通用框架,Tzeng等人[41]提出了对抗判别域适应方法。该方法采用判别式基础模型、部分参数共享的特征提取器以及生成对抗损失。
图4.16为对抗判别域适应方法的框架图。模型训练分为两个阶段。第一阶段为判别性特征学习,通过式(4.73)对源域特征提取器Fs和源域分类器Cs进行训练,得到源域的特征表示。第二阶段为域不变特征学习,固定源域特征提取器Fs,通过生成对抗损失对目标域特征提取器Ft和域分类器D进行训练,其优化问题为
图4.16 对抗判别域适应方法的框架图[41](https://www.daowen.com)
迭代进行式(4.76)与式(4.77),使得目标域特征空间逐渐与源域特征空间对齐,直至域分类器D无法区分源域样本和目标域样本。此时可以认为源域特征分布Fs(Xs)和目标域的特征分布Ft(Xt)一致,即Fs(Xs)=Ft(Xt)。在测试阶段,首先使用目标域特征提取器Ft提取输入测试样本的特征表示,然后通过源域分类器Cs对目标域样本进行分类。
3.生成对抗域适应方法
生成对抗域适应方法[44]利用特征提取器学习源域和目标域的共同特征空间,并通过生成对抗网络,将源域和目标域的数据分布信息传递到特征提取器的学习过程中,从而在联合特征空间最小化源域和目标域的特征分布距离,进而学得对域分布差异鲁棒的特征提取器。生成对抗域适应方法包括两个分支:一是分类分支,由特征提取器和分类器构成;二是对抗分支,由辅助分类器生成对抗网络(auxiliary classifier GAN,AC-GAN)[45]构成,具体包括生成器和多类判别器。不同于生成对抗网络中的判别器对样本的域标签进行预测,辅助分类器生成对抗网络中的多类判别器同时预测样本的域标签和类别标签。通过分类分支和对抗分支的联合训练,生成对抗域适应方法能够学习到既具有判别性又具有域不变性的特征表示。
1)网络结构
生成对抗域适应方法包括4个模块:特征提取器F、分类器C、生成器G和多类判别器D。图4.17为生成对抗域适应方法的框架。其中,特征提取器F提取源域和目标域样本的特征表示,其输入是源域样本或目标域样本,输出是输入样本的特征表示。分类器C预测输入样本的类别标签,其输入是样本x的特征表示F(x),输出是x属于Nc个类别的概率分布。生成器G用于生成样本,其输入xg是样本的特征表示F(x)、从N(0,1)分布采样的噪声向量z∈Rd以及类别标签的一位有效编码(one hot encoding)l的级联拼接,即xg=[F(x),z,l]。l是Nc+1维的向量,即![]() ,其前Nc维表示真实类别,对应源域的Nc个类别,其第Nc+1维表示样本是来自真实域还是来自生成域。对于源域样本
,其前Nc维表示真实类别,对应源域的Nc个类别,其第Nc+1维表示样本是来自真实域还是来自生成域。对于源域样本![]() 及其类别标签
及其类别标签![]() ,其l的第
,其l的第![]() 维为1,其余为0。由于目标域样本
维为1,其余为0。由于目标域样本![]() 没有类别标注,其l的第Nc+1维是1,其余为0。实际上,可以通过一位有效编码的Nc+1维,将有标注的源域样本标记为来自真实域,无标注的目标域样本标记为来自生成域。多类判别器D同时进行类别标签预测和域标签预测,其输入是真实样本x或生成样本G(xg),其输出包括两部分:输入样本来自真实域的概率Ddata(x)和输入样本的类别概率分布Dcls(x)。
没有类别标注,其l的第Nc+1维是1,其余为0。实际上,可以通过一位有效编码的Nc+1维,将有标注的源域样本标记为来自真实域,无标注的目标域样本标记为来自生成域。多类判别器D同时进行类别标签预测和域标签预测,其输入是真实样本x或生成样本G(xg),其输出包括两部分:输入样本来自真实域的概率Ddata(x)和输入样本的类别概率分布Dcls(x)。
图4.17 生成对抗域适应方法的框架[44]
特征提取器F和分类器C构成的分类分支,与生成器G和多类判别器D构成的对抗分支联合训练,将域信息传播到特征提取器的优化过程中,从而保证学习的特征表示既具备有利于分类的判别性又具备有利于迁移的域不变性。
2)网络训练
为了联合学习分类分支与对抗分支,生成对抗域适应方法采用迭代优化的方式,对多类判别器D、生成器G、特征提取器F和分类器C进行更新。设![]() 为从源域分布ps(x,y)采样的源域样本,
为从源域分布ps(x,y)采样的源域样本,![]() 为其类别标签,
为其类别标签,![]() 为从目标域分布pt(x)采样的目标域样本。
为从目标域分布pt(x)采样的目标域样本。
给定源域样本![]() 、类别标签
、类别标签![]() ,多类判别器D的优化目标是:将生成样本G(xg)预测为来自生成域,将源域样本
,多类判别器D的优化目标是:将生成样本G(xg)预测为来自生成域,将源域样本![]() 预测为来自真实域且同时将
预测为来自真实域且同时将![]() 分类到对应的类别
分类到对应的类别![]() ,即
,即
其中,![]() 表示样本
表示样本![]() 被多类判别器D预测为类别
被多类判别器D预测为类别![]() 的概率。生成器G的优化目标是:使多类判别器D将生成的源域样本G(xg)判别为来自真实域,并将其分类到与源域样本相同的真实类别
的概率。生成器G的优化目标是:使多类判别器D将生成的源域样本G(xg)判别为来自真实域,并将其分类到与源域样本相同的真实类别![]() ,即
,即
根据源域样本和其类别标签,采用交叉熵损失特征提取器F和分类器C进行更新。特征提取器F的优化目标是混淆多类判别器D,即使D将生成的源域样本判别为来自真实域并属于类别![]() ,以此实现特征学习和样本生成的联合优化。特征提取器F和分类器C的具体优化目标为
,以此实现特征学习和样本生成的联合优化。特征提取器F和分类器C的具体优化目标为
其中,![]() 表示样本
表示样本![]() 被分类器C预测为类别
被分类器C预测为类别![]() 的概率;α表示源域分类损失LC和对抗损失LF,S的平衡系数。
的概率;α表示源域分类损失LC和对抗损失LF,S的平衡系数。
给定目标域样本![]() ,由于目标域没有类别标注信息,只采用判别器D预测的样本来自真实域的概率计算损失。多类判别器D的优化目标是将生成的目标域样本判别为来自生成域,即
,由于目标域没有类别标注信息,只采用判别器D预测的样本来自真实域的概率计算损失。多类判别器D的优化目标是将生成的目标域样本判别为来自生成域,即
为了能够将目标域数据分布的知识迁移到特征学习过程中,更新特征提取器F来混淆多类判别器D,使其将生成的目标域样本判别为来自真实域,即
其中,β为目标域的对抗损失LF,T的权重系数。
在测试阶段,将学得的特征提取器F和分类器C组合起来,完成对目标域样本的分类。
4.域对称对抗域适应方法
本书前面介绍的反向传播域适应方法、对抗判别域适应方法和生成对抗域适应方法均通过学习域不变的特征表示,将源域和目标域的特征分布进行对齐,取得了显著的性能提升。我们称这种对齐为特征级域对齐,然而,在对齐特征分布时忽略了数据的类别信息,导致源域和目标域的“特征-类别”的联合分布仍然存在差异。为解决这个问题,一些工作[46-48]对目标域样本预测其伪标签以实现类别级的域对齐,即对齐属于相同类别的源域和目标域样本的特征分布。还有一些工作[49-50]将特征表示和类别之间的映射建模为高阶特征表示以促进特征提取器和域分类器的对抗训练,其中的代表性工作是Zhang等人[51]提出的域对称对抗域适应方法。该方法基于结构对称的源域和目标域分类器,构建与分类器参数共享的域分类器,借助特征级域对齐和类别级域对齐,实现源域和目标域的“特征-类别”联合分布的一致性。为同时进行特征级域对齐和类别级域对齐,在域级域混淆损失(也就是前面所述的对抗损失)的基础上增加了类别级域混淆损失,被称为两级域混淆损失,在学习域特征不变的同时更好地保留特征的判别性质。
1)对称分类器
域对称对抗域适应方法包括3个模块:特征提取器F、源域分类器Cs和目标域分类器Ct,如图4.18所示。Cs和Ct的结构是对称的,均由带有softmax激活函数的K个节点的全连接层组成,K等于类别数量。Cs和Ct的输入是由特征提取器F提取的样本特征表示F(x),输出是F(x)的类别概率分布,分别表示为Cs(F(x))=ps(x)∈[0,1]K和Ct(F(x))=pt(x)∈[0,1]K。基于源域分类器Cs和目标域分类器Ct,构建分类器Cst,其设定如下。分类器Cst的输入是F(x),输出是F(x)在源域类别和目标域类别上的概率分布,表示为Cst(F(x))=pst(x)∈[0,1]2K。pst(x)根据Cs和Ct的输出计算得到,过程如下:Cs和Ct在经过softmax激活函数之前的输出向量表示为vs(x)∈RK和vt(x)∈RK,将这两者拼接得到2K维的向量,即[vs(x);vt(x)]∈R2K。将该向量输入softmax激活函数,得到样本x的类别概率分布pst(x)。
图4.18 域对称对抗域适应[51]
设![]() 和
和![]() 分别表示ps(x)、pt(x)和pst(x)的第k维元素,其含义为输入样本x分别被分类器Cs、Ct和Cst预测为第k类的概率。设
分别表示ps(x)、pt(x)和pst(x)的第k维元素,其含义为输入样本x分别被分类器Cs、Ct和Cst预测为第k类的概率。设![]() 为源域,Dt
为源域,Dt![]() 为目标域,根据源域样本及其类别标签,采用交叉熵损失对源域分类器Cs进行训练,其优化目标为
为目标域,根据源域样本及其类别标签,采用交叉熵损失对源域分类器Cs进行训练,其优化目标为
因为目标域数据是无标注的,所以利用有标注的源域数据来训练目标域分类器Ct,其优化目标为
从式(4.84)和式(4.85)的形式上看,目标域分类器Ct是源域分类器Cs的复制。但由于分类器Cst依赖于Cs和Ct的输出,通过分类器Cst的训练,能够使得Cs和Ct的输出具有区分性。所以,式(4.84)和式(4.85)实际上建立了源域分类器Cs和目标域分类器Ct在类别上的对应关系,因为Cs和Ct输出向量的第k维(即![]() 和
和![]() )均表示样本x属于类别k的概率。采用交叉熵损失来训练分类器Cst,其优化目标为
)均表示样本x属于类别k的概率。采用交叉熵损失来训练分类器Cst,其优化目标为
其中,![]() 表示输入样本
表示输入样本![]() 被预测为来自源域的概率;
被预测为来自源域的概率;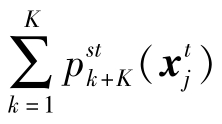 表示输入样本
表示输入样本![]() 被预测为来自目标域的概率。分类器Cst的功能实际上与一般的域分类器相同,用于区分源域样本和目标域样本。区别在于Cst不是实际存在的,而是通过Cs和Ct的输出构建的。因此,对Cst的更新等价于对Cs和Ct的更新。
被预测为来自目标域的概率。分类器Cst的功能实际上与一般的域分类器相同,用于区分源域样本和目标域样本。区别在于Cst不是实际存在的,而是通过Cs和Ct的输出构建的。因此,对Cst的更新等价于对Cs和Ct的更新。
理想情况下,在分类器Cst输出的2K维向量中,前K维向量对应源域分类器Cs的输出,后K维向量对应目标域分类器Ct的输出。通过式(4.84)、式(4.85)和式(4.86)的优化,分类器Cst输出的前K维向量和后K维向量均具有类别区分性。同时前K个元素之和与后K个元素之都能体现输入样本的域信息。例如,对于第k类的源域样本![]() ,Ct和Cs均倾向于做出正确的预测,Cst的输出概率
,Ct和Cs均倾向于做出正确的预测,Cst的输出概率![]() 倾向于大于
倾向于大于![]() 。而对于第k类的目标域样本
。而对于第k类的目标域样本![]() ,Ct和Cs也均倾向于做出正确的预测,Cst的输出概率
,Ct和Cs也均倾向于做出正确的预测,Cst的输出概率![]() 倾向于大于
倾向于大于![]() 。
。
2)两级域混淆损失函数
两级域混淆损失函数包括类别级域混淆损失和域级域混淆损失。类别级域混淆损失需要利用源域的类别信息。对于第k类的源域样本,根据分类器Cst中的第k个和第k+K个神经元输出(即样本属于第k个类别的概率值),利用交叉熵损失训练特征提取器F,其优化目标为
对于目标域样本,根据分类器Cst的前k个神经元的输出之和(即样本属于源域的概率值)以及后k个神经元的输出之和(即样本属于目标域的概率值),利用交叉熵损失训练特征提取器F,其优化目标为
为使目标域数据各类之间尽可能分开,基于熵最小化原理,对分类器Cst预测的类别概率分布进行约束。这样的约束使预测出的类别概率分布信息熵最小以保证属于不同类别的概率具有区分性:
其中,![]() 。根据文献[52]中的研究,熵最小化原则只作用于特征提取器F的更新,不作用于Cst的更新。这样做可以避免由于源域和目标域分布差异的存在而出现的早期错误分类引起的噪声问题。因此,域对称对抗域适应方法总的优化目标为
。根据文献[52]中的研究,熵最小化原则只作用于特征提取器F的更新,不作用于Cst的更新。这样做可以避免由于源域和目标域分布差异的存在而出现的早期错误分类引起的噪声问题。因此,域对称对抗域适应方法总的优化目标为
其中,λ∈[0,1]为平衡系数。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






