根据迁移学习模型的具体假设,现有相关工作可以划分为三种方法:模型控制策略(model control strategy)、参数控制策略(parameter control strategy)和模型集成策略(model ensemble strategy)。
1.模型控制策略
模型控制策略通过利用源域中的模型成分来确定目标域模型。此类方法基于对于数据分布概率的一些先验假设进行,如利用高斯过程的迁移学习,利用贝叶斯模型的知识迁移。如图3.6所示。
模型上的共享知识也可以通过正则化在源域和目标域间进行知识迁移。正则化是一种解决不适定的机器学习问题的技术,也是一种通过限制模型灵活性来防止模型过拟合的技术。在该类方法中,在一些先验假设下,正则化约束了模型的超参数。其中,SVM由于具有良好的计算性能以及在一些应用中有良好的预测表现,目前已被广泛应用于正则化的知识迁移中。在学习模型中,一些方法将模型参数从辅助任务转移到预先训练的深度模型中,作为目标域模型的初始化参数。Duan等人[22-23]提出了一种通用框架,称为域适应机器,该框架用于多源迁移学习。DAM的目标是利用在多个源域上分别训练得到的一些预先获得的基础分类器(base classifiers),为目标域构造一个鲁棒分类器。它的目标函数为
图3.6 模型迁移
第一项损失函数用于最小化有标签目标域样本的分类器损失,第二项表示不同的正则分类器,第三项用于控制最终决策函数f T的复杂度。LT,L(f T)可以采用不同类型的损失函数,可以是平方损失函数,也可以是交叉熵损失函数。一些迁移学习方法在一定程度上可以看作是该框架的特例。
一致性正则化器(consensus regularizer):Luo等人[24]提出了一个框架,称为一致性正则化框架(consensus regularization framework,CRF)。CRF是专为无标签目标域样本的多源转移学习设计的。该框架构建了对应于每个源域的mS分类器,这些分类器需要在目标域上达成一致。每个源分类器的目标函数定义为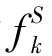 ,其中k=1,…,mS。源分类器的目标函数与DAM相似,定义为
,其中k=1,…,mS。源分类器的目标函数与DAM相似,定义为
其中,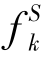 为第k个源域对应的决策函数S(x)=-xlogx。第一项用于量化第k个分类器在第k个源域上的分类误差,最后一项是交叉熵形式的一致性正则化器。一致性正则化器不仅提高了各分类器的一致性,而且降低了在目标域上预测结果的不确定性。DAM与CRF的不同之处在于,DAM明确地构建了目标分类器,而CRF则根据源分类器达成的共识来进行目标预测。
为第k个源域对应的决策函数S(x)=-xlogx。第一项用于量化第k个分类器在第k个源域上的分类误差,最后一项是交叉熵形式的一致性正则化器。一致性正则化器不仅提高了各分类器的一致性,而且降低了在目标域上预测结果的不确定性。DAM与CRF的不同之处在于,DAM明确地构建了目标分类器,而CRF则根据源分类器达成的共识来进行目标预测。
域依赖正则化器(domain-dependent regularizer):Fast-DAM是DAM的一种具体算法[22]。根据流形假设[4]和基于图的正则化[25-26],Fast-DAM设计了一个域相关的正则化器。目标函数为
其中,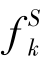 ,(k=1,2…,mS)为预先得到的第k个源域的源决策函数,βk代表由目标域和第k个源域之间的相关性所确定的权重参数,可以使用基于MMD的度量方式来进行计算。第三项是域依赖正则约束,这个约束可以通过域之间的依赖关系对源域分类中的知识进行迁移。文献[22]还在上述基于对ε不敏感损失函数(ε-insensitive loss function)中引入并添加了一个新项[27],使所得模型具有较高的计算效率。域依赖正则化器迁移的是由域依赖激发的源分类器中包含的知识。
,(k=1,2…,mS)为预先得到的第k个源域的源决策函数,βk代表由目标域和第k个源域之间的相关性所确定的权重参数,可以使用基于MMD的度量方式来进行计算。第三项是域依赖正则约束,这个约束可以通过域之间的依赖关系对源域分类中的知识进行迁移。文献[22]还在上述基于对ε不敏感损失函数(ε-insensitive loss function)中引入并添加了一个新项[27],使所得模型具有较高的计算效率。域依赖正则化器迁移的是由域依赖激发的源分类器中包含的知识。
域依赖的正则化器+Universum正则化器(domain-dependent regularizer+Universum regularizer):Univer-DAM是Fast-DAM的扩展[23],它的目标函数包含一个额外的正则化器,即Universum正则化器(Universum regularizer)[28]。这个正则化器通常使用一个附加的Universum数据集,这个数据集中的样本既不属于正类也不属于负类,在这个方法中会把源域样本视为目标域的Universum,Univer-DAM的目标函数如下所示:
与Fast-DAM类似,Univer-DAM可以利用ε不敏感损失函数[23]进行约束。
2.参数控制策略
在使用模型共享的方法时,一种直观的控制参数的方法是直接将源域模型的参数共享给目标域模型。参数共享被广泛应用于基于网络的方法中。例如,如果我们有一个用于源任务的神经网络,我们可以共享它大部分的层,只调整最后几个层来生成目标网络。
除了基于网络的参数共享外,基于矩阵分解的参数共享(matrix-factorization-based parameter sharing)也是可行的。例如,Zhuang等人[29]提出了一种文本分类方法(matrix trifactorization based classification framework,MTrick)。在该方法中会发现,在不同的域中,不同的词或短语有时表达相同或相似的语义。因此,使用单词背后的概念比使用单词本身作为源域知识传递的桥梁更有效。基于概率隐语义分析(the probabilistic latent semantic analysis,PLSA)[30]的迁移学习方法通过构造贝叶斯网络来利用这些概念,与它不同,MTrick试图通过矩阵三因式分解来找到文档类(document classes)和词簇(word clusters)所表达的概念之间的联系。这些联系被认为是应该被迁移的稳定知识。具体而言,分别对源域和目标域文档到单词矩阵进行矩阵三因式分解,构造出一个联合优化问题:
其中,X为文档-单词矩阵(document-to-word matrix);Q为文档-聚类矩阵(documentto-cluster matrix);R为文档聚类-单词聚类的变换矩阵(the transformation matrix from document clusters to word clusters);W为聚类-单词矩阵(cluster-to-word matrix);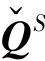 为标签矩阵。矩阵
为标签矩阵。矩阵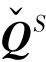 的构造基于源域文档的类信息。如果第i个文档属于第k个类,则
的构造基于源域文档的类信息。如果第i个文档属于第k个类,则![]() 1。在上述目标函数中,矩阵R为共享参数。第一项旨在对源域中文档到单词矩阵进行三因式分解,第二项分解目标域中文档-单词矩阵,最后一项包含了源域标签信息,其采用交替迭代法求解优化问题。一旦得到QT的解,第k个目标域样本的类别就是QT的第k行中取值最大的类别。
1。在上述目标函数中,矩阵R为共享参数。第一项旨在对源域中文档到单词矩阵进行三因式分解,第二项分解目标域中文档-单词矩阵,最后一项包含了源域标签信息,其采用交替迭代法求解优化问题。一旦得到QT的解,第k个目标域样本的类别就是QT的第k行中取值最大的类别。
此外,Zhuang等人[31]对MTrick进行了扩展,并提出了一种称为三形迁移学习(triplex transfer learning,TriTL)的方法。MTrick假设这些域在它们的词簇背后共享相似的概念。与这一点不同的是,TriTL假设这些域的概念可以进一步划分为三类,即域无关语义、可迁移域语义和不可迁移域语义,这与HIDC类似。这种想法是由双重转移学习(DTL)激发的,其中的概念假定由域无关语义和可迁移域语义组成[32]。TriTL的目标函数如下:(https://www.daowen.com)
其中,符号的定义类似于MTrick的定义,下标k表示域的索引,假设第一个mS是源域,最后一个mT是目标域。这是一种求解优化问题的迭代算法,初始化阶段根据PLSA算法的聚类结果对WDI和![]() 进行初始化,与此同时,
进行初始化,与此同时,![]() 进行随机初始化,PLSA算法是在所有域样本的组合上执行的。
进行随机初始化,PLSA算法是在所有域样本的组合上执行的。
Zhuang等[31]将TriTL与一些最先进的基线方法[LR(logistic regression)、SVM、TSVM(transductive support vector machine)、CoCC(co-clustering based classification)、DTL(dual transfer learning)和MTrick]在数据集rec和sci上进行比较,144个分类任务的所有结果记录在图3.7和表3.5中。在图3.7中,这144个任务是按照LR性能的递增顺序排序的。LR的准确率较低,说明从源域到目标域的知识转移较困难。该实验把这些分类任务分为两部分,图3.7中红色虚线左侧表示LR准确率低于65%的问题,右侧表示LR准确率高于65%的问题。表3.5列出了相应的平均性能。从这些结果中,我们有以下发现。TriTL明显优于监督学习算法LR和SVM,以及半监督方法TSVM。通过统计检验,TriTL显著优于所有比较迁移学习算法CoCC、MTrick和DTL。在表3.5中,无论LR准确率低于或高于65%的分类任务,TriTL的平均性能都是最好的。
图3.7 性能比较[31](见彩插)
(a)TriTL和LR、SVM、TSVM相比
图3.7 性能比较[31](见彩插)(续)
(b)TriTL和CoCC、DTL、MTrick相比
表3.5 数据集rec与sci的144个任务的平均性能[31]
3.模型集成策略
模型集成是另一个常用的策略。该策略的目的是结合大量的弱分类器来进行最终的预测。例如,TrAdaBoost[5]和MsTrAdaBoost[7]分别通过投票和加权来集成弱分类器。以下列出几种典型的嵌入式的迁移学习方法(ensemble-based transfer learning),以帮助读者更好地理解这种策略的功能和应用。
TaskTrAdaBoost[7]是TrAdaBoost的扩展,用于处理多源场景。TaskTrAdaBoost主要有以下两个阶段。
(1)候选分类器构造:通过对每个源域进行AdaBoost来构造一组候选分类器。注意对于每个源域,AdaBoost的每次迭代都会产生一个新的弱分类器。为了避免过拟合问题,此方法引入了一个阈值来选择合适的分类器到候选组中。
(2)分类器选择与集成:在目标域样本上执行AdaBoost的修订版本,构建最终的分类器。在每一次迭代中,挑选出一个在目标域有标签的16个样本上分类误差最小的最优候选分类器,并根据分类误差分配权重。然后,根据所选分类器在目标域中的性能更新每个目标域样本的权值。在迭代过程中,选择的分类器被集成,以产生最终的预测。
原始AdaBoost与第二阶段TaskTrAdaBoost的区别在于,在每次迭代中,前者在加权的目标域样本上构造一个新的候选分类器,而后者在加权的目标域样本上选择一个预先获得的分类误差最小的候选分类器。
如图3.8所示,Yao和Doretto[7]比较了基于ROC曲线的分类器的性能。当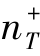 =50时,所有的分类器性能相差无几。当
=50时,所有的分类器性能相差无几。当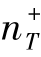 减少变为1时,可以观察到显著的性能差异。他们所提出的方法可以有效地利用多个资源之间的决策边界,并且性能优于TrAdaBoost。TaskTrAdaBoost第二阶段降低了时间复杂度,这使得它很适合那些需要快速再训练以检测新目标的应用程序。
减少变为1时,可以观察到显著的性能差异。他们所提出的方法可以有效地利用多个资源之间的决策边界,并且性能优于TrAdaBoost。TaskTrAdaBoost第二阶段降低了时间复杂度,这使得它很适合那些需要快速再训练以检测新目标的应用程序。
图3.8 两方法的性能比较[7](见彩插)
(a)序列A;(b)序列B
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





