
对大数据与云计算的关系人们通常会有误解,很多人把它们混淆起来。云计算是硬件资源的虚拟化,大数据是云计算处理的数据之源。如果云计算没有海量的数据提供数据之源就相当于巧妇难为无米之炊。打个比喻来说,云计算就相当于一个多功能效率极高的锅,大数据就相当于大量的米。没有大数据的云计算,定是英雄无用武之地;没有云计算的大数据,终会是镜中花、水中月。
大数据是数据矿石,云计算是寻找宝藏的开矿利器!
大数据和云计算虽然是两个完全不同的概念,但事实上二者是相互依赖的。大数据的指数级增长使得数据的提取、存储、处理、管理以及分析具有较高的复杂性,因此大数据对云计算环境有着很高的依赖。云计算从使用者的角度来说不仅大大提高了企业处理大数据的计算能力,而且不需要投入和管理过多的硬件设备,按照需要进行付费,有效地优化现有资源。云计算为大数据提供了安全存储的场所和畅通的访问渠道。大数据作为企业的核心资产,对其进行有效的利用,发掘出其在商业决策中的巨大价值是云计算的内在灵魂和必然的升级方向。
云计算已经被吹捧了好几年,但直到大数据时代到来,它才真正体现出宝贵的价值。尽管云计算的安全性、可用性以及成本等方面仍存在诸多的疑虑,但是各大互联网巨头纷纷加快了对这一领域的跑马圈地和研发投入。云计算是融合诸如网格计算、分布式计算、并行计算、内存计算、虚拟化等传统计算机和网络技术发展起来的产物,通过将计算任务分布在大量的分布式计算机上,形成类网状的服务器集群。云计算的核心价值在于具有较强的可扩展性,高效的交互处理能力,可以实现根据任务自由地分配资源,用户按照需求访问存储空间和服务器集群,从而大大地提高了计算能力,并降低了用户对客户端的要求。随着大数据的出现,云存储、云手机、云计算机、云搜索等概念如火如荼。大数据的出现,为云计算提供了发展空间,也指明了云计算真正有价值的方向。云计算和大数据作为一体两翼,将会是衡量企业未来技术能力的重要依据。如果二者能够协同发挥能量,将会给企业带来精准分析、精准打击,形成企业在未来竞争中的核心武器。
●亚马逊的很多业务都是由数据驱动的。在大数据领域,亚马逊也非常具有先知之名。早在2009年,就推出了大规模数据集并行计算的技术——亚马逊弹性MapReduce。现在,这项技术运行在亚马逊的弹性计算云和亚马逊简单存储服务上,真正实现了云与大数据的结合,凸显了云计算的价值。部署在云端的弹性MapReduce可以根据需求实时地按需配置和访问服务器集群,实现对大量和密集型数据任务的处理,比如,日志文件分析、数据挖掘、数据分析、机器学习、科学模拟等。云计算与大数据的结合在亚马逊销售扩张和成本控制方面发挥着巨大的能量,帮助亚马逊驱动业务发展。
●Mapreduce。Mapreduce是一种并行的编程计算模式,通过此模式先将数据拆分成Map(映射),通过Map程序将数据映射到不同的处理区块,分配给计算机集群处理达到分布式计算的效果,然后通过Reduce(归纳)程序将结果汇总,并向用户输出结果。
未来的趋势将是云计算作为计算资源的底层,支撑着上层的大数据处理,而大数据的发展趋势是满足业务需求,实现实时的交互式的查询效率和分析能力。让用户的体验度真正达到动一下鼠标就可以在几秒钟内交互处理PB级别的数据。
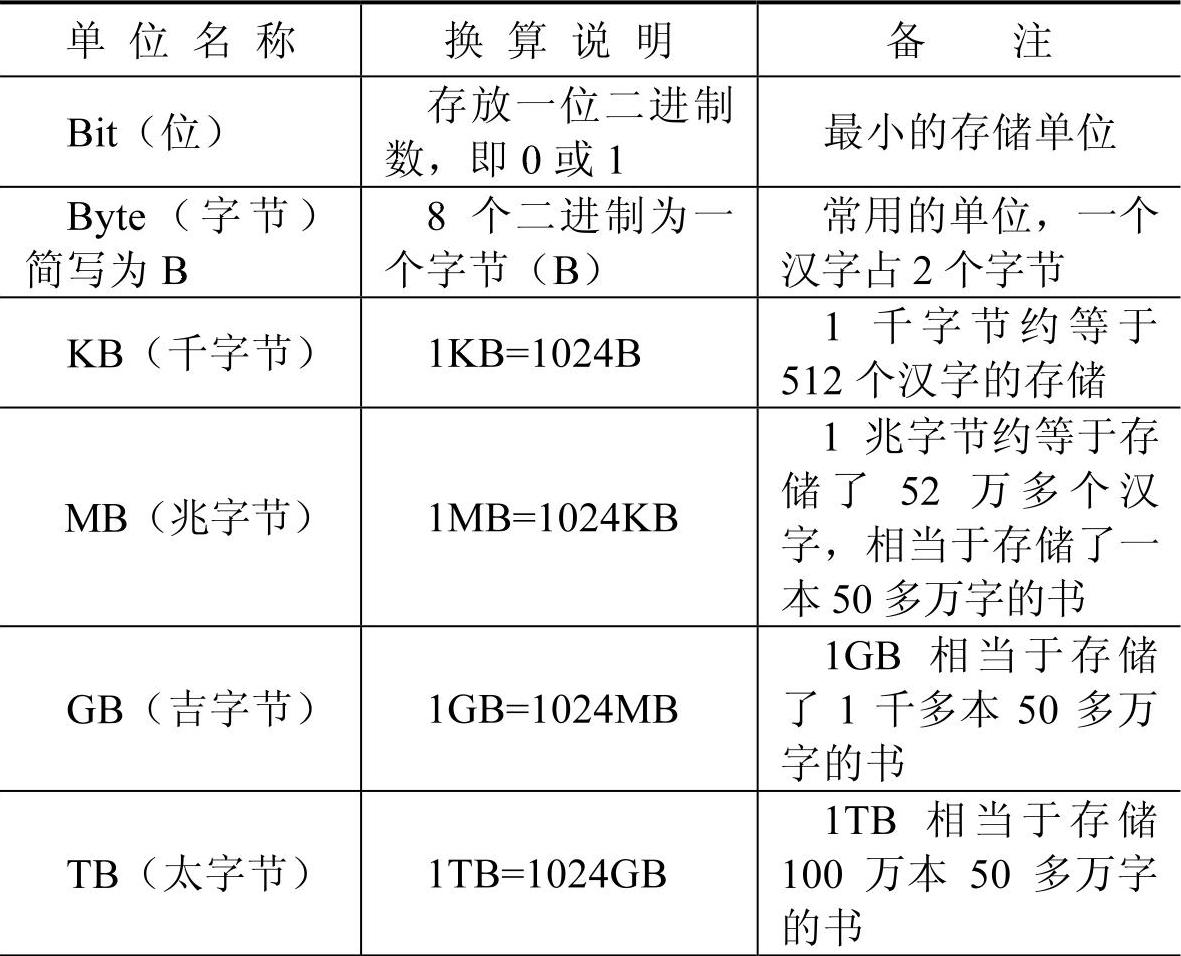
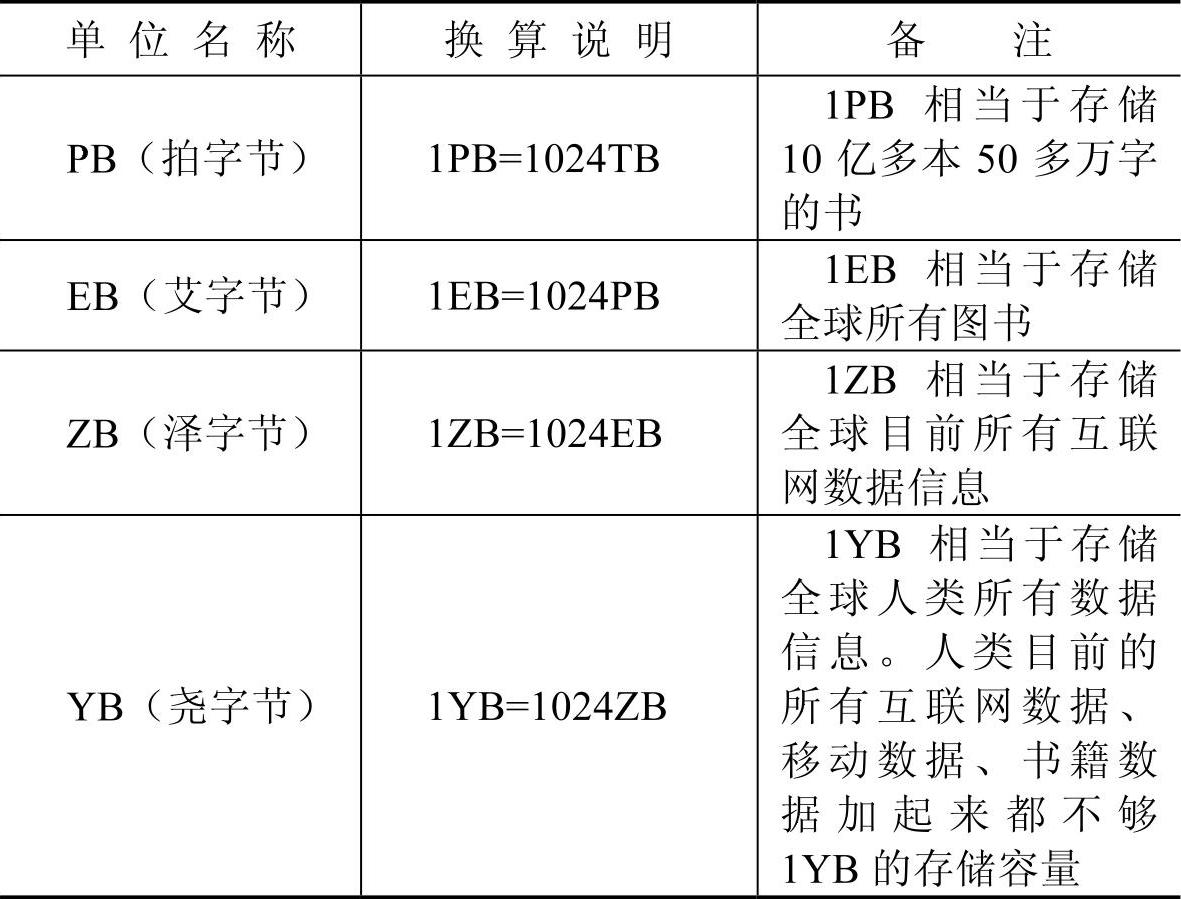
说明:PB级别是一个衡量数据量大小的单位,1PB的数据量相当于存储10亿多本50多万字的书。计算机存储单位换算说明见表3-1。
表3-1 计算机存储单位换算说明
(续)
 (www.daowen.com)
(www.daowen.com)
目前,云计算平台(Hadoop)架构和MapReduce模式组合应用处理海量数据已经成熟。Hadoop是云计算平台的架构,MapReduce是一种处理海量数据的模式方法。在Hadoop架构体系中运用了MapReduce并行编程计算模式处理海量的数据,属于分布式运算技术,从而提高了大数据分析的性能。
●Hadoop介绍。Hadoop实现了一个分布式文件系统(Hadoop Distributed File System),简称HDFS,它有着高容错性的特点,并且设计用来部署在低廉的(low-cost)硬件上。而且它提供高传输率(high throughput)来访问应用程序的数据,适合那些有着超大数据集(large data set)的应用程序。HDFS放宽了(relax)POSIX的要求,这样支持以流的形式访问(streaming access)文件系统中的数据。
Hadoop由Apache Software Foundation公司于2005年作为Lucene的子项目Nutch的一部分正式引入。最先由Google Lab开发的MapReduce和Google File System(GFS)的启发。2006年3月,MapReduce和Nutch Distributed File System(NDFS)分别被纳入称为Hadoop的项目中。
Hadoop是最受欢迎的在互联网上对搜索关键字进行内容分类的工具,但它也可以解决许多要求极大伸缩性的问题。
Hadoop是一个能够对大量数据进行分布式处理的软件框架,以一种可靠、高效、可伸缩的方式进行处理的。Hadoop是可靠的,因为它假设计算元素和存储会失败,因此它维护多个工作数据副本,确保能够针对失败的节点重新分布处理。Hadoop是高效的,因为它以并行的方式工作,通过并行处理加快处理速度。Hadoop还是可伸缩的,能够处理PB级数据。Hadoop是一个能够让用户轻松架构和使用的分布式计算平台。用户可以轻松地在Hadoop上开发和运行处理海量数据的应用程序。Hadoop主要有以下几个优点:
●高可靠性。Hadoop按位存储和处理数据。
●高扩展性。Hadoop是在可用的计算机集簇间分配数据并完成计算任务的,这些集簇可以方便地扩展到数以千计的节点中。
●高效性。Hadoop能够在节点之间动态地移动数据,并保证各个节点的动态平衡,因此处理速度非常快。
●高容错性。Hadoop能够自动保存数据的多个副本,并且能够自动将失败的任务重新分配。
●Hadoop带有用Java语言编写的框架,因此运行在Linux生产平台上是非常理想的。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。





