1.为源域样本分配权重
基于样本的直推式迁移学习:当特征的边缘分布不同但条件概率相同时,问题可以被定义为直推式迁移学习。首先考虑一个简单的场景,其中有大量有标签的源域样本和有限数量的目标域样本可用,域仅在边缘分布上有所不同,即![]() 和
和![]() 。在这种情况下,考虑调整边缘分布。一个简单的想法是在损失函数中为源域样本分配权重。加权策略基于方程[1]
。在这种情况下,考虑调整边缘分布。一个简单的想法是在损失函数中为源域样本分配权重。加权策略基于方程[1]
因此,学习任务的一般目标函数可以写成[1]
其中,βi(i=1,2…,nS)为权重参数。βi的理论值等于PT(xi)/PS(xi),然而,这一比例通常是未知的,难以用传统方法得到。
KMM算法[1]是通过在RKHS中匹配源域和目标域样本的均值,解决了在RKHS中上述未知比值的估计问题,即
其中,δ为一个极小值参数;B为一个约束参数。通过对上述优化问题进行展开并利用核方法,可以将其转化为二次优化问题。这种估计分布比率的方法可以简单地融入许多现有的分类或回归算法中。一旦获得权重βi,就可以在加权的源域样本上训练模型。
KMM算法在乳腺癌数据集(breast cancer dataset)上进行实验验证。该数据集包含669个样本,这些样本分为良性和恶性两类。在该数据集上的测试结果如图3.2所示。图3.2(a)中的结果表明KMM始终优于非加权情况,并且匹配或超过使用已知分布比例获得的性能。图3.2(b)中,KMM的性能同样优于非加权情况,并且与使用抽样模型重新加权一样好或更好。图3.2(c)显示了不同训练/测试分割比例下的平均性能,尽管不符合实验对训练分布和测试分布之间差异的假设,KMM仍然具有更高的测试性能,并且在训练集样本数量较大的情况下优于按密度比率调整权重的方法。
图3.2 KMM实验测试结果[1]
(a)特征上的单一偏差;(b)特征上的联合偏差;(c)标签上的偏差
2.估算权重
另一些研究尝试估算权重。例如,Kullback-Leibler重要度估计处理(Kullback-Leibler importance estimation procedure,KLIEP)[2]方法依赖于Kullback-Leibler(KL)散度的最小化,它还包含了一个内置的模型选择过程,这使得这种方法更加有用和可靠。在研究权值估计的基础上,基于样本的迁移学习框架或算法也被提出。例如,Sun等人[3]提出了多源转移学习框架,称为多源域适应的两阶段加权框架(2-stage weighting framework for multi-source domain adaptation,2SW-MDA),具体如下。
(1)样本权重:在第一阶段,对源域样本进行权值分配,以减少边缘分布差异,类似于KMM。
(2)域权重(domain weight):在第二阶段,基于平滑度假设[4],对每个源域根据平滑假设进行加权以减小条件分布差异。
根据样本权重和域权重对源域样本进行重新加权。这些重新加权的样本和有标签的目标域样本用于训练目标分类器。2SW-MDA采用两阶段加权操作,可以降低边界差和条件差。
该方法在3个真实数据集上进行测试,这3个真实数据集分别是新闻组数据集(newsgroups dataset)、情绪分析数据集(sentiment analysis dataset)以及一个从表面肌电图(surface electromyogram,SEMG)信号提取的表面肌电数据集。新闻组数据集是大约20 000个新闻组文档的集合,包含20个类别。情绪分析数据集包含对4个类别(包括厨房、书籍、DVD和电子产品)的正面评论和负面评论。表面肌电数据集是由表面肌电生理信号衍生的12维时频域特征。表面肌电信号是利用表面电极从受试者肌肉中记录下来的生物信号,用于研究受试者的肌肉骨骼活动,从而对应了不同程度的疲劳。为了评估方法的有效性,表3.1将2SW-MDA与基线方法SVM-C以及五种域自适应方法[LWE(kernal ensemble),KE(locally weighted ensemble),KMM,TCA,DAM]进行了比较。由表3.1可观察到,2SW-MDA方法优于其他域适应方法,在大多数情况下,特别是对于SEMG数据集,可以获得更高的分类精度。
表3.1 在3个真实数据集和一个虚构数据集上比较不同方法的分类准确率[3] 单位:%
3.迭代调整权重
除了直接估算权重参数外,迭代调整权重(adjusting weights iteratively)也是有效的。迭代调整权重的关键是设计一种机制来减少对目标模型产生负面影响的样本的权重。一个代表性的产物是TrAdaBoost[5],它是一个由Dai等人提出的框架。这个框架是AdaBoost[6]的扩展。AdaBoost是一种针对传统机器学习任务设计的有效的增强算法。在AdaBoost的每次迭代中,要学习的分类器模型都是在权重更新的样本上训练的,这导致了分类器的效果不佳,即弱分类器。样本的权重机制会对分类不正确的样本给予更多的关注。最后,其将得到的弱分类器组合成强分类器。TrAdaBoost将AdaBoost扩展到迁移学习场景,设计了一种新的权重分配机制,以减少分布差异的影响。具体来说,在TrAdaBoost中,将有标签的源域样本和没有标签的目标域样本组合为一个整体,即一个训练集来训练弱分类器。对于源域样本和目标域样本,权重机制是不同的。在每次迭代中,计算一个临时变量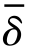 (衡量目标域样本的分类错误率)。然后,目标域样本的权重根据
(衡量目标域样本的分类错误率)。然后,目标域样本的权重根据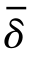 和单个分类结果进行更新,而源域样本的权重根据设计的常量和单个分类结果更新。为了更好地理解,在第k次迭代(k=1,…,N)中用于更新权重的公式重复表示如下[5]:
和单个分类结果进行更新,而源域样本的权重根据设计的常量和单个分类结果更新。为了更好地理解,在第k次迭代(k=1,…,N)中用于更新权重的公式重复表示如下[5]:
请注意,每次迭代都会形成一个新的弱分类器。通过投票的方式将新生成的弱分类器的一半进行组合和集成,从而得到最终的分类器。多源TrAdaBoost(multi-source AdaBoost,MsTrAdaBoost)[7]方法进一步扩展了TrAdaBoost。该方法设计用于多源迁移学习,每次迭代主要有以下两步。
(1)候选分类器构造(candidate classifier construction):在每个源域和目标域正确的加权样本上分别训练一组候选弱分类器,即DSi∪DT(i=1,…,mS)。
(2)样本加权:选择目标域样本上分类错误率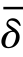 最小的分类器(用j表示),然后用于更新
最小的分类器(用j表示),然后用于更新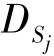 和DT中样本的权重。最后,将每次迭代中选择的分类器组合起来,形成最终的分类器。
和DT中样本的权重。最后,将每次迭代中选择的分类器组合起来,形成最终的分类器。
MsTrAdaBoost使用了Caltech-256数据集进行目标识别,该数据集包含256个目标类别;另外还使用了通过谷歌图像搜索引擎收集的背景数据集,以及其他类别作为增强背景数据集。对于每一个实验,把分类器输出的ROC(接受者操作特性)曲线用于性能比较,且将ROC曲线下面积AROC作为定量绩效评价。图3.3比较了AdaBoost、TrAdaBoost、MsTrAdaBoost、TaskTrAdaBoost在不同数量的目标正训练样本数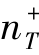 ∈{1,5,15,50}和源域N∈{1,2,3,5}的ROC曲线下面积。图3.3(a)假设N=3,并显示了当
∈{1,5,15,50}和源域N∈{1,2,3,5}的ROC曲线下面积。图3.3(a)假设N=3,并显示了当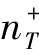 提高时算法的表现。由于AdaBoost不会从源头转移任何知识,它的性能严重依赖于
提高时算法的表现。由于AdaBoost不会从源头转移任何知识,它的性能严重依赖于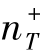 ,根据AROC的结果,一个非常小的
,根据AROC的结果,一个非常小的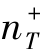 的性能略好于随机概率。TrAdaBoost联合学习3个源域中的知识,并在AdaBoost基础上改进了迁移学习机制。通过合并来自多个领域知识转移的能力,即使是对于一个很小的
的性能略好于随机概率。TrAdaBoost联合学习3个源域中的知识,并在AdaBoost基础上改进了迁移学习机制。通过合并来自多个领域知识转移的能力,即使是对于一个很小的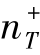 ,MsTrAdaBoost也显著提高了识别精度。此外,AdaBoost和TrAdaBoost算法的性能很大程度上取决于源域和目标域所选择的正样本。正如预期的那样,随着
,MsTrAdaBoost也显著提高了识别精度。此外,AdaBoost和TrAdaBoost算法的性能很大程度上取决于源域和目标域所选择的正样本。正如预期的那样,随着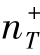 的提高,所有方法之间的性能差距都会缩小。当
的提高,所有方法之间的性能差距都会缩小。当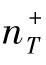 =50时,对于具有有限的测试正样本的给定数据集,它们显示出显著的下降。图3.3(b)假设N=1。结果表明,MsTrAdaBoost还原为TrAdaBoost,因此它们具有相同的性能。
=50时,对于具有有限的测试正样本的给定数据集,它们显示出显著的下降。图3.3(b)假设N=1。结果表明,MsTrAdaBoost还原为TrAdaBoost,因此它们具有相同的性能。
图3.3 Adaboost、TrAdaBoost、MSTrAdaBoost以及TaskTrAdaBoost方法的性能比较[7](https://www.daowen.com)
(a)假设N=3;(b)假设N=1
4.启发式方法实现样本加权策略
一些方法采用启发式方法实现样本加权策略。例如,在用于样本适应的通用权重框架中,使用如下三种类型的样本来构造目标分类器,且目标函数中有3个根据样本类型设计的目标项,目的是使交叉熵损失最小。
(1)带标签的目标域样本:分类器最小化它们的交叉熵损失,这实际上是一个标准的监督学习任务。
(2)不带标签的目标域样本:这些样本的真实条件分布![]() 是未知的,需要估计。一种可能的解决方案是在有标签的源域和目标域样本上训练辅助分类器,以帮助估计条件分布或为这些样本分配伪标签。
是未知的,需要估计。一种可能的解决方案是在有标签的源域和目标域样本上训练辅助分类器,以帮助估计条件分布或为这些样本分配伪标签。
(3)带标签的源域样本:将![]() 的权重定义为两个部分的乘积,即αi和βi。理想情况下,权重βi等于PT(xi)/PS(xi),可以用非参数方法估计,如KMM,也可以在最坏情况下统一设置。权重αi用于过滤出与目标域有很大差异的源域样本。αi的值可以由一种启发式方法来产生得到,其中包含以下三个步骤。
的权重定义为两个部分的乘积,即αi和βi。理想情况下,权重βi等于PT(xi)/PS(xi),可以用非参数方法估计,如KMM,也可以在最坏情况下统一设置。权重αi用于过滤出与目标域有很大差异的源域样本。αi的值可以由一种启发式方法来产生得到,其中包含以下三个步骤。
①辅助分类器构造(auxiliary classifier construction):使用在有标签的目标域样本上训练的辅助分类器对没有标签的源域样本进行分类。
②样本排序(sample ranking):根据概率预测结果对源域样本进行排序。
③启发式加权法(heuristic weighting βi):预测错误的top-k源域样本(the top-k source-domain instances)的权重设置为0,其他样本的权重设置为1。
该框架的目标函数由四个部分组成,即包含三类样本的损失函数,以及一个正则化项控制模型的复杂度。
Jiang等[8]选择3个不同的NLP任务来评估样本加权方法的域适应能力。第一个任务是词性标注,使用了来自Penn Treebank语料库的00节和01节的6 166个华尔街日报(WSJ)语句作为源域数据,以及来自PennBioIE语料库肿瘤学章节的2 730个PubMed句子作为目标域数据。第二个任务是实体类型分类。假设实体边界已被正确识别,希望对实体的类型进行分类,为此使用ACE 2005训练数据来完成这项任务。对于源域,使用了新闻专线语料集合,其中包含11 256个示例;对于目标域使用了博客语料集合(5 164个示例)和对话性电话语音(CTS)集合(4 868个示例)。第三个任务是个性化垃圾邮件过滤。为此使用了ECML/PKDD 2006发现挑战数据集(http://ceas2009.cc/)。源域包含4 000封公开来源的垃圾邮件和非垃圾邮件,目标域是3个个人用户的收件箱,每个收件箱包含2 500封邮件。
第一组实验中使用仅有的少量带标记的目标样本,逐步从源域删除带有“误导”标签的样本,这个过程遵循启发式加权法。该方法使用所有具有同等权重的源样本,但不使用目标样本,将其与基线方法进行比较。结果如表3.2所示。从表3.2中可以看到,在大多数实验中,删除这些预测的“误导”样本可以提高基准的性能。在一些实验中(肿瘤学、CTS、u00、u01)当所有错误分类的源样本被删除时,改进最大。然而,在weblog NE类型分类的情况下,删除源样本会损害性能。原因可能是实验使用的有标签的目标样本集是来自目标领域的有偏差的样本,因此在这些样本上训练的模型并不总是能够很好地预测“误导”源样本。
表3.2 删除“误导”源域样本后,目标域上的精确性[8]
第二组实验是将已标记的目标域样本添加到训练集中,这相当于设置了一些非零值,但仍保留了一些非零值。如表3.3所示,添加一些标记的目标样本可以极大地提高所有任务的性能。在几乎所有情况下,将目标样本加权到比源样本多的位置要比将它们平均加权更好。
表3.3 添加标记目标样本后未标记目标样本的准确性[8]
续表
5.生成式零样本学习
生成式零样本学习也可以认为是基于样本的迁移学习的一种。在零样本学习中,特征空间中有一些带标签的训练样本,这些训练样本属于可见类(seen class)。在特征空间中,还有一些没有标签的测试样本,它们属于另一组类,这一组类被称为不可见类(unseen class)。特征空间通常是一个实数空间,每个样本都被表示为其中的一个向量。通常假设一个样本属于一个类。零样本学习的定义如下:![]() 表示可见类的集合,其中每个
表示可见类的集合,其中每个![]() 表示一个可见类。
表示一个可见类。![]() 为不可见类的集合,其中每个
为不可见类的集合,其中每个![]() 表示一个不可见类。注意S∩U=Ø。X为D维的特征空间,它通常是一个实数空间Rd。定义Dtr
表示一个不可见类。注意S∩U=Ø。X为D维的特征空间,它通常是一个实数空间Rd。定义Dtr![]() 为可见类的有标签训练样本的集合。对于每个有标签的样本
为可见类的有标签训练样本的集合。对于每个有标签的样本![]() ,
,![]() 来说,
来说,![]() 是特征空间的样本,
是特征空间的样本,![]() 是该样本对应的类标签。定义
是该样本对应的类标签。定义![]() 为测试样本的集合,其中每个
为测试样本的集合,其中每个![]() 是特征空间中的一个测试样本。定义
是特征空间中的一个测试样本。定义![]() 作为样本集合Xte的待预测的类标签。
作为样本集合Xte的待预测的类标签。
零样本学习:有标签训练样本Dtr属于可见类S,零样本学习的目标是学习一个分类器fu(·):X→U,该分类器的作用是分出测试样本Xte是属于哪个不可见类U,即预测测试样本的标签Yte。
由定义可知,零样本学习的一般思想是将训练样本中包含的知识迁移到测试样本分类的任务中。训练样本和测试样本所覆盖的标签空间是不相交的。因此,零样本学习是迁移学习的一个子域[9]。在迁移学习中,源域和源域中的任务中包含的知识被迁移到目标域,进一步学习目标任务中的模型。
广义零样本学习(generalized zero-shot learning,GZSL):在零样本学习中,训练样本和测试样本所覆盖的类是不相交的。实际上,这在现实问题中是不切实际的。在许多现实情况下,测试样本不仅包括不可见类的样本也包括可见类样本。在广义零样本学习[10]的设定下,测试样本既可以来自可见类,也可以来自不可见类。在测试阶段,可见类和不可见类同时存在,所以这种设定下的问题更具挑战性。许多零样本学习方法也在广义零样本学习设定下进行了测试,但是测试结果不佳[11]。
尽管通过对样本赋予不同的权重来进行知识迁移理论具有较好的解释,但这类方法通常只在数据域分布差异较小时效果较好,在自然语言处理、计算机视觉等具有复杂特征表示的任务上效果并不理想。如何通过特征的分析来进行迁移学习,是迁移学习研究的重点。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。




