1.实验平台
本书应用北京联合大学C70智能车上使用的工控机和NVIDIA Tegra X1作为两个性能对比平台。其中工控机是Inter i7的高配置计算机,NVIDIA Tegra X1是由ARM和GPU组合而成的。其具体配置见表8-4。
表8-4 平台配置
本小节激光雷达测试数据采集于障碍物较少的简单道路环境和障碍物较多的复杂道路环境,并以这两种数据进行激光雷达数据处理性能分析。简单道路环境激光雷达数据处理显示如图8-27所示,复杂道路环境激光雷达数据处理显示如图8-28所示。

图8-27 简单道路环境激光雷达数据处理显示

图8-28 复杂道路环境激光雷达数据处理显示
(1)栅格投影
传统激光雷达栅格投影处理方式是将栅格数据存放在pageable memory上,如果采用该方式存放栅格数据,则GPU与CPU的传输只能用cudaMemcpy()来进行(目前Tegra X1不支持将已有数据的pageable memory直接锁定为pinnedmemo-ry)。传输32MB的数据在pageable memory上,host传输到device传输的实际带宽为2236.1MB/s,传输较大的栅格数据到GPU的消耗是极大的。
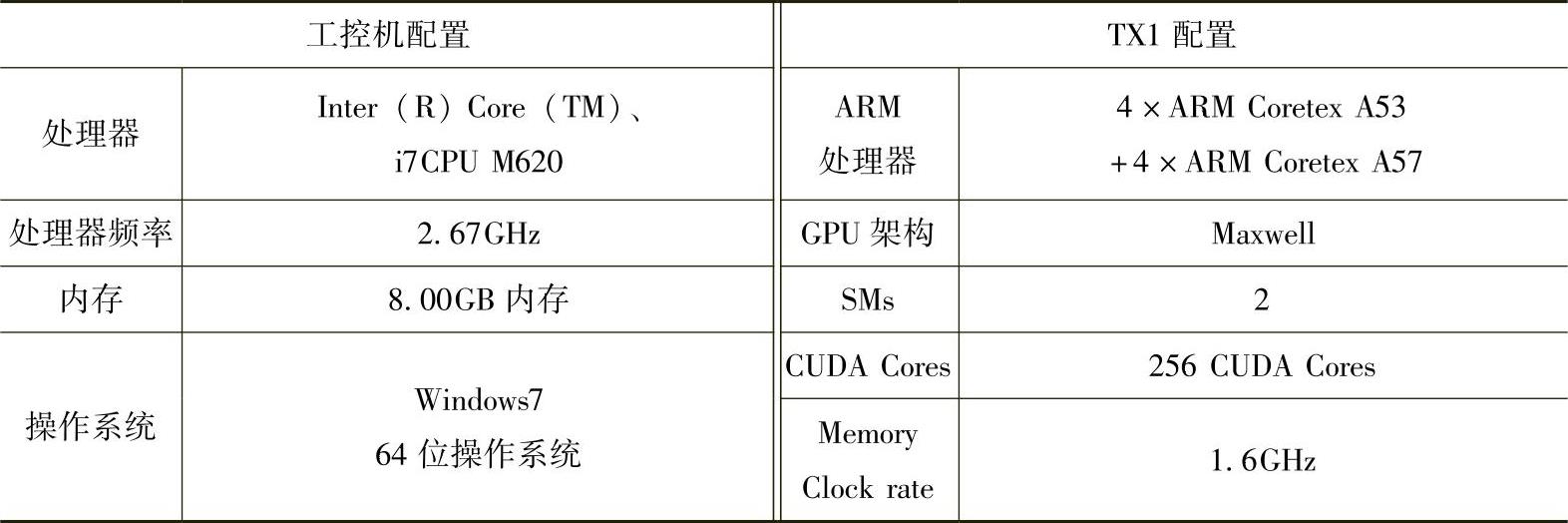
为此,本书将栅格数据存放在pinned memory上。因为Tegra X1的CPU和GPU内存共享,所以数据在pinned memory上的访存性能与在page memory上相当。再结合Tegra X1 ARM的特点对栅格投影进行优化,优化后Tegra X1与工控机的性能对比如图8-29所示。本书采用基于Tegra X1 ARM优化后的栅格投影算法来处理不同道路环境下的激光雷达数据。从图8-29可以看出,投影后的栅格数据存放在pinned memory的性能优于存放在pageable memory,其性能相较于工控机的性能有了5~6倍的提升。
(2)栅格处理
本书首先完成栅格投影后的栅格数据基于Tegra X1 ARM处理算法的优化,对于不同环境的激光雷达数据其处理性能相较于工控机的性能有2~2.2倍的提升,其性能对比如图8-30所示。
 (www.daowen.com)
(www.daowen.com)
图8-29 优化后Tegra X1与工控机栅格投影性能对比

图8-30 Tegra X1 ARM优化与工控机栅格处理的性能对比
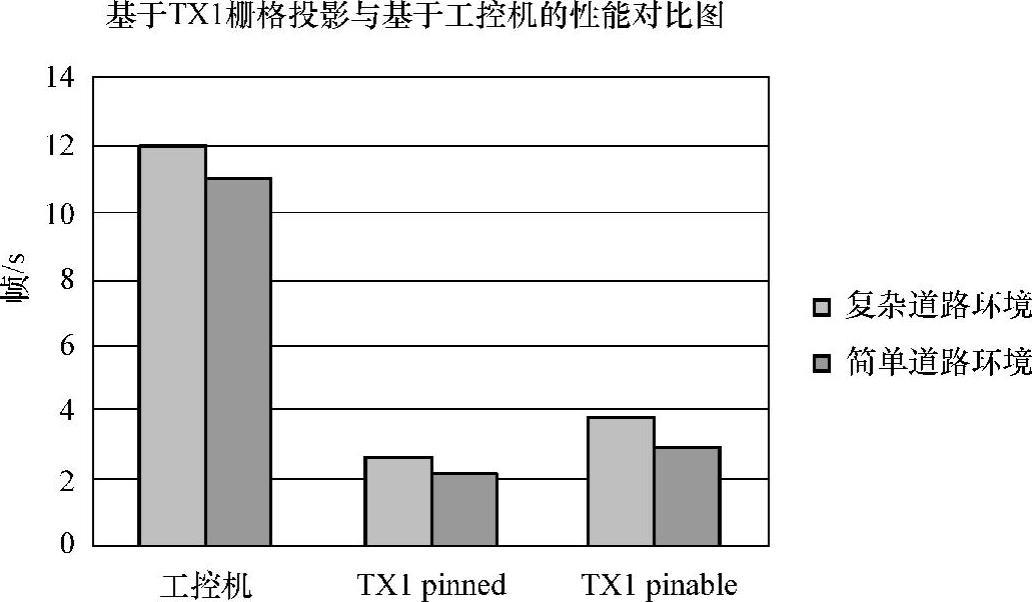
GPU优化时考虑到栅格之间毫无依赖关系,即有良好的并行性,因此尝试采用一个线程处理一个栅格的方法来进行并行处理,以提高处理性能;再将处理后的数据放入共享内存中,来提高global memory的访存效率。GPU采用SIMT(Signal Instruction Multiple Thread,单指令多数据)编程模型,其调度和执行的基本单位是warp。其最终执行时间由执行时间最长的线程决定。如图8-27所示,对于道路障碍物较少的简单环境,各个线程的负载比较均衡,warp间的负载不均衡的现象并不严重。如图8-28所示,对于道路障碍物较多的复杂环境,各个线程的负载极度不均衡,warp间的负载不均衡很严重。
当以thread作为处理单元时,激光雷达栅格数据处理的稳定性比较差。本书采用粗粒度并行的方法来处理栅格数据,即以一个warp处理一个栅格,可获得较高的稳定性,如图8-31(见彩插)所示。
由于采用warp作为处理单元,其处理对应的栅格结果为一个数据,直接访问global memory的代价很高,因此本书将处理后的结果放入shared memory中(即数据本地化),从而实现合并访存,提高global memory的访存效率。采用warp作为处理单元加数据本地化的处理性能远远高于采用thread作为处理单元的处理性能,也高于只采用warp作为处理单元方法的处理性能,其性能对比如图8-32所示。
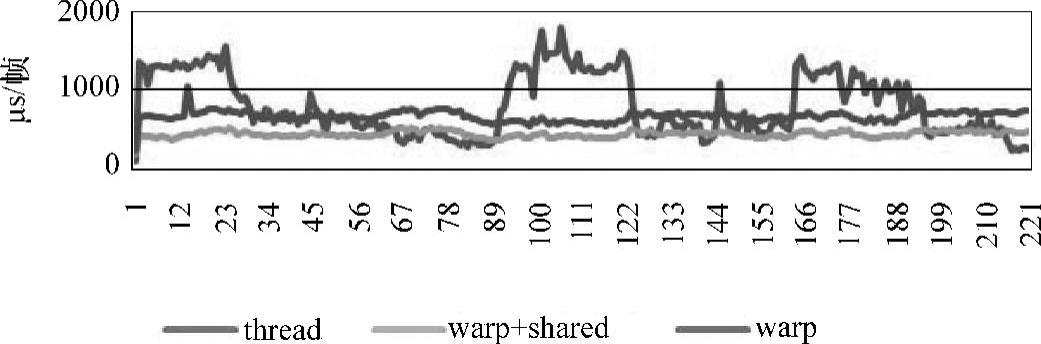
图8-31 栅格处理数据稳定性对比
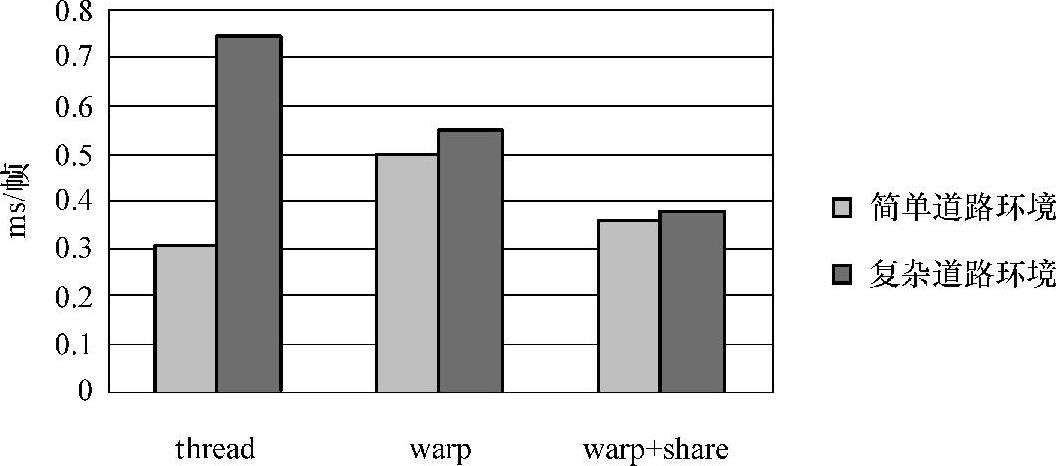
图8-32 Tegra X1 GPU栅格处理的性能对比
(3)实车测试
一个完整的激光雷达数据处理算法包括数据获取、数据解析、障碍物检测、道路检测和路径规划等几个算法模块。本书在对激光雷达数据处理算法优化之前,首先对这几种算法在NVIDIA Tegra X1上进行性能测试。测试结果发现障碍物检测算法耗时最长,其他几个算法模块在NVIDIA Tegra X1上所耗时间并不长。因此本书的主要工作是对障碍物检测算法进行了大量的优化,对其他几个算法模块只做了少量的优化。基于NVIDIA Tegra X1的32线激光雷达优化后的算法,已在北京联合大学C70智能车上完成行驶实验。对比Tegra X1和工控机处理数据性能分析,发现从雷达上读取数据Tegra X1和工控机性能相差不大,但其处理性能是采用工控机处理激光雷达数据的5~6倍。具体如图8-33所示。
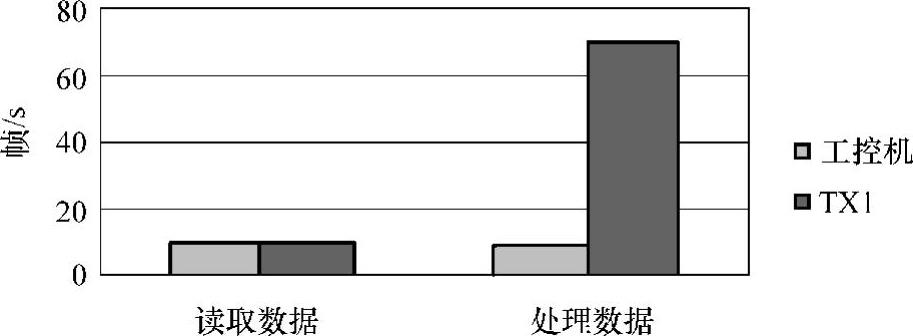
图8-33 激光雷达Tegra X1与工控机处理数据的性能对比
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






