1.初步算法设计
栅格处理是以栅格为单位进行处理。栅格之间毫无依赖关系,具有良好的并行性。因此本书采用一个线程负责处理一个栅格的方法来处理栅格数据,这种初步算法设计比较容易实现。该算法设计以线程作为基本处理单元,不同的线程分别获取对应的栅格内的信息,根据栅格内的信息得出栅格的相对高度差。具体算法设计流程如图8-20所示。
栅格内数据量不一致,若采用初步算法设计的方法来处理栅格数据,将导致有的线程任务过大,造成线程间的负载不均衡。由于GPU采用SIMT(单指令多数据,Signal Instruction Multiple Thread)编程模型,其调度和执行的基本单位是warp,其最终执行时间由执行时间最长的线程决定。因此,这种线程间的负载不均衡现象可导致程序性能的极大降低。
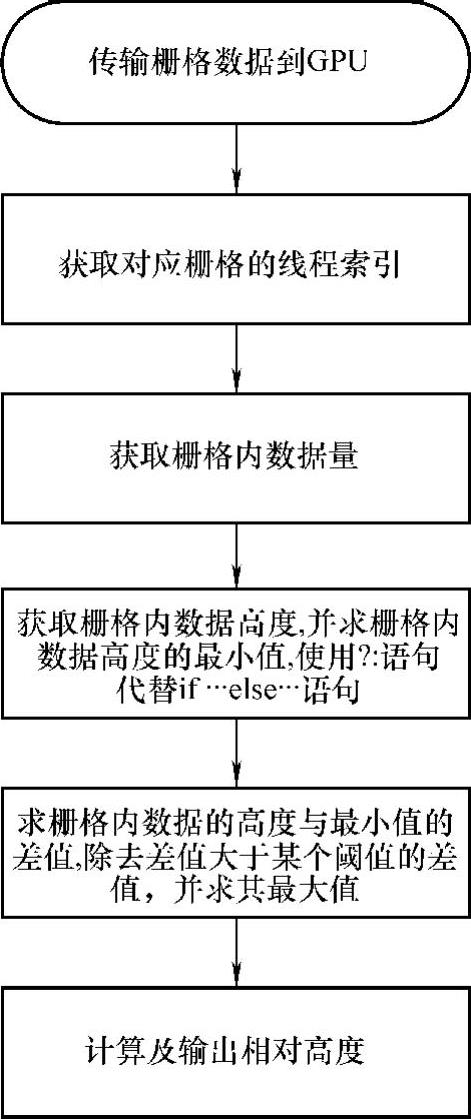
图8-20 线程(Thread)处理栅格
图8-21显示了负载不均衡的现象。假设一个warp中包含9个线程,每个线程负责处理一个栅格。如图8-21所示,在处理完第一个栅格数据时,所有线程都处于忙碌状态,线程间负载均衡。然而,处理第二个栅格数据后,(0,0)和(1,1)负责的栅格数据已经处理完毕。那么在处理第二到第四个栅格数据时,这两个窗口对应的(0,0)和(1,1)线程将处于空闲状态,直接退出。更为严重的是,随着处理过程的进行,越来越多的栅格处理完毕,也就意味着越来越多的线程退出。直到处理到最后一个栅格数据时,只有线程(1,2)还处于活动状态,其他8个线程都已经退出,这就造成了这9个线程间的负载不均衡现象。更糟糕的是,各个栅格数据量差异越高,所需要的运算量就越大。这种线程间的负载不均衡现象,特别对采用多线程调度机制(warp)的GPU来说,会严重浪费其计算资源,进而严重制约算法在GPU上的性能。
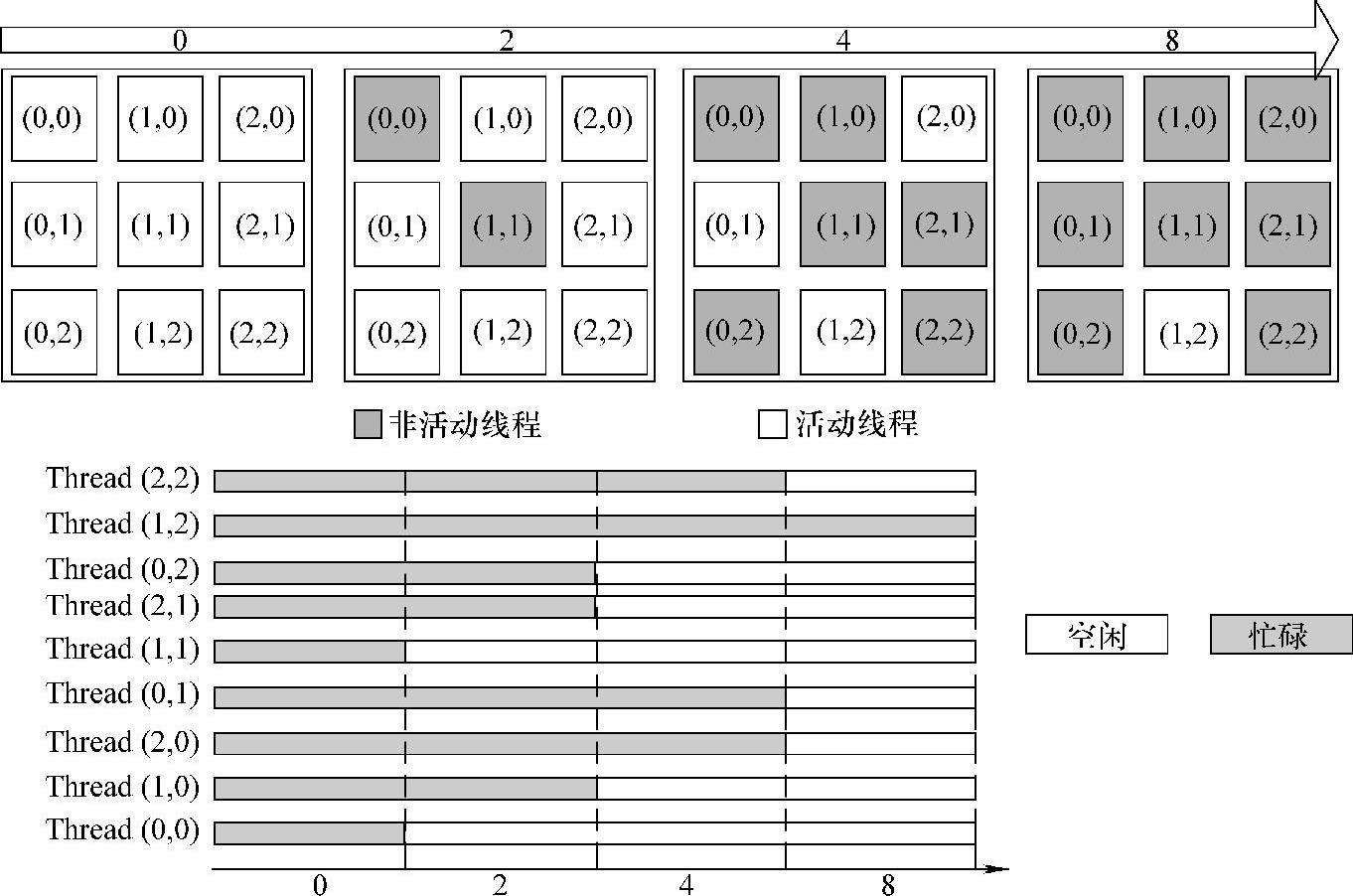
图8-21 栅格处理初始GPU版本的负载不均衡现象
2.粗粒度并行
逻辑上,所有thread是并行的,但是,从硬件的角度来说,实际上并不是所有的thread能够在同一时刻执行。32个并行thread组成了一个warp。warp是SM的基本执行单元。在SM中warp调度器每个cycle会挑选warp送去执行。一个被选中的warp称为selected warp;没被选中、但是已经做好准备被执行的称为eligible warp;没准备好要执行的称为stalled warp。warp适合执行需要满足下面两个条件:
 32个CUDA core有空。
32个CUDA core有空。
 所有当前指令的参数都准备就绪。
所有当前指令的参数都准备就绪。
图8-22所示为用warp处理的简单的执行流程。当warp0阻塞时,执行其他的warp,当warp变为eligible时,重新执行。
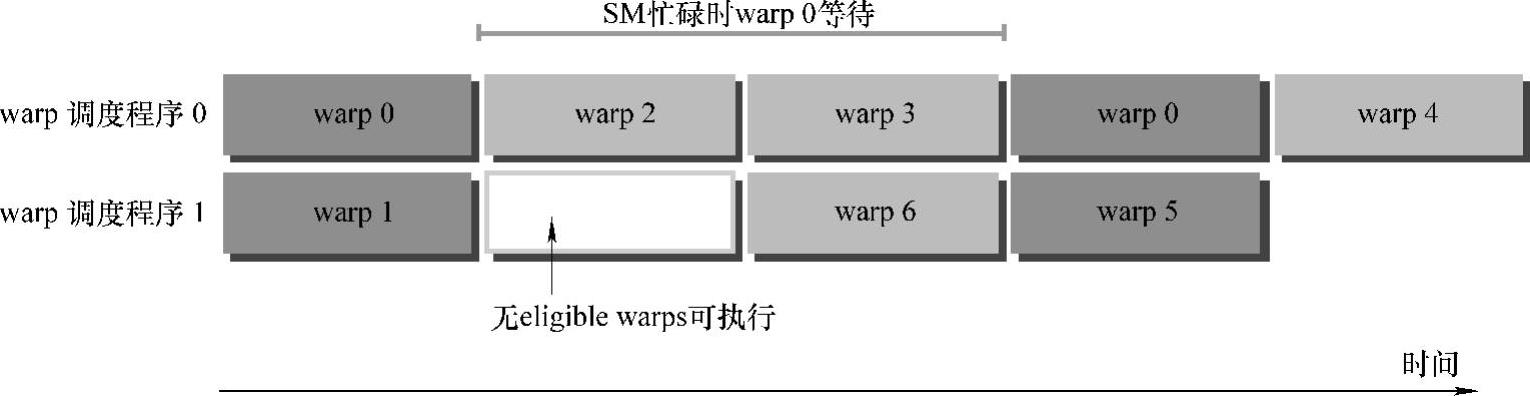
图8-22 用warp处理的简单的执行流程
指令从开始到结束消耗的clock cycle称为指令的latency。当每个cycle都有eli-gible warp被调度时,计算资源就会得到充分利用。基于此,我们就可以将每个指令的latency隐藏于issue其他warp的指令的过程中。
传统GPU编程模型都选择thread作为最基本的并行执行单位。然而在该算法中,各个栅格内的数据差异很大,当以线程作为基本单元处理栅格时,将出现线程间的负载不均衡现象,因此thread作为并行粒度的编程方法并不可行。在这种情况下,我们引入粗粒度并行的概念:选择warp作为基本并行执行和任务分配的单位,同时warp内所有线程将协同完成分配给warp的计算任务。(www.daowen.com)
warp是SM的基本执行单元,一个warp包含32个并行thread。这32个thread执行于SMIT模式。也就是说,所有thread执行同一条指令,并且每个thread会使用各自的data执行该指令。一个warp中的线程必然在同一个block中。如果block所含线程数目不是warp大小的整数倍,那么多出的那些thread所在的warp中,会剩余一些非活动的thread,也就是说,即使凑不够warp整数倍的thread,硬件也会为warp凑足,只不过那些thread是非活动状态,需要注意的是,即使这部分thread是非活动的,也会消耗SM资源。一个warp的context包括program counter、register和shared memory三部分。
在同一个执行context中切换是没有消耗的,因为在整个warp的生命周期内,SM处理的每个warp执行context都是on-chip的。每个SM有一个32位register集合放在register file中,还有固定数量的shared memory,这些资源都被thread瓜分了。由于资源是有限的,所以,如果thread比较多,那么每个thread占用资源就较少;如果thread较少,那么占用资源就较多。这需要根据任务的需求做出一个折中选择。
本书根据栅格处理算法的特点,在一个block里分配8个warp来使warp内thread占有足够的资源,如图8-23所示。warp是SM的基本执行单元,即warp内的线程是并行的。若warp内线程处理任务所需的时间不同,则出现warp内的任务小的线程等待任务大的线程,从而导致出现负载不均衡的问题。各个栅格内的数据差异很大,若以线程作为处理栅格的基本单元,则将出现严重的负载不均衡问题。对此,本书采用一个warp处理一个栅格的策略来处理栅格数据,再对warp内的线程的任务进行重新分配,使得warp内任务量大小相同来解决负载不均衡问题。栅格内数据都与结果数据有关,即数据之间有依赖关系,此时原有的CUDA编程技术并不能解决该问题。本书采用了shuffle技术来解决该问题,即通过warp内的0号线程来获取栅格内部数据量,其次通过_shfl()函数将其将传到warp内的其他31个线程的寄存器上,如图8-24所示。
用_shfl_down()函数来求极值的具体算法流程如图8-25所示。本书通过上述方法来取代一个线程处理一个栅格所需的单指令序列,增加有效带宽和减少延迟。对于栅格数据来说,因为许多栅格内的数据量并不超过32(warpsize的大小),所以在该并行模式下,只需访问一次全局内存,即可将此栅格的数据读入寄存器,从而避免了多次访问该栅格的数据,减少了访问消耗。
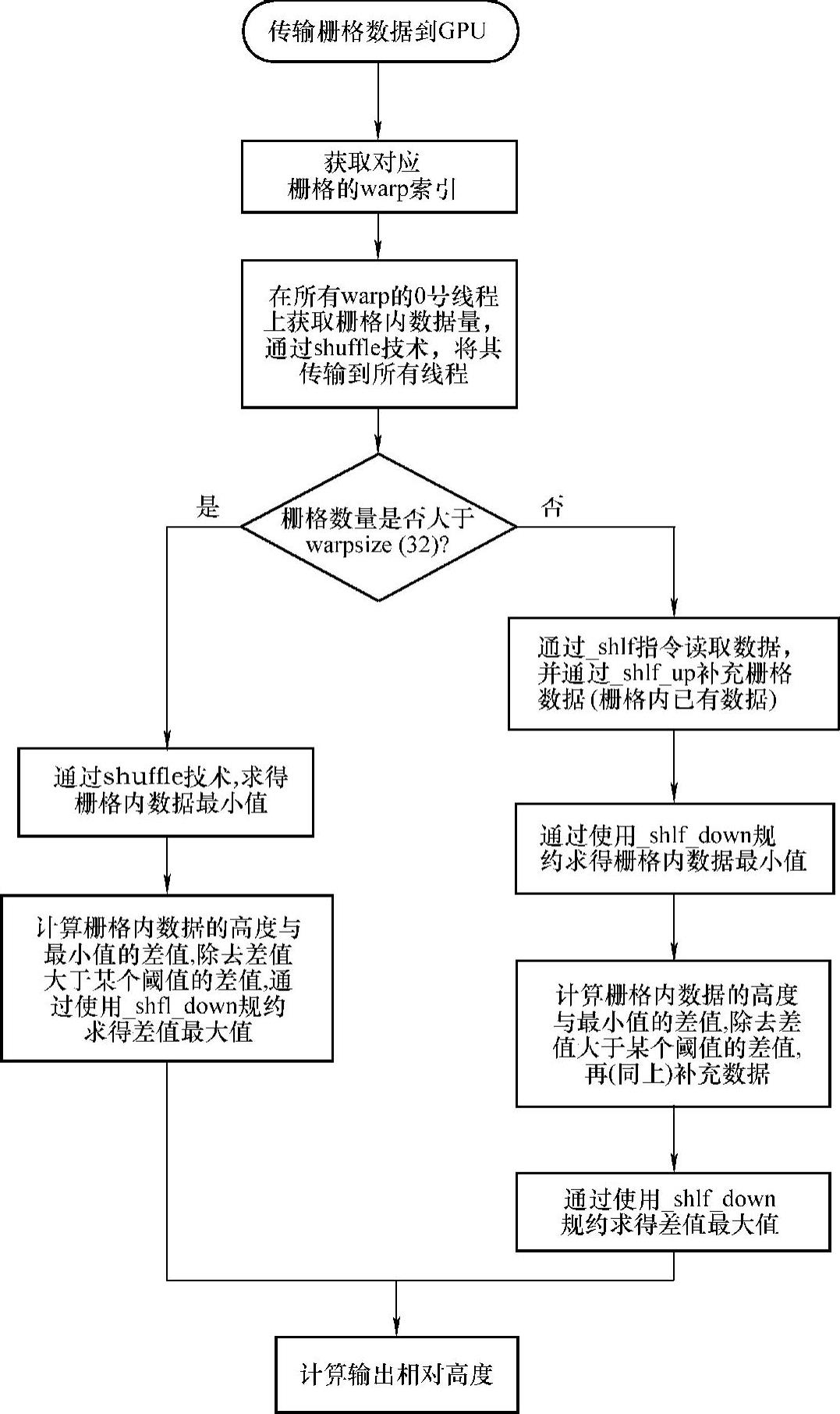
图8-23 warp处理栅格流程图
3.数据本地化
数据本地化是指将数据从片外内存(local memory、global memory、constant memory和texture memory)转移到片内(register、shared memory),并实现数据共享,以此来减少片外内存访存的依赖。因此,可以通过数据本地化,减少对global memory的访存依赖,从而提高算法性能。
就栅格处理程序而言,在warp处理完一个栅格数据后,其结果数据只有一个,若直接访问全局内存,那么一个block内将会发生多次访存请求,增加访存开销,大大影响处理性能。因此,本书采用数据本地化的方法,即每个warp在处理完一个栅格数据后,并不急于将结果写回全局内存,而是将结果数据放入shared memo-ry上。在该block所有的warp处理完后,启用第0个warp一次性将所有结果数据存入全局内存中,从而减少对全局内存的访问,减少对访存带宽的依赖。其具体流程如图8-26所示。

图8-24 用shfl()函数获取栅格内部数据量信息
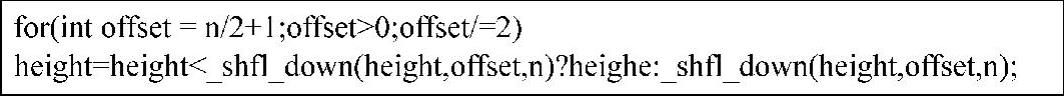
图8-25 用shfldown()求极值

图8-26 数据本地化流程图
免责声明:以上内容源自网络,版权归原作者所有,如有侵犯您的原创版权请告知,我们将尽快删除相关内容。






