直接存储器存取是从一个存储器区域到另一个存储器区域之间的数据传送机制,传送过程不会被CPU或其他工作要求所中断。本质上,DMA的硬件包括控制器单元,这个单元能够运行存储器转移操作、一个区间数据或者是一块数据的转移,这种操作独立于CPU。一旦DMA硬件配置好存储器区域起始源地址和目的地址,数据的转移就开始执行了。这种转移能够独立运行不需要CPU的任何干扰。因为传输数据从存储器缓存到编解码器(反之亦然),本质上是存储器转移。通过委派任务到DMA硬件系统代替CPU执行存储器转移,我们能够显著地削减CPU的中断。
为了用DMA执行三重缓存操作,我们的程序必须首先初始化和配置DMA硬件。在C6x DSK文件中称这个硬件为“EDMA”。这里“E”代表增强型,因为它与典型的DMA硬件相比有更强的功能。关于C6x EDMA的详细描述,见TMS320C6000外设参考指南[53]。对于这里的目的,我们只是用到了EDMA功能的一部分。
我们不能忽略一个重要因素是当我们使用DMA时需要使输入和输出保持同步。当我们为了获得DMA优势不需要CPU执行存储器转移时,我们必须意识到CPU不知道这些转移何时发生或究竟速度有多快,除非我们放进去一类代码来确保同步。没有这些代码,三重缓存也许会彼此“失同步”,从而导致不可预知的结果。所幸的是,EDMA硬件有能力配置和监控“事件”,而对于CPU来说却是要进行类似中断的操作才能进行的动作。这给了我们让3个缓存保持同步的一个灵活方法,使我们可以根据需要交换指针来执行三重缓存方案。所有一切动作尽量少的中断CPU,从而CPU的时间尽量完全投入到需要运行的DSP算法当中。这个方法代表了执行实时数字信号处理程序可能存在的最为高效的一种方法。
在以下的例程中,我们只在一个重要方面修改了前面的例子。在中断服务函数中,我们使用EDMA硬件代替CPU来完成从编解码器ADC端获取输入值和发送输出值到编解码器的输出端。这个EDMA程序在本书CD中第6章的ccs\Frame_ED-MA子目录下。为了解程序的所有工作,查看全部程序清单。这里我们对一些重点简单地进行说明。主程序(main.c)是非常基本的,再次在下面列出,和程序清单6.1只有很少的一点差别(第10、13行)。
程序清单6.6:使用EDMA的基于帧处理主程序
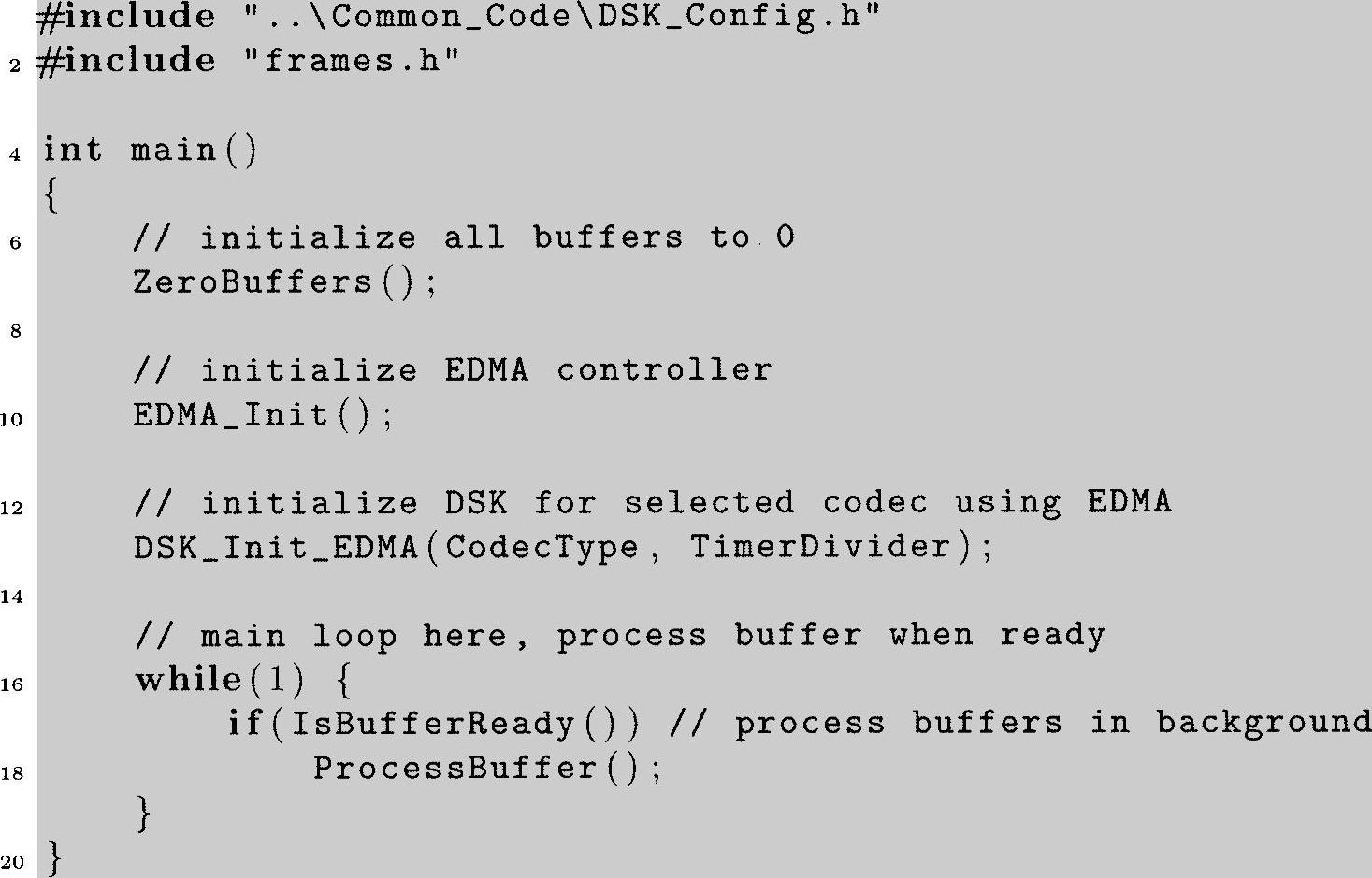
函数ZeroBuffers和IsBufferReady来自于前面所述的非EDMA版本,是不变的。但是,初始化程序需要的单一中断服务程序(被EDMA“事件”触发)和Process-Buffer函数和我们前面所述的程序代码完全不同。所以我们需要检查它们。因为没有改变指定的中断路径,我们将使用一个不同的文件指派中断矢量,即我们用vec-tors_EDMA.asm代替vectors.asm。我们还将为变量定义一个不同的缓存长度。注意,与之前的CCS工程一样,EDMA版本的DSK初始化函数能够在DSK_Support.c文件中找到,在common_code目录中。中断矢量文件也在这里。EDMA版本的其他文件在本书CD中第6章的ccs\Frame_EDMA子目录下。
我们开始在EDMA版本的ISRs.c文件中列出这个声明,它们和非EDMA版本的声明稍微有些不同。
程序清单6.7:来自于“ISRs.c”文件中EDMA版本的声明
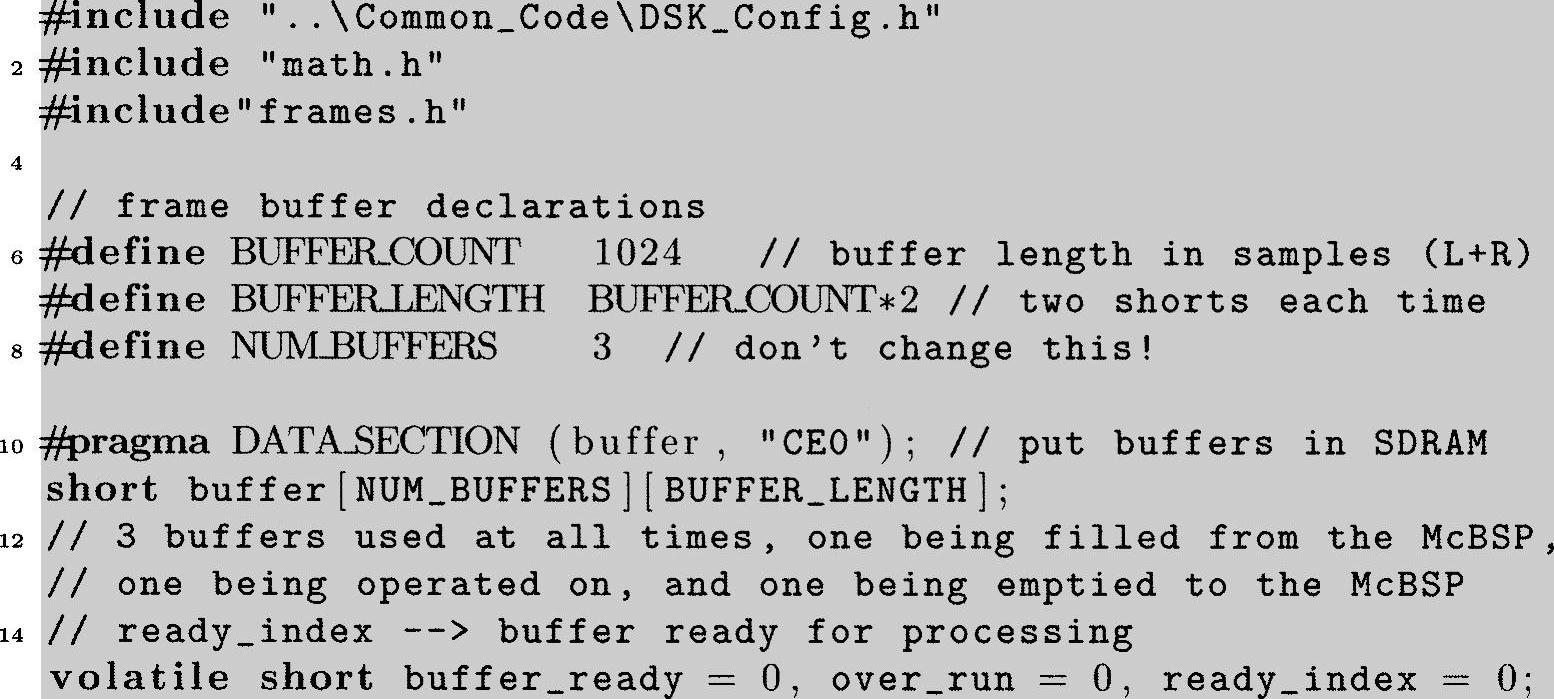
注意,在EDMA版本的声明中,第11行的数据缓存声明为短整型,在DSK板中的数据缓存是16比特整型。在所有我们过去采用的代码中,浮点型缓存利用了浮点数的灵活性和适应性。在这里我们还继续这样做,在这些缓存中的值在使用之前被转换成浮点类型。为什么需要额外的转换步骤呢?回忆一下来自于编解码器的ADC(或者输出到DAC)的采样值是整型。在非EDMA版本的代码中,在缓存与编解码器之间传送的值由CPU执行,CPU必然承担着浮点和整型数据之间的转换。然而,在EDMA代码中编解码器和缓存之间的数据传送执行没有CPU的参与,因此这样的传送实际上是“无干预”传输的,不能进行任何数据类型转换。这样的转换需要CPU,所以我们把需要的从整型到浮点的数据转换(或者反之转回到整型)转移到ProcessBuffer函数中,这一点详见后面函数部分。
在第6行指定的帧长度是每帧1024个采样点(1024个左通道采样点和1024个右通道采样点)。以前,我们高效转移左右两个通道的采样值(每个通道16比特)组成一个32比特的转移操作。通过声明一个联合体,我们能够独立的使用这两个通道。在这里我们采用同样的办法通过观察整型数据类型(DSK用32比特长的整型类型)是短整型长度的2倍,所以你将会见到EDMA硬件初始化为传输整型。
我们现在讨论函数EDMA_ISR,这是一个真正实现三重缓存方案的函数(例如,根据需要设置指针地址)。在非EDMA版本程序中,利用程序清单6.3中的函数MCBSP_Rx_ISR执行本任务。EDMA_ISR包含在ISR.c文件中,文件位于本书CD中第6章的ccs\Frame_EDMA子目录下,程序代码如下。这些代码与程序清单6.3中的代码相比更简单、更快。
程序清单6.8:利用EDMA硬件实现三重缓存的函数
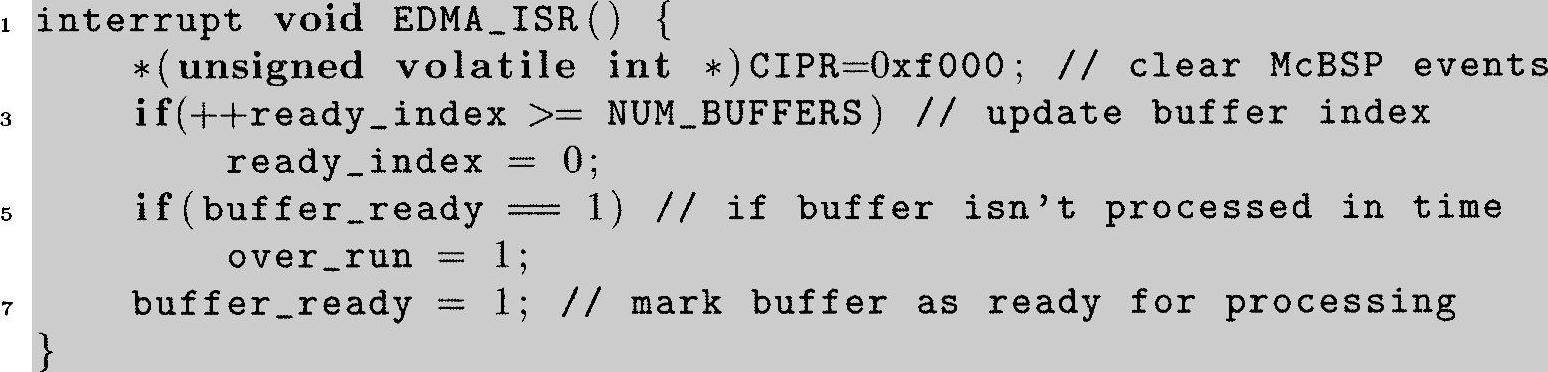
注意,在非EDMA版本中,每一次采样都会产生一个中断,依靠此中断触发中断服务程序。在EDMA版本中,类似于中断服务程序的“事件”只有在全部的采样帧传送完毕后才发生。这个“事件”触发一个中断,这个中断引起中断服务程序EDMA_ISR运行。因此,在这个例子中对于1024点的帧来说,EDMA_ISR的调用次数与非EDMA版本中的MCBSP_Rx_ISR相比为原来的1/1024。但是使用EDMA事件,正好可以让我们使所有缓存保持同步。
在这里的EDMA版本中,尽管我们仍然使用中断服务程序,但EDMA_ISR是一个非常简短并且快速的程序。这个程序使对CPU的中断达到了最小化。在这里非常重要的要重申的一点就是要为真正的中断(INT8,由一个EDMA事件触发)映射一个中断矢量到这个EDMA_ISR函数的合适的地址,那么这个程序的CCS工程必须包含vectors_EDMA.asm文件(在common_code目录中提供给你)而不是在前面用于CPU ISRs的中断服务程序中的vectors.asm文件。
因为与前面的程序比较起来DSK的初始化对EDMA程序略有不同,我们下面列出了这个初始化函数。
程序清单6.9:使用EDMA时的DSK初始化函数(https://www.daowen.com)
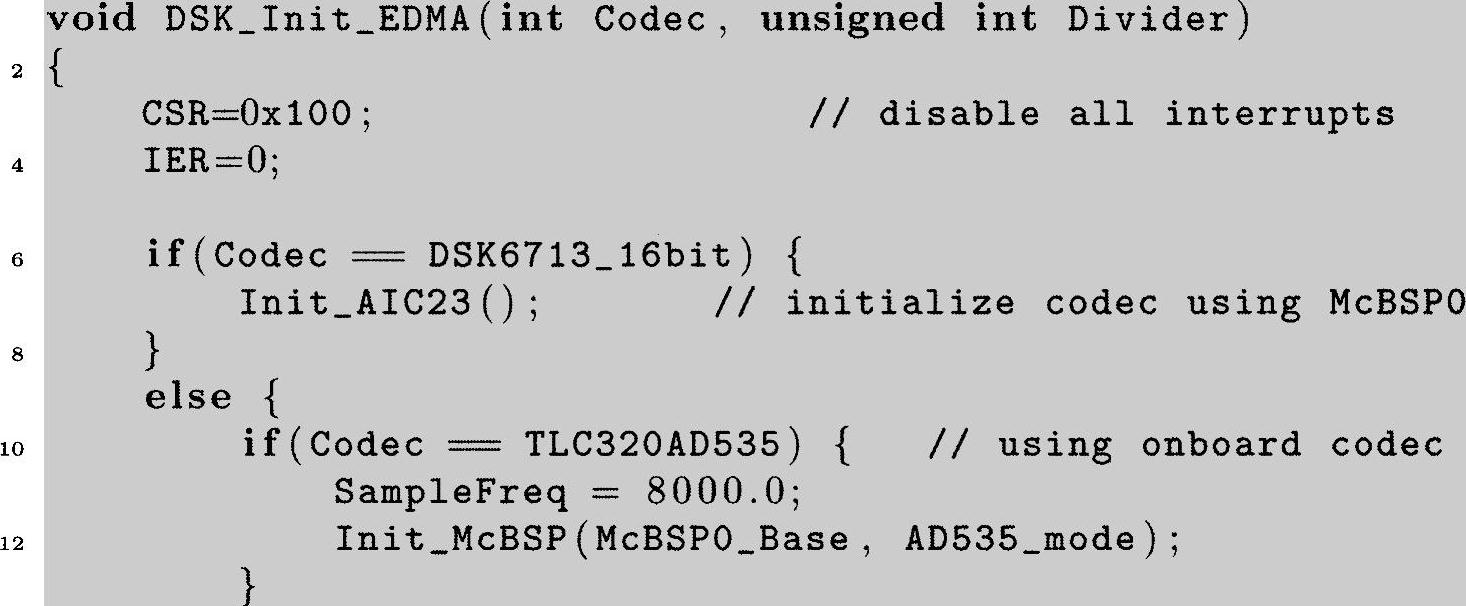
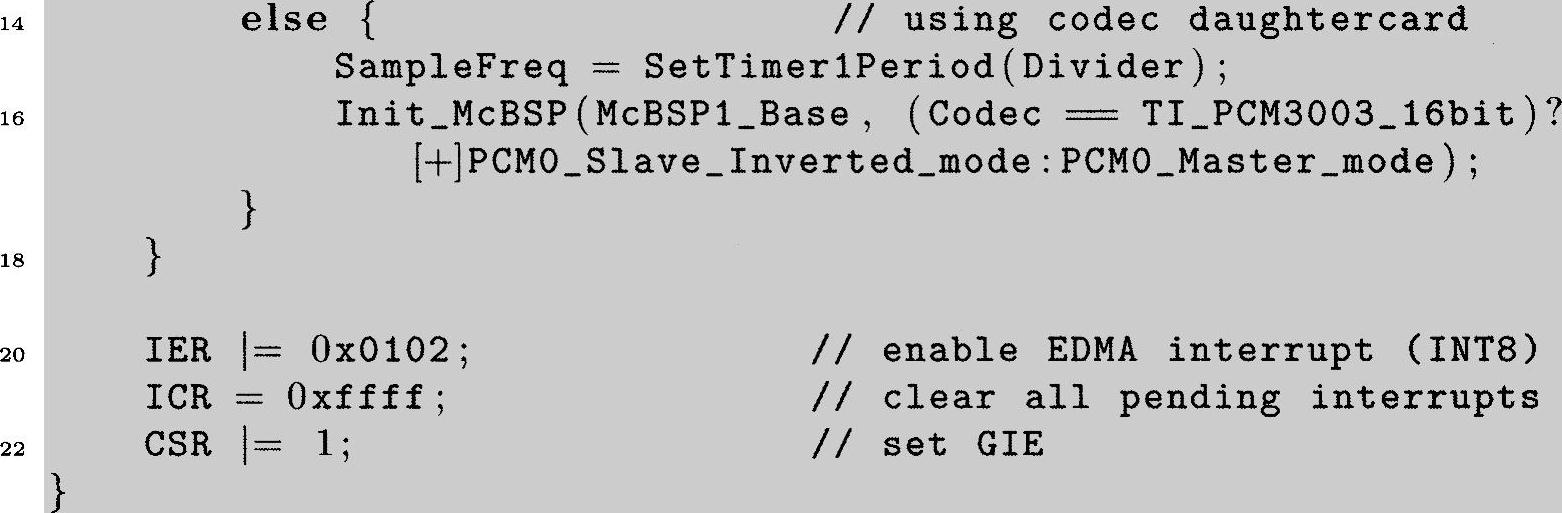
这个版本中和前面使用的non_EDMA版本比较起来仅在第20行有区别。在这里我们为EDMA硬件使能INT8(而不是使能INT 11和INT 12,在前面McBSP中断程序中我们曾经用过的这两个中断)。你可能会想到为你自己而检查vectors_ED-MA.asm,这个文件映射于EDMA_ISR函数的INT 8。
我们需要讨论的下一个函数是EDMA_Init。它包含在ISRs.c文件中,此文件位于本书CD中第6章的ccs\Frame_EDMA子目录下,程序代码如下。
程序清单6.10:初始化EDMA硬件的函数
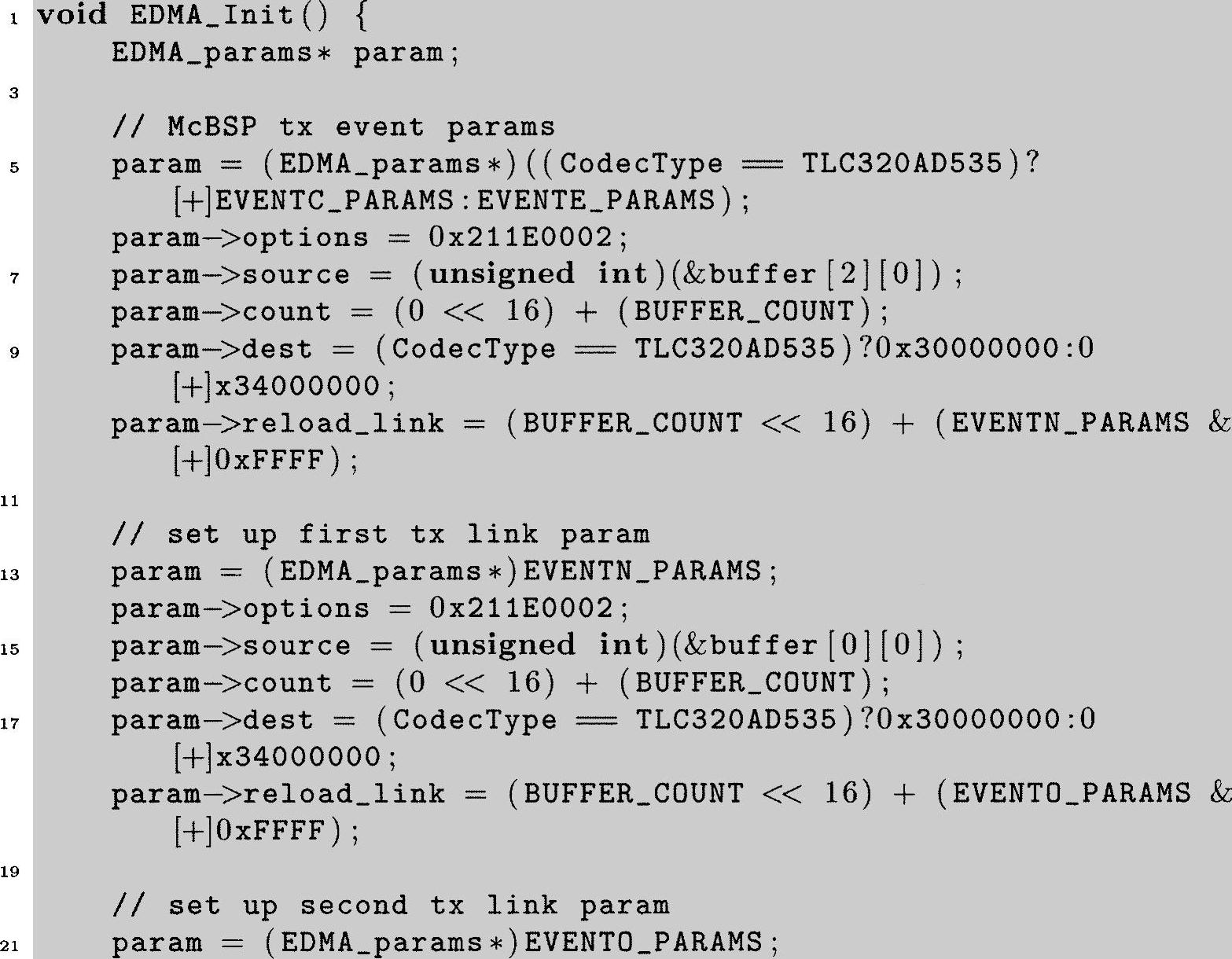
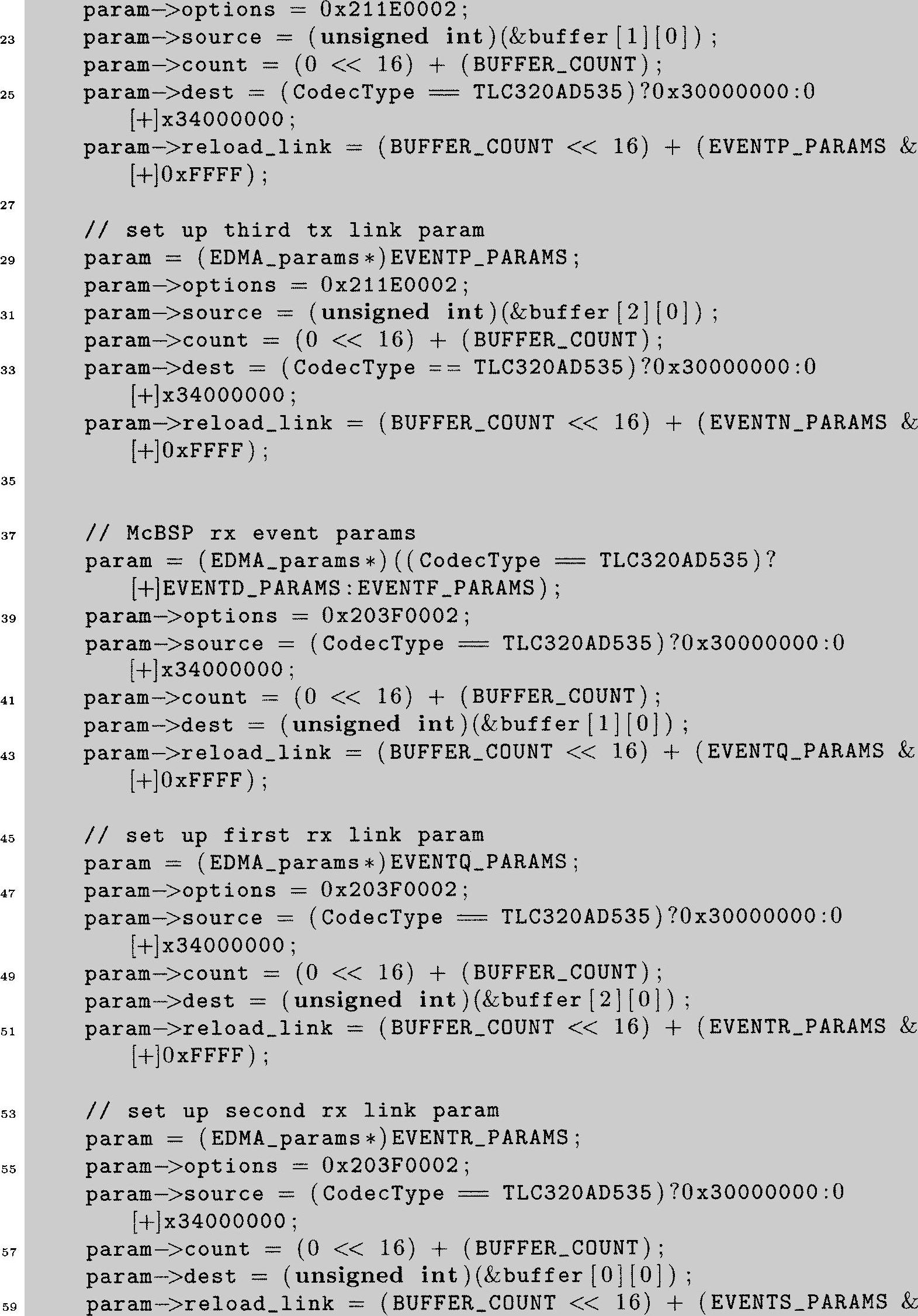
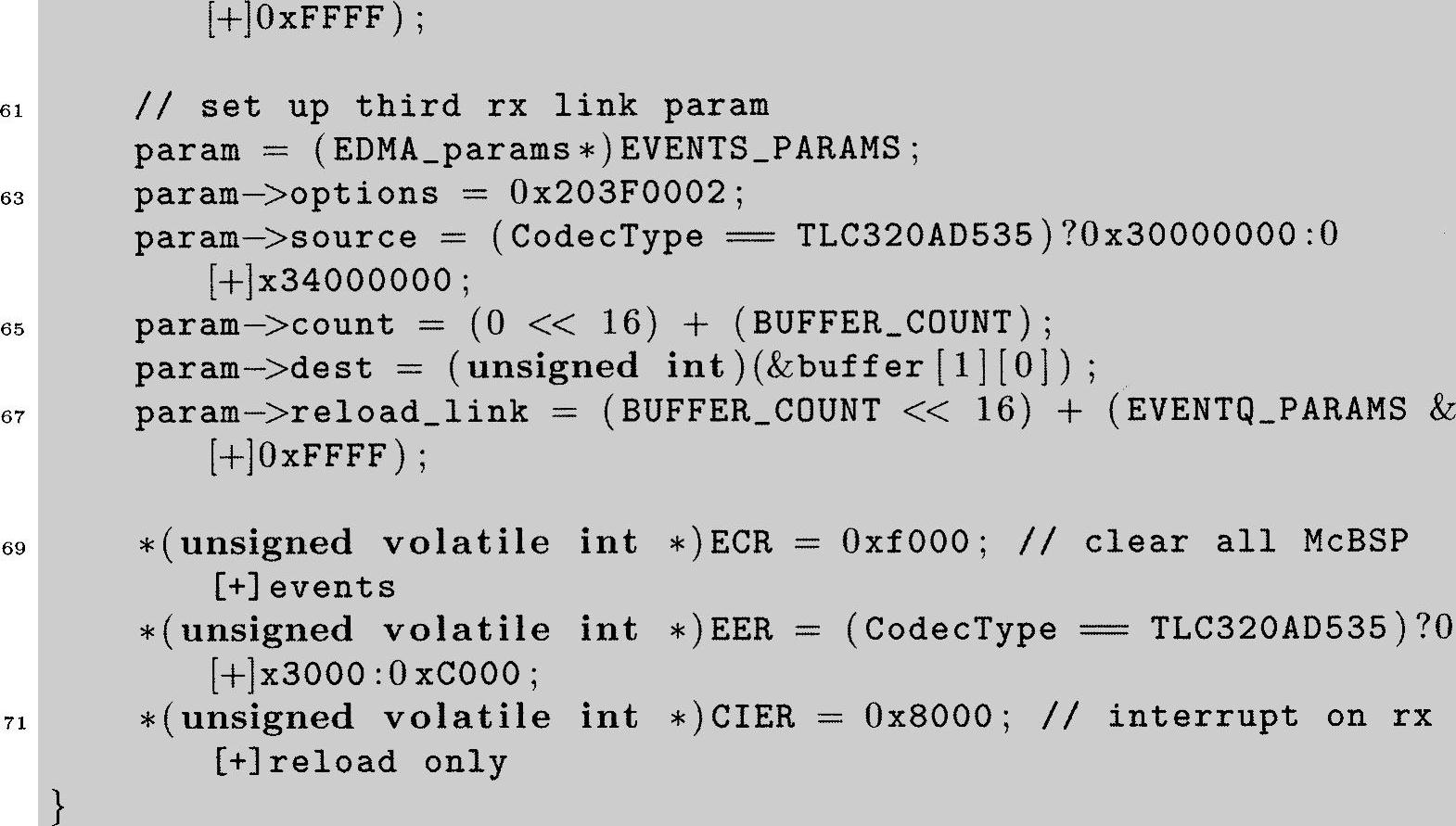
为全面了解该函数功能,必须阅读TI的相关手册,它详细描述了怎样使用EDMA参考文献[53](TMS320C6000外围接口向导),同时要阅读包含DSK变量定义的commom_code中的头文件c6x11dsk.h。如果对C语言的结构和指针有点生疏,那现在就是一个让自己重温一下的好机会。函数Init_EDMA只执行一次,在这儿要说明一些事情,比如源地址、目的地址及每个需要定义的DMA传输的成员变量,然后建立连接。这样一个三重缓存配置就实现了。为了简短,这里只给出传输函数的大纲,接收函数操作类似。
记住我们仍像先前那样处理3个缓存。函数Init_EDMA设置两个EDMA通道,其中一个是为McBSP传输服务,另一个为McBSP接收服务。EDMA每个通道都有一个事件与其相关(如前面所提到的,这种关系和CPU与中断例程类似)。每个EDMA传输由RAM块中设定的值来控制,设定这些RAM块是Init_EDMA的主要目的。EDMA通道12致力于McBSP0的传输,通道14致力于McBSP1的传输,因此代码第一块(第5~10行)基于所使用的编解码器来选择事件12(即EVENTC)或者事件14(即EVENTE)。用给定的参数值来配置事件中由BUFFER_COUNT(ISRs.c中定义)说明的成员数(它们自己是32位定点数),并传输到初始化指定为输出缓存的buffer[2]中[25]。EVENTC或EVENTE(根据所用编解码器确定)代码在传输结束后将自动重新配置通道[26],其信息存储在RAM的参数EVENTN_PARAMS中(这由第10行的reload_link语句来完成)。EVENTN是从第13行开始的下一个代码块,它使用buffer[0]配置EDMA,并在其完成之后重新配置通道[26],其信息存储在EVENTO_PARAMS中。然后,EVENTO_PARAMS(第21行开始)将会让EDMA使用buffer[1],在其完成之后重新配置通道,其信息存储在EVENTP_PARAMS中。然后,EVENTP_PARAMS(第29行之后)将会让EDMA使用buffer[2],在其完成之后重新配置通道,其信息存储在EVENTN_PARAMS中。这样就有效地循环到初始buffer。只要程序运行,按顺序使用三个缓存器的循环就会继续。这就阐明了一个重要观点:在CPU零系统开销的情况下,可以自动应用的n重缓存(在这是三重缓存)方法。接收通道(第37~67行)操作类似,但起始缓存器不同(buffer[1])因此可以保持输入和输出工作在不同的缓存器。
Init_EDMA的最后几行不能忽略。第69行是清除所有McBSP事件(尽管只使用两种事件——传输和接收——也可以清除所有的事件)。第70行根据使用的编解码器类型设置事件中适当的值来使能寄存器。最后第71行是临界行,它设置了通道中断使能寄存器,这样当服务于McBSP接收操作的特殊EDMA通道完成一个帧的传输时,一个EDMA事件就会发生。这就意味着每次输入帧缓存器满时,一个事件才会触发。
最后,给出函数ProcessBuffer作为EDMA程序的改进。这是完成实际的DSP算法的函数。首先注意到的是这个ProcessBuffer版本的程序比非EDMA版本的要长。这是因为在缓存中需要表现数据转换类型。
程序清单6.11:EDMA ISRs.c文件里ProcessBuffer函数的简化翻译
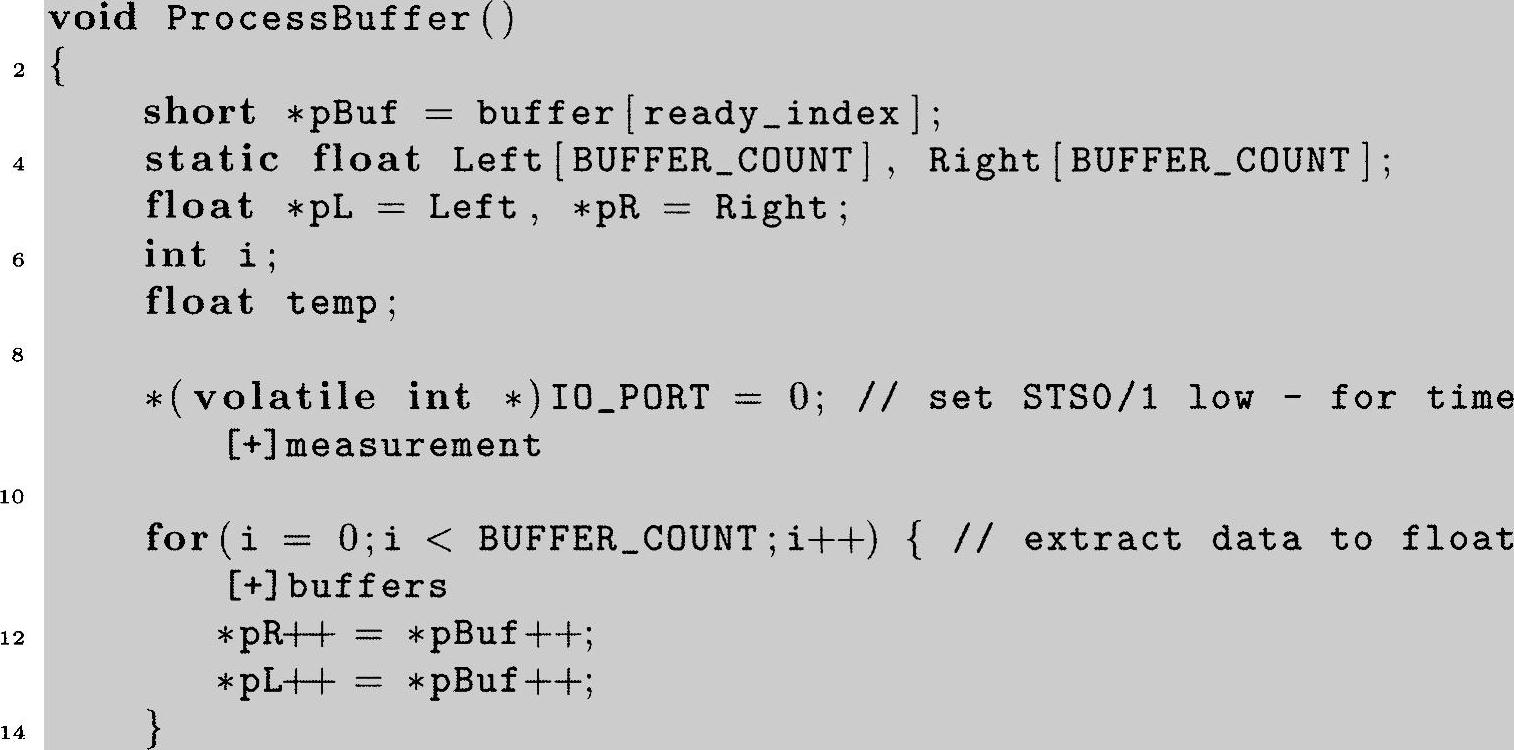
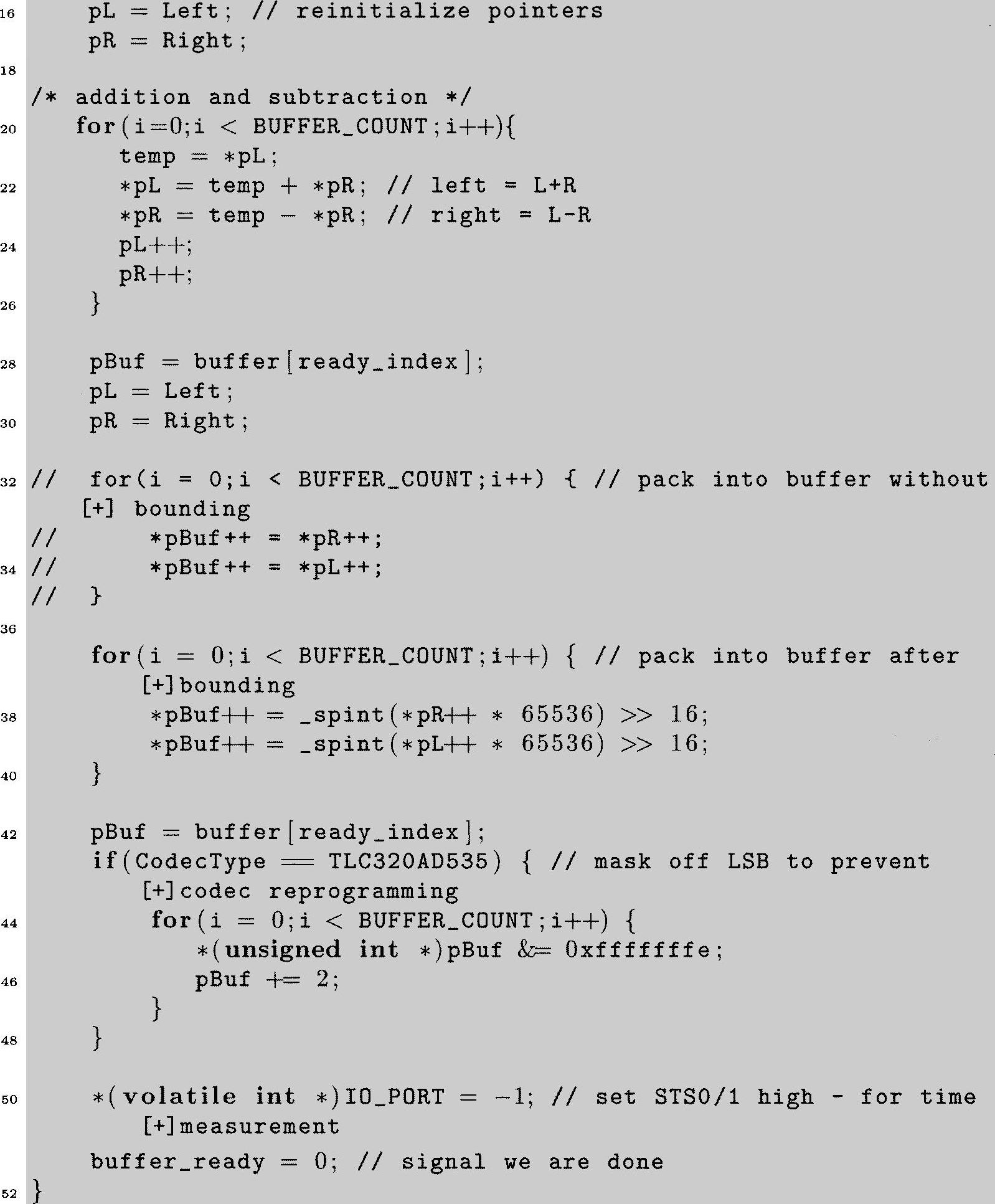
你可以看到实际的DSP算法,该算法与之前使用过的加法和减法例程一样简单。该算法由第20~26行的程序代码实现。
第3行的代码定义了一个指针指向short类型帧缓存器。先前使用EDMA时,该帧缓存器已经被填满,现在是待处理。第4行的代码声明了两个float类型的缓存器,在转换成浮点后用来存储左右帧数据。第5行的代码声明了指针用来操作帧里的单个采样点(浮点形式)。第9行和第50行仅在代码升级时用来测试和评估的。真正的从short到float类型的转换是由第11~14行的代码完成的。当CPU传输由∗pBuf指向的整数值到由∗pR指向右通道,而∗pL指向左通道的浮点位置时,C编译器确保发生转换。要注意传输和转换是交替进行的,首先是右通道然后左通道,这是顺序,其中首先是将数据存储在EDMA缓存器中。这里也可以使用“cast”语句完成从short到float的转换,但这没有优势而且我们更喜欢目前这个方法。尽管这个方式看起来从一个缓存器到另一个缓存器的转换,并且效率不高,但事实上转换是很快的。由EDMA传输给CPU节省的时间远超过这样缓存器转换所占用的CPU时间。
第16、17行的代码使指针指向左右通道的浮点值矩阵的第一个元素,然后实际的DSP算法就能够执行了。相似的第28~30行的代码在DSP算法执行后重新设置指针。为将处理后的浮点值转换回适合EDMA传输到编解码器的定点值。用户可以选择第32~35行或者第37~40行,这取决于是否希望使用intrinsic_spint函数来进行误差检查(好主意)。第43~48行的代码保障了C6711 DSK的TLCC320AD535编解码器的兼容性:试想一个传输到该编解码器的是非零LSb(最低有效位),该编解码器用户希望重新配置,当我们刚发送输出数据时却会发现我们不想要的结果。因此,第45行的代码确保如果该编解码器使用时所有的LSbs都会清零。
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






